

Google DeepMind-forskere udviklede NATURAL PLAN, et benchmark til evaluering af LLM'ers evne til at planlægge opgaver i den virkelige verden baseret på naturlige sprogbeskeder.
Den næste udvikling inden for AI er at få den til at forlade en chatplatform og påtage sig agentroller for at udføre opgaver på tværs af platforme på vores vegne. Men det er sværere, end det lyder.
Planlægningsopgaver som at planlægge et møde eller sammensætte en ferieplan kan virke enkle for os. Mennesker er gode til at ræsonnere sig gennem flere trin og forudsige, om en fremgangsmåde vil føre til det ønskede mål eller ej.
Du synes måske, det er nemt, men selv de bedste AI-modeller har svært ved at planlægge. Kan vi benchmarke dem for at se, hvilken LLM der er bedst til at planlægge?
NATURAL PLAN-benchmarket tester LLM'er på 3 planlægningsopgaver:
- Planlægning af rejse - Planlægning af en rejseplan under fly- og destinationsbegrænsninger
- Planlægning af møder - Planlægning af møder med flere venner på forskellige steder
- Planlægning af kalender - Planlægning af arbejdsmøder mellem flere personer på baggrund af eksisterende tidsplaner og forskellige begrænsninger
Eksperimentet begyndte med få-skud-prompter, hvor modellerne fik 5 eksempler på prompter og tilsvarende korrekte svar. Derefter blev de bedt om at planlægge opgaver af varierende sværhedsgrad.
Her er et eksempel på en opfordring og en løsning, der blev givet som et eksempel til modellerne:

Resultater
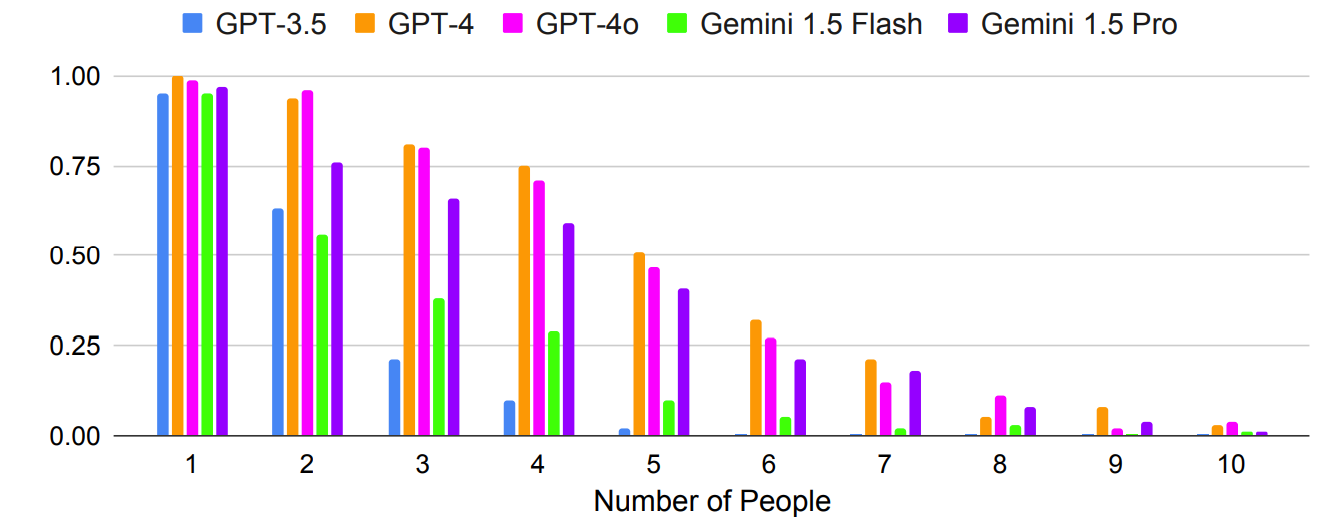
Forskerne testede GPT-3.5, GPT-4, GPT-4o, Gemini 1.5 Flash og Gemini 1.5 ProIngen af dem klarede sig særlig godt i disse tests.
Resultaterne må dog være faldet i god jord på DeepMind-kontoret, da Gemini 1.5 Pro kom ud på toppen.

Som forventet blev resultaterne eksponentielt dårligere med mere komplekse opgaver, hvor antallet af personer eller byer blev øget. Se for eksempel, hvor hurtigt præcisionen faldt, da der blev tilføjet flere personer til mødeplanlægningstesten.
Kan multi-shot prompting resultere i forbedret præcision? Forskningsresultaterne viser, at det kan det, men kun hvis modellen har et stort nok kontekstvindue.
Gemini 1.5 Pros større kontekstvindue gør det muligt at udnytte flere eksempler i konteksten end GPT-modellerne.
Forskerne fandt ud af, at en forøgelse af antallet af skud fra 1 til 800 i Trip Planning forbedrer nøjagtigheden af Gemini Pro 1.5 fra 2,7% til 39,9%.
Avisen "Disse resultater viser det lovende ved planlægning i kontekst, hvor de lange kontekstfunktioner gør det muligt for LLM'er at udnytte yderligere kontekst til at forbedre planlægningen."
Et mærkeligt resultat var, at GPT-4o var virkelig dårlig til rejseplanlægning. Forskerne fandt ud af, at den havde svært ved at "forstå og respektere begrænsningerne i flyforbindelser og rejsedatoer."
Et andet mærkeligt resultat var, at selvkorrektion førte til et betydeligt fald i modellernes ydeevne på tværs af alle modeller. Når modellerne blev bedt om at tjekke deres arbejde og foretage rettelser, lavede de flere fejl.
Interessant nok led de stærkere modeller, såsom GPT-4 og Gemini 1.5 Pro, større tab end GPT-3.5, når de selvkorrigerede.
Agentisk AI er et spændende perspektiv, og vi ser allerede nogle praktiske anvendelser i Microsoft Copilot agenter.
Men resultaterne af NATURAL PLAN-benchmarkprøverne viser, at der er et stykke vej endnu, før AI kan håndtere mere kompleks planlægning.
DeepMind-forskerne konkluderede, at "NATURAL PLAN er meget svær at løse for state-of-the-art-modeller."
Det ser ud til, at AI ikke vil erstatte rejsebureauer og personlige assistenter helt endnu.



