

Microsoft har lanceret Phi-3 Mini, en lille sprogmodel, som er en del af virksomhedens strategi om at udvikle lette, funktionsspecifikke AI-modeller.
Udviklingen af sprogmodeller har set stadig større parametre, træningsdatasæt og kontekstvinduer. Skalering af størrelsen på disse modeller gav mere kraftfulde funktioner, men det havde en pris.
Den traditionelle tilgang til at træne en LLM er at lade den bruge enorme mængder data, hvilket kræver enorme computerressourcer. Træning af en LLM som GPT-4 anslås f.eks. at have taget omkring 3 måneder og kostet over $21 millioner.
GPT-4 er en god løsning til opgaver, der kræver komplekse ræsonnementer, men overkill til enklere opgaver som oprettelse af indhold eller en salgs-chatbot. Det er som at bruge en schweizerkniv, når alt, hvad du har brug for, er en simpel brevåbner.
Med kun 3,8B parametre er Phi-3 Mini lille. Alligevel siger Microsoft, at det er en ideel, let og billig løsning til opgaver som at opsummere et dokument, uddrage indsigter fra rapporter og skrive produktbeskrivelser eller indlæg på sociale medier.
MMLU-benchmark-tallene viser, at Phi-3 Mini og de endnu ikke udgivne større Phi-modeller slår større modeller som Mistral 7B og Gemma 7B.
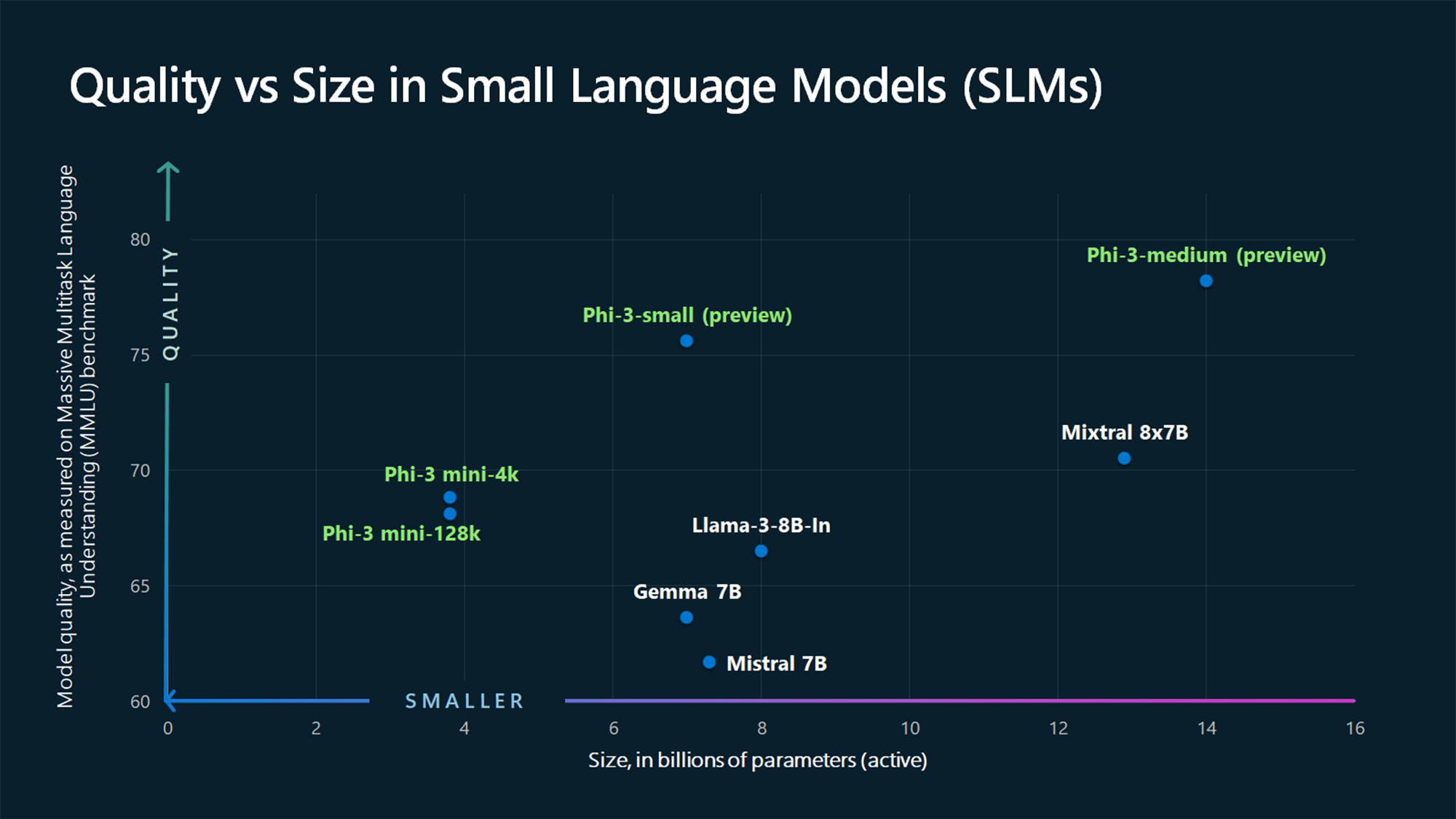
Microsoft siger, at Phi-3-small (7B parametre) og Phi-3-medium (14B parametre) vil være tilgængelige i Azure AI Model Catalog "inden længe".
Større modeller som GPT-4 er stadig guldstandarden, og vi kan nok forvente, at GPT-5 bliver endnu større.
SLM'er som Phi-3 Mini har nogle vigtige fordele, som større modeller ikke har. SLM'er er billigere at finjustere, kræver mindre beregning og kan køre på enheden, selv i situationer, hvor der ikke er internetadgang.
Implementering af en SLM på kanten resulterer i mindre ventetid og maksimal beskyttelse af personlige oplysninger, fordi der ikke er behov for at sende data frem og tilbage til skyen.
Her er Sebastien Bubeck, VP for GenAI-forskning hos Microsoft AI, med en demonstration af Phi-3 Mini. Den er superhurtig og imponerende af så lille en model at være.
phi-3 er her, og den er ... god :-).
Jeg har lavet en kort demo for at give dig en fornemmelse af, hvad phi-3-mini (3.8B) kan gøre. Hold øje med udgivelsen af åbne vægte og flere meddelelser i morgen tidlig!
(Og selvfølgelig ville dette ikke være komplet uden den sædvanlige tabel med benchmarks!) pic.twitter.com/AWA7Km59rp
- Sebastien Bubeck (@SebastienBubeck) 23. april 2024
Kuraterede syntetiske data
Phi-3 Mini er et resultat af at forkaste ideen om, at store mængder data er den eneste måde at træne en model på.
Sebastien Bubeck, Microsofts vicepræsident for generativ AI-forskning, spurgte: "I stedet for bare at træne på rå webdata, hvorfor leder du så ikke efter data af ekstremt høj kvalitet?"
Microsoft Researchs maskinlæringsekspert Ronen Eldan læste godnathistorier for sin datter, da han spekulerede på, om en sprogmodel kunne lære ved kun at bruge ord, som en 4-årig kunne forstå.
Det førte til et eksperiment, hvor de skabte et datasæt, der startede med 3.000 ord. Ved kun at bruge dette begrænsede ordforråd fik de en LLM til at skabe millioner af korte børnehistorier, som blev samlet i et datasæt kaldet TinyStories.
Forskerne brugte derefter TinyStories til at træne en ekstremt lille model med 10 mio. parametre, som efterfølgende var i stand til at generere "flydende fortællinger med perfekt grammatik".
De fortsatte med at iterere og skalere denne tilgang til generering af syntetiske data for at skabe mere avancerede, men omhyggeligt kuraterede og filtrerede syntetiske datasæt, som til sidst blev brugt til at træne Phi-3 Mini.
Resultatet er en lille model, der vil være mere overkommelig at køre, samtidig med at den giver en ydelse, der kan sammenlignes med GPT-3.5.
Mindre, men mere kompetente modeller vil få virksomheder til at bevæge sig væk fra blot at vælge store LLM'er som GPT-4 som standard. Vi kan også snart se løsninger, hvor en LLM håndterer de tunge løft, men uddelegerer enklere opgaver til letvægtsmodeller.



