

Anthropic forskere med succes identificeret millioner af koncepter inden for Claude Sonnet, en af deres avancerede LLM'er.
AI-modeller betragtes ofte som sorte bokse, hvilket betyder, at man ikke kan 'se' ind i dem for at forstå præcis, hvordan de fungerer.
Når du giver en LLM et input, genererer den et svar, men ræsonnementet bag dens valg er ikke klart.
Dit input går ind, og outputtet kommer ud - og selv AI-udviklerne forstår ikke helt, hvad der sker inde i den 'kasse'.
Neurale netværk skaber deres egne interne repræsentationer af information, når de mapper input til output under datatræning. Byggestenene i denne proces, kaldet "neuronaktiveringer", repræsenteres af numeriske værdier.
Hvert begreb er fordelt på flere neuroner, og hver neuron bidrager til at repræsentere flere begreber, hvilket gør det vanskeligt at kortlægge begreber direkte til individuelle neuroner.
Dette er stort set analogt med vores menneskelige hjerner. Ligesom vores hjerner behandler sanseindtryk og genererer tanker, adfærd og hukommelse, er de milliarder, endda billioner, af processer bag disse funktioner stadig primært ukendte for videnskaben.
Anthropic's undersøgelse forsøger at se ind i AI's sorte boks med en teknik, der kaldes "ordbogsindlæring".
Det indebærer, at man nedbryder komplekse mønstre i en AI-model til lineære byggesten eller "atomer", som giver intuitiv mening for mennesker.
Kortlægning af LLM'er med ordbogsindlæring
I oktober 2023, Anthropic anvendte denne metode på en lille "legetøjs"-sprogmodel og fandt sammenhængende træk, der svarede til begreber som store bogstaver, DNA-sekvenser, efternavne i citater, matematiske navneord eller funktionsargumenter i Python-kode.
Denne seneste undersøgelse opskalerer teknikken, så den i dette tilfælde fungerer med nutidens større AI-sprogmodeller, Anthropic's Claude 3 Sonnet.
Her er en trin-for-trin gennemgang af, hvordan undersøgelsen fungerede:
Identificering af mønstre med ordbogsindlæring
Anthropic brugte ordbogsindlæring til at analysere neuronaktiveringer på tværs af forskellige sammenhænge og identificere fælles mønstre.
Ordbogsindlæring grupperer disse aktiveringer i et mindre sæt af meningsfulde "funktioner", der repræsenterer begreber på højere niveau, som modellen har lært.
Ved at identificere disse funktioner kan forskere bedre forstå, hvordan modellen behandler og repræsenterer information.
Udtræk af funktioner fra det midterste lag
Forskerne fokuserede på det midterste lag af Claude 3.0 Sonnet, som fungerer som et kritisk punkt i modellens behandlingspipeline.
Ved at anvende ordbogsindlæring på dette lag udtrækkes millioner af funktioner, der indfanger modellens interne repræsentationer og indlærte begreber på dette stadie.
Ved at udtrække funktioner fra det midterste lag kan forskere undersøge modellens forståelse af information efter den har behandlet inputtet før der genererer det endelige output.
Opdagelse af forskellige og abstrakte begreber
De ekstraherede funktioner afslørede en bred vifte af begreber, der var lært af Claudefra konkrete enheder som byer og mennesker til abstrakte begreber relateret til videnskabelige områder og programmeringssyntaks.
Interessant nok viste det sig, at funktionerne var multimodale og reagerede på både tekstlige og visuelle input, hvilket tyder på, at modellen kan lære og repræsentere begreber på tværs af forskellige modaliteter.
Derudover tyder de flersprogede funktioner på, at modellen kan forstå begreber, der er udtrykt på forskellige sprog.

Analysere organiseringen af koncepter
For at forstå, hvordan modellen organiserer og relaterer forskellige begreber, analyserede forskerne ligheden mellem funktioner baseret på deres aktiveringsmønstre.
De opdagede, at funktioner, der repræsenterede relaterede begreber, havde en tendens til at gruppere sig sammen. F.eks. udviste funktioner, der var forbundet med byer eller videnskabelige discipliner, større lighed med hinanden end med funktioner, der repræsenterede ikke-relaterede koncepter.
Det tyder på, at modellens interne organisering af begreber til en vis grad stemmer overens med menneskelige intuitioner om begrebsrelationer.
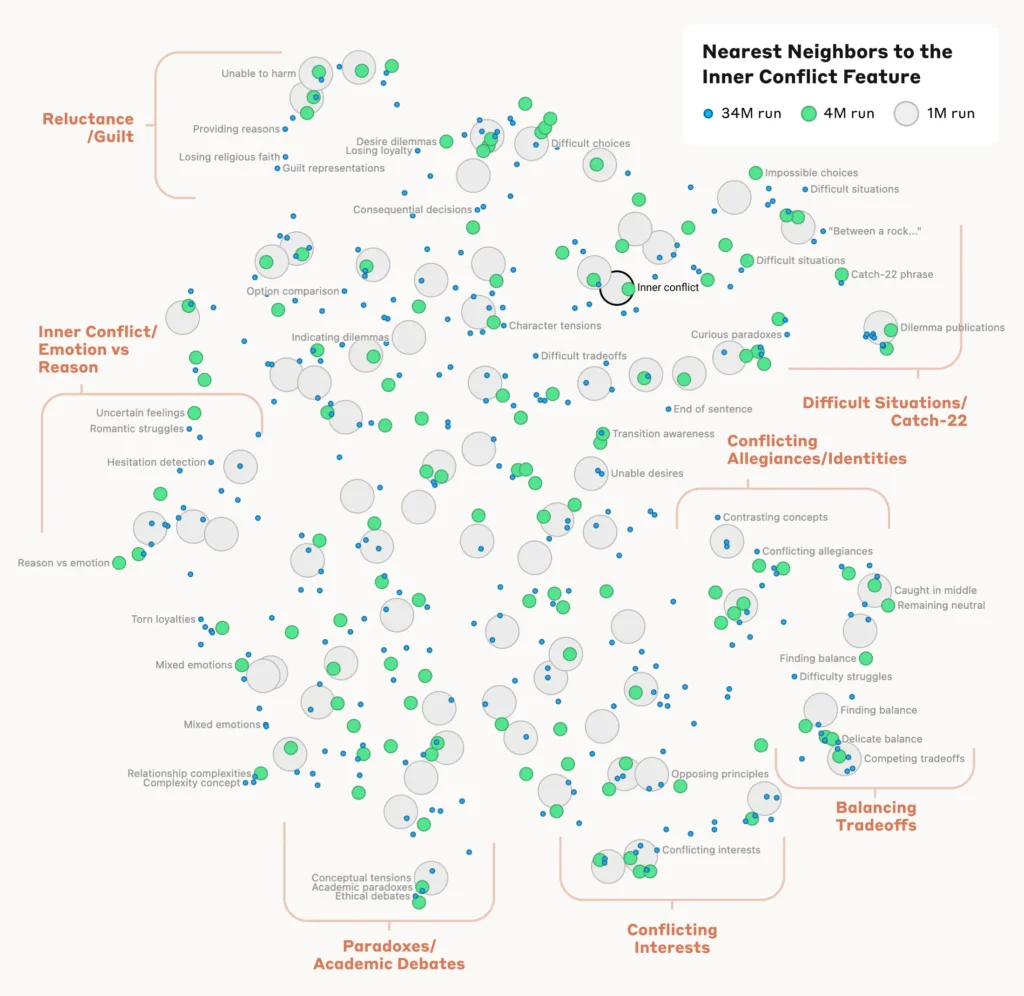
Bekræftelse af funktionerne
For at bekræfte, at de identificerede funktioner har direkte indflydelse på modellens adfærd og output, udførte forskerne eksperimenter med "funktionsstyring".
Det indebar, at man selektivt forstærkede eller undertrykte aktiveringen af specifikke funktioner under modellens behandling og observerede indvirkningen på dens svar.
Ved at manipulere individuelle funktioner kunne forskerne etablere en direkte forbindelse mellem individuelle funktioner og modellens adfærd. Hvis man f.eks. forstærkede en funktion, der var relateret til en bestemt by, fik det modellen til at generere by-biased output, selv i irrelevante sammenhænge.
Læs hele undersøgelsen her.
Hvorfor fortolkbarhed er afgørende for AI-sikkerhed
Anthropic's forskning er grundlæggende relevant for AI-fortolkning og i forlængelse heraf sikkerhed.
At forstå, hvordan LLM'er behandler og repræsenterer information, hjælper forskere med at forstå og mindske risici. Det lægger grunden til at udvikle mere gennemsigtige og forklarlige AI-systemer.
Som Anthropic forklarer: "Vi håber, at vi og andre kan bruge disse opdagelser til at gøre modeller mere sikre. For eksempel kan det være muligt at bruge de teknikker, der er beskrevet her, til at overvåge AI-systemer for visse former for farlig adfærd (såsom at bedrage brugeren), til at styre dem i retning af ønskværdige resultater (debiasing) eller til helt at fjerne visse farlige emner."
En større forståelse af AI's adfærd bliver altafgørende, når de bliver allestedsnærværende i kritiske beslutningsprocesser inden for områder som sundhed, finans og strafferet. Det hjælper også med at afdække den grundlæggende årsag til skævhedhallucinationer og anden uønsket eller uforudsigelig adfærd.
For eksempel kan en nylig undersøgelse fra universitetet i Bonn afslørede, hvordan grafneurale netværk (GNN'er), der bruges til lægemiddelopdagelse, i høj grad er afhængige af at huske ligheder fra træningsdata i stedet for virkelig at lære komplekse nye kemiske interaktioner.
Det gør det svært at forstå, hvordan disse modeller præcist finder frem til nye interessante forbindelser.
Sidste år blev Den britiske regering forhandlede med store tech-giganter som OpenAI og DeepMindsom ønsker adgang til deres AI-systemers interne beslutningsprocesser.
Regulering som den EU's lov om kunstig intelligens vil presse AI-virksomheder til at være mere gennemsigtige, selv om forretningshemmeligheder ser ud til at forblive under lås og slå.
Anthropic's forskning giver et glimt af, hvad der er inde i kassen ved at 'kortlægge' information på tværs af modellen.
Men sandheden er, at disse modeller er så omfattende, at de ved at Anthropic"Vi mener, at det er ret sandsynligt, at vi mangler en hel del, og at hvis vi ville have alle funktionerne - i alle lag! - ville vi være nødt til at bruge meget mere computerkraft end den samlede computerkraft, der er nødvendig for at træne de underliggende modeller."
Det er en interessant pointe - reverse engineering af en model er mere beregningsmæssigt kompleks end engineering af modellen i første omgang.
Det minder om enormt dyre neurovidenskabelige projekter som f.eks. Human Brain Project (HBP)som brugte milliarder på at kortlægge vores egne menneskelige hjerner, men som i sidste ende mislykkedes.
Undervurder aldrig, hvor meget der ligger inde i den sorte boks.



