

Stanford University udgav sin AI Index Report 2024, som bemærkede, at AI's hurtige fremskridt gør benchmark-sammenligninger med mennesker stadig mindre relevante.
Den årsberetning giver et omfattende indblik i tendenser og status for AI-udviklingen. Rapporten siger, at AI-modeller forbedres så hurtigt nu, at de benchmarks, vi bruger til at måle dem, i stigende grad bliver irrelevante.
Mange branche-benchmarks sammenligner AI-modeller med, hvor gode mennesker er til at udføre opgaver. Massive Multitask Language Understanding (MMLU)-benchmarken er et godt eksempel.
Den bruger multiple choice-spørgsmål til at evaluere LLM'er på tværs af 57 fag, herunder matematik, historie, jura og etik. MMLU har været det foretrukne AI-benchmark siden 2019.
Den menneskelige baseline-score på MMLU er 89,8%, og tilbage i 2019 scorede den gennemsnitlige AI-model lidt over 30%. Bare 5 år senere blev Gemini Ultra den første model, der slog den menneskelige baseline med en score på 90,04%.
Rapporten bemærker, at nuværende "AI-systemer rutinemæssigt overgår menneskers præstationer på standardbenchmarks." Tendenserne i grafen nedenfor synes at indikere, at MMLU og andre benchmarks skal udskiftes.
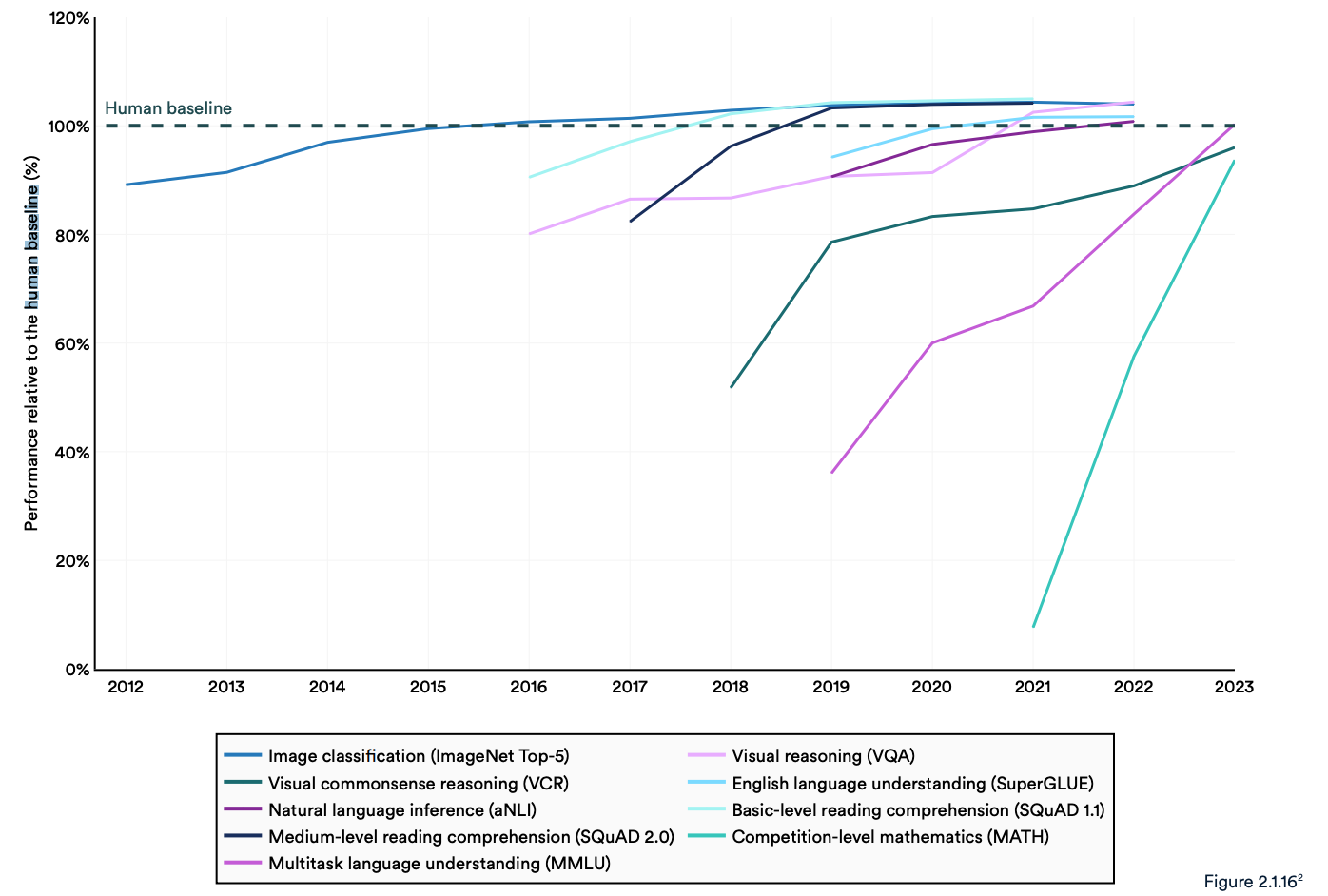
AI-modeller har nået præstationsmætning på etablerede benchmarks som ImageNet, SQuAD og SuperGLUE, så forskere udvikler mere udfordrende tests.
Et eksempel er Graduate-Level Google-Proof Q&A Benchmark (GPQA), som gør det muligt at benchmarke AI-modeller op mod virkelig kloge mennesker i stedet for gennemsnitlig menneskelig intelligens.
GPQA-testen består af 400 svære multiple choice-spørgsmål på kandidatniveau. Eksperter, der har eller er i gang med en ph.d., besvarer spørgsmålene korrekt i 65% af tilfældene.
I GPQA-papiret står der, at "højt kvalificerede ikke-ekspertvalidatorer kun opnår 34% nøjagtighed, når de bliver stillet spørgsmål uden for deres felt, på trods af at de i gennemsnit bruger over 30 minutter med ubegrænset adgang til internettet."
I sidste måned annoncerede Anthropic, at Claude 3 scorede lige under 60% med 5 skud CoT prompting. Vi får brug for et større benchmark.
Claude 3 får ~60% nøjagtighed på GPQA. Det er svært for mig at undervurdere, hvor svære disse spørgsmål er - bogstavelige ph.d.'er (inden for andre områder end spørgsmålene) med adgang til internettet får 34%.
Ph.d.-studerende *i samme domæne* (også med internetadgang!) får 65% - 75% nøjagtighed. https://t.co/ARAiCNXgU9 pic.twitter.com/PH8J13zIef
- david rein (@idavidrein) 4. marts 2024
Menneskelige evalueringer og sikkerhed
Rapporten bemærkede, at AI stadig står over for betydelige problemer: "Den kan ikke håndtere fakta på en pålidelig måde, udføre komplekse ræsonnementer eller forklare sine konklusioner."
Disse begrænsninger bidrager til en anden egenskab ved AI-systemet, som ifølge rapporten er dårligt målt; AI-sikkerhed. Vi har ikke effektive benchmarks, der giver os mulighed for at sige: "Denne model er mere sikker end den anden."
Det skyldes dels, at det er svært at måle, og dels at "AI-udviklere mangler gennemsigtighed, især med hensyn til offentliggørelse af træningsdata og metoder."
Rapporten bemærkede, at en interessant tendens i branchen er at crowd-source menneskelige evalueringer af AI-præstationer i stedet for benchmark-tests.
Det er svært at rangordne en models billedæstetik eller prosa med en test. Derfor siger rapporten, at "benchmarking langsomt er begyndt at gå i retning af at inkorporere menneskelige evalueringer som Chatbot Arena Leaderboard i stedet for computeriserede ranglister som ImageNet eller SQuAD."
Når AI-modeller ser den menneskelige baseline forsvinde i bakspejlet, kan følelser i sidste ende afgøre, hvilken model vi vælger at bruge.
Tendenserne tyder på, at AI-modeller i sidste ende bliver klogere end os og sværere at måle. Snart vil vi måske sige: "Jeg ved ikke hvorfor, men jeg kan bare bedre lide den her."



