

Googles DeepMind udgav Gecko, et nyt benchmark til omfattende evaluering af AI-tekst-til-billede-modeller (T2I).
I løbet af de sidste to år har vi set AI-billedgeneratorer som DALL-E og Midt på rejsen bliver gradvist bedre for hver version, der udgives.
Men beslutningen om, hvilken af de underliggende modeller, disse platforme bruger, der er bedst, har i høj grad været subjektiv og vanskelig at benchmarke.
Det er ikke så enkelt at påstå, at en model er "bedre" end en anden. Forskellige modeller udmærker sig i forskellige aspekter af billedgenereringen. En er måske god til tekstgengivelse, mens en anden er bedre til objektinteraktion.
En vigtig udfordring for T2I-modeller er at følge hver eneste detalje i prompten og få dem afspejlet nøjagtigt i det genererede billede.
Med Gecko er DeepMind Forskere har skabt en Benchmark der evaluerer T2I-modellernes evner på samme måde, som mennesker gør det.
Færdighedssæt
Forskerne definerede først et omfattende datasæt med færdigheder, der er relevante for T2I-generering. Disse omfatter bl.a. rumlig forståelse, handlingsgenkendelse og tekstgengivelse. De opdelte dem yderligere i mere specifikke underfærdigheder.
Under tekstgengivelse kan delfærdighederne f.eks. omfatte gengivelse af forskellige skrifttyper, farver eller tekststørrelser.
En LLM blev derefter brugt til at generere prompts til at teste T2I-modellens evne til en specifik færdighed eller delfærdighed.
Det gør det muligt for skaberne af en T2I-model at finde ud af, ikke bare hvilke færdigheder der er udfordrende, men også på hvilket kompleksitetsniveau en færdighed bliver udfordrende for deres model.
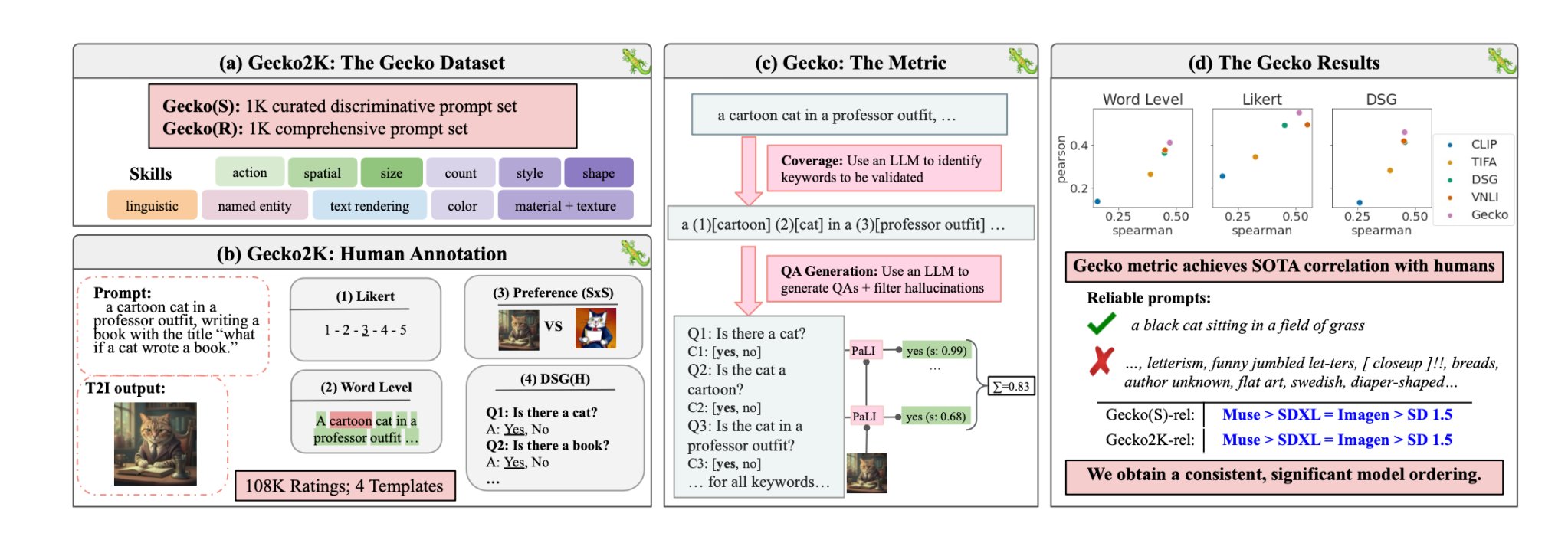
Menneskelig vs. automatisk evaluering
Gecko måler også, hvor præcist en T2I-model følger alle detaljerne i en prompt. Igen blev en LLM brugt til at isolere vigtige detaljer i hver input-prompt og derefter generere et sæt spørgsmål relateret til disse detaljer.
Disse spørgsmål kan både være enkle, direkte spørgsmål om synlige elementer i billedet (f.eks. "Er der en kat på billedet?") og mere komplekse spørgsmål, der tester forståelsen af scenen eller forholdet mellem objekter (f.eks. "Sidder katten over bogen?").
En VQA-model (Visual Question Answering) analyserer derefter det genererede billede og besvarer spørgsmålene for at se, hvor præcist T2I-modellen tilpasser sit output-billede til en input-prompt.
Forskerne indsamlede over 100.000 menneskelige kommentarer, hvor deltagerne vurderede et genereret billede ud fra, hvor godt billedet passede til specifikke kriterier.
Menneskene blev bedt om at overveje et specifikt aspekt af input-prompten og score billedet på en skala fra 1 til 5 baseret på, hvor godt det passede til prompten.
Ved at bruge de menneskeligt kommenterede evalueringer som guldstandard kunne forskerne bekræfte, at deres auto-eval-metrik "er bedre korreleret med menneskelige vurderinger end eksisterende metrikker for vores nye datasæt."
Resultatet er et benchmarking-system, der er i stand til at sætte tal på specifikke faktorer, der gør et genereret billede godt eller dårligt.
Gecko scorer i bund og grund outputbilledet på en måde, der ligger tæt op ad, hvordan vi intuitivt beslutter, om vi er tilfredse med det genererede billede eller ej.
Så hvad er den bedste tekst-til-billede-model?
I deres papirForskerne konkluderede, at Googles Muse-model slår Stable Diffusion 1.5 og SDXL på Gecko-benchmarket. De er måske forudindtagede, men tallene lyver ikke.



