

Efterhånden som æraen med generativ AI skrider frem, har en lang række virksomheder meldt sig på banen, og selve modellerne er blevet mere og mere forskellige.
Midt i dette AI-boom har mange virksomheder udråbt deres modeller som 'open source', men hvad betyder det egentlig i praksis?
Begrebet open source har sine rødder i softwareudviklingsmiljøet. Traditionel open source-software gør kildekoden frit tilgængelig for alle, så de kan se, ændre og distribuere den.
I bund og grund er open source en samarbejdsbaseret videndelingsenhed, der drives af softwareinnovation, som har ført til udviklinger som Linux-operativsystemet, Firefox-webbrowseren og programmeringssproget Python.
Men det er langt fra ligetil at anvende open source-etikken på nutidens massive AI-modeller.
Disse systemer trænes ofte på store datasæt, der indeholder terabytes eller petabytes af data, ved hjælp af komplekse neurale netværksarkitekturer med milliarder af parametre.
De nødvendige computerressourcer koster millioner af dollars, der er mangel på talent, og intellektuel ejendom er ofte godt beskyttet.
Det kan vi se i OpenAI, der, som navnet antyder, tidligere var et AI-forskningslaboratorium, der i høj grad var dedikeret til den åbne forskningsetos.
Men det Ethos blev hurtigt udhulet da virksomheden lugtede pengene og havde brug for at tiltrække investeringer for at nå sine mål.
Hvorfor ikke? Fordi open source-produkter ikke er rettet mod profit, og AI er dyrt og værdifuldt.
Men efterhånden som generativ AI er eksploderet, frigiver virksomheder som Mistral, Meta, BLOOM og xAI open source-modeller for at fremme forskningen og samtidig forhindre virksomheder som Microsoft og Google i at få for meget indflydelse.
Men hvor mange af disse modeller er i virkeligheden open source, og ikke kun af navn?
Afklaring af, hvor åbne open source-modeller egentlig er
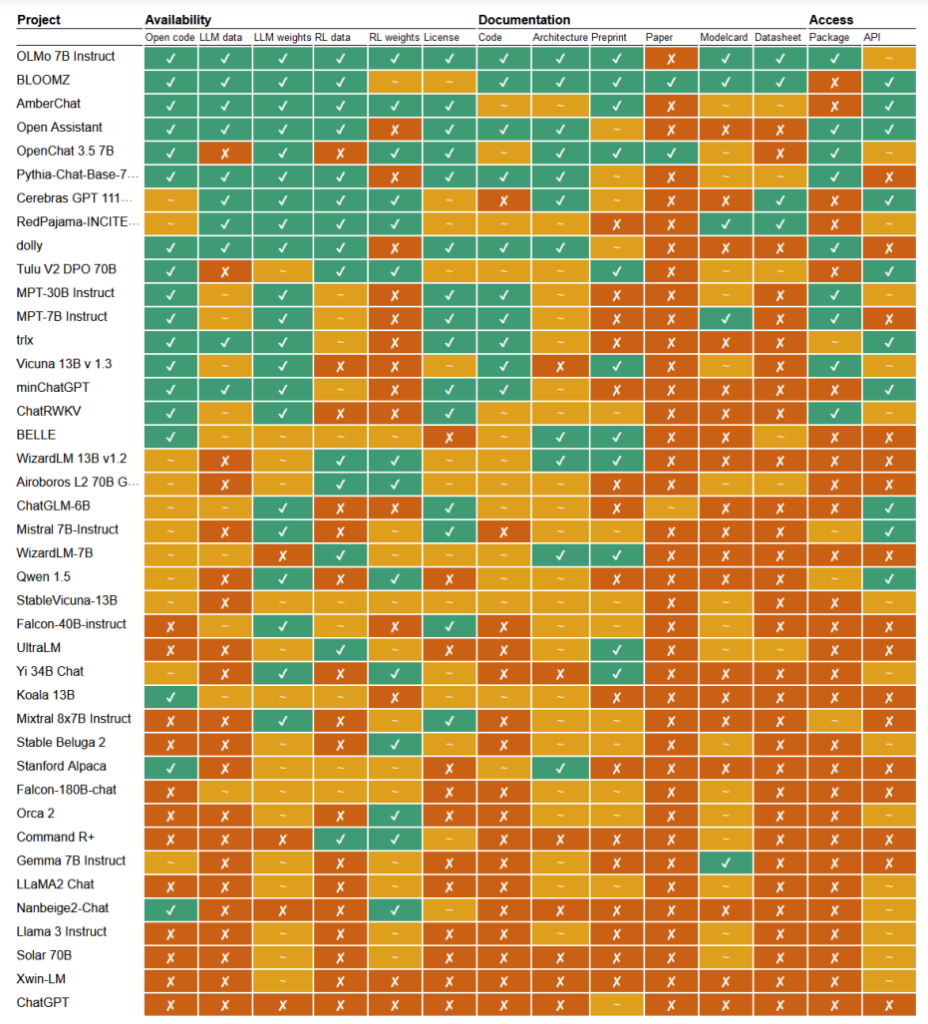
I en nylig undersøgelseForskerne Mark Dingemanse og Andreas Liesenfeld fra Radboud University i Holland har analyseret en lang række fremtrædende AI-modeller for at undersøge, hvor åbne de er. De undersøgte flere kriterier, f.eks. tilgængeligheden af kildekode, træningsdata, modelvægte, forskningsartikler og API'er.
For eksempel viste det sig, at Metas LLaMA-model og Googles Gemma blot var "åben vægt" - hvilket betyder, at den trænede model er offentligt frigivet til brug uden fuld gennemsigtighed i dens kode, træningsproces, data og finjusteringsmetoder.
I den anden ende af spektret fremhævede forskerne BLOOM, en stor flersproget model, der er udviklet af et samarbejde mellem over 1.000 forskere verden over, som et eksempel på ægte open source AI. Hvert element i modellen er frit tilgængeligt for inspektion og yderligere forskning.
Artiklen vurderede mere end 30 modeller (både tekst og billede), men de viser den enorme variation inden for dem, der hævder at være open source:
- BloomZ (BigScience): Fuldt åben på tværs af alle kriterier, herunder kode, træningsdata, modelvægte, forskningsartikler og API. Fremhævet som et eksempel på ægte open source AI.
- OLMo (Allen Institute for AI): Åben kode, træningsdata, vægte og forskningsartikler. API'en er kun delvist åben.
- Mistral 7B-Instruct (Mistral AI): Åbne modelvægte og API. Kode og forskningsartikler er kun delvist åbne. Træningsdata er ikke tilgængelige.
- Orca 2 (Microsoft): Delvist åbne modelvægte og forskningsartikler. Kode, træningsdata og API lukket.
- Gemma 7B instruerer (Google): Delvis åben kode og vægte. Træningsdata, forskningsartikler og API lukket. Beskrevet som "åben" af Google snarere end "open source".
- Llama 3 Instruct (Meta): Delvist åbne vægte. Kode, træningsdata, forskningsartikler og API lukket. Et eksempel på en "åben vægt"-model uden større gennemsigtighed.
Mangel på gennemsigtighed
Den manglende gennemsigtighed omkring AI-modeller, især dem, der er udviklet af store teknologivirksomheder, giver anledning til alvorlige bekymringer om ansvarlighed og tilsyn.
Uden fuld adgang til modellens kode, træningsdata og andre nøglekomponenter bliver det ekstremt udfordrende at forstå, hvordan disse modeller fungerer og træffer beslutninger. Det gør det vanskeligt at identificere og håndtere potentielle bias, fejl eller misbrug af ophavsretligt beskyttet materiale.
Krænkelse af ophavsretten i AI-træningsdata er et godt eksempel på de problemer, der opstår som følge af denne mangel på gennemsigtighed. Mange proprietære AI-modeller, såsom GPT-3.5/4/40/Claude 3/Gemini, er sandsynligvis trænet på ophavsretligt beskyttet materiale.
Men da træningsdata holdes under lås og slå, er det næsten umuligt at identificere specifikke data i dette materiale.
The New York Times's nylig retssag mod OpenAI viser konsekvenserne af denne udfordring i den virkelige verden. OpenAI beskyldte NYT for at bruge prompt engineering-angreb til at afsløre træningsdata og lokke ChatGPT til at gengive sine artikler ordret og dermed bevise, at OpenAI's træningsdata indeholder ophavsretligt beskyttet materiale.
"The Times betalte nogen for at hacke OpenAI's produkter," sagde OpenAI.
Som svar sagde Ian Crosby, NYT's ledende juridiske rådgiver: "Det, som OpenAI på bizar vis betegner som 'hacking', er simpelthen at bruge OpenAI's produkter til at lede efter beviser for, at de har stjålet og gengivet The Times' ophavsretligt beskyttede værker. Og det er præcis, hvad vi fandt."
Det er faktisk kun ét eksempel fra en stor stak retssager, der i øjeblikket er blokeret delvist på grund af AI-modellernes uigennemsigtige og uigennemtrængelige natur.
Dette er kun toppen af isbjerget. Uden robuste foranstaltninger for gennemsigtighed og ansvarlighed risikerer vi en fremtid, hvor uforklarlige AI-systemer træffer beslutninger, der har stor indflydelse på vores liv, økonomi og samfund, men som ikke bliver undersøgt.
Opfordrer til åbenhed
Der har været opfordringer til virksomheder som Google og OpenAI om at give adgang til deres modellers indre arbejde med henblik på sikkerhedsevaluering.
Men sandheden er, at selv AI-virksomheder ikke helt forstår, hvordan deres modeller fungerer.
Dette kaldes "black box"-problemet, som opstår, når man forsøger at fortolke og forklare modellens specifikke beslutninger på en måde, der er forståelig for mennesker.
For eksempel kan en udvikler vide, at en deep learning-model er nøjagtig og fungerer godt, men de kan have svært ved at finde ud af, præcis hvilke funktioner modellen bruger til at træffe sine beslutninger.
Anthropic, som har udviklet Claude-modellerne, har for nylig udførte et eksperiment for at identificere, hvordan Claude 3 Sonnet fungerer, og forklarer: "Vi behandler for det meste AI-modeller som en sort boks: noget går ind, og der kommer et svar ud, og det er ikke klart, hvorfor modellen gav netop det svar i stedet for et andet. Det gør det svært at stole på, at disse modeller er sikre: Hvis vi ikke ved, hvordan de fungerer, hvordan kan vi så vide, at de ikke giver skadelige, forudindtagede, usande eller på anden måde farlige svar? Hvordan kan vi stole på, at de er sikre og pålidelige?"
Det er faktisk en ret bemærkelsesværdig indrømmelse, at skaberen af en teknologi ikke forstår sit produkt i AI-æraen.
Dette antropiske eksperiment illustrerede, at det er en usædvanlig vanskelig opgave at forklare outputs objektivt. Faktisk vurderede Anthropic, at det ville kræve mere computerkraft at "åbne den sorte boks" end at træne selve modellen!
Udviklere forsøger aktivt at bekæmpe black box-problemet gennem forskning som "Explainable AI" (XAI), der har til formål at udvikle teknikker og værktøjer til at gøre AI-modeller mere gennemsigtige og fortolkelige.
XAI-metoder forsøger at give indsigt i modellens beslutningsproces, fremhæve de mest indflydelsesrige funktioner og generere forklaringer, der kan læses af mennesker. XAI er allerede blevet anvendt på modeller, der er implementeret i high-stakes applikationer såsom lægemiddeludviklinghvor det at forstå, hvordan en model fungerer, kan være afgørende for sikkerheden.
Open source-initiativer er afgørende for XAI og anden forskning, der forsøger at trænge ind i den sorte boks og skabe gennemsigtighed i AI-modeller.
Uden adgang til modellens kode, træningsdata og andre nøglekomponenter kan forskere ikke udvikle og teste teknikker til at forklare, hvordan AI-systemer virkelig fungerer, og identificere specifikke data, som de er trænet på.
Regler kan forvirre open source-situationen yderligere
Den Europæiske Unions Nyligt vedtaget AI-lov er klar til at indføre nye regler for AI-systemer med bestemmelser, der specifikt omhandler open source-modeller.
I henhold til loven vil open source-modeller til generelle formål op til en vis størrelse være undtaget fra omfattende krav om gennemsigtighed.
Men som Dingemanse og Liesenfeld påpeger i deres undersøgelse, er den nøjagtige definition af "open source AI" i henhold til AI-loven stadig uklar og kan blive et stridspunkt.
Loven definerer i øjeblikket open source-modeller som dem, der frigives under en "fri og åben" licens, der giver brugerne mulighed for at ændre modellen. Alligevel specificerer den ikke krav om adgang til træningsdata eller andre nøglekomponenter.
Denne tvetydighed giver plads til fortolkning og potentiel lobbyisme fra virksomhedsinteresser. Forskerne advarer om, at en finpudsning af open source-definitionen i AI-loven "sandsynligvis vil udgøre et enkelt trykpunkt, der vil blive mål for virksomhedslobbyer og store virksomheder."
Der er en risiko for, at uden klare, robuste kriterier for, hvad der udgør ægte open source AI, kan reglerne utilsigtet skabe smuthuller eller incitamenter for virksomheder til at engagere sig i "open-washing" - at hævde åbenhed for de juridiske og PR-mæssige fordele, mens de stadig holder vigtige aspekter af deres modeller beskyttede.
Desuden betyder den globale karakter af AI-udvikling, at forskellige regler på tværs af jurisdiktioner kan komplicere landskabet yderligere.
Hvis store AI-producenter som USA og Kina indfører forskellige tilgange til krav om åbenhed og gennemsigtighed, kan det føre til et fragmenteret økosystem, hvor graden af åbenhed varierer meget afhængigt af, hvor en model stammer fra.
Undersøgelsens forfattere understreger behovet for, at lovgiverne arbejder tæt sammen med det videnskabelige samfund og andre interessenter for at sikre, at alle open source-bestemmelser i AI-lovgivningen er baseret på en dyb forståelse af teknologien og principperne om åbenhed.
Som Dingemanse og Liesenfeld konkluderer i en diskussion med naturen"Det er rimeligt at sige, at begrebet open source vil få en hidtil uset juridisk vægt i de lande, der er omfattet af EU's AI Act."
Hvordan dette udspiller sig i praksis, vil få stor betydning for den fremtidige retning for AI-forskning og -anvendelse.



