

Forskere fra DeepMind og Stanford University har udviklet en AI-agent, der faktatjekker LLM'er og muliggør benchmarking af AI-modellers faktualitet.
Selv de bedste AI-modeller har stadig en tendens til at hallucinere til tider. Hvis du beder ChatGPT om at give dig fakta om et emne, jo længere svaret er, jo mere sandsynligt er det, at det indeholder nogle fakta, der ikke er sande.
Hvilke modeller er mere faktuelt nøjagtige end andre, når de genererer længere svar? Det er svært at sige, for indtil nu har vi ikke haft et benchmark til at måle faktualiteten i LLM's lange svar.
DeepMind brugte først GPT-4 til at skabe LongFact, et sæt af 2.280 prompts i form af spørgsmål relateret til 38 emner. Disse prompts fremkalder lange svar fra den LLM, der testes.
Derefter skabte de en AI-agent ved hjælp af GPT-3.5-turbo til at bruge Google til at verificere, hvor faktuelle de svar, LLM genererede, var. De kaldte metoden Search-Augmented Factuality Evaluator (SAFE).
SAFE opdeler først det lange svar fra LLM i individuelle fakta. Derefter sender den søgeanmodninger til Google Search og tager stilling til, om fakta er sande, baseret på oplysninger i de returnerede søgeresultater.
Her er et eksempel fra forskningsartikel.
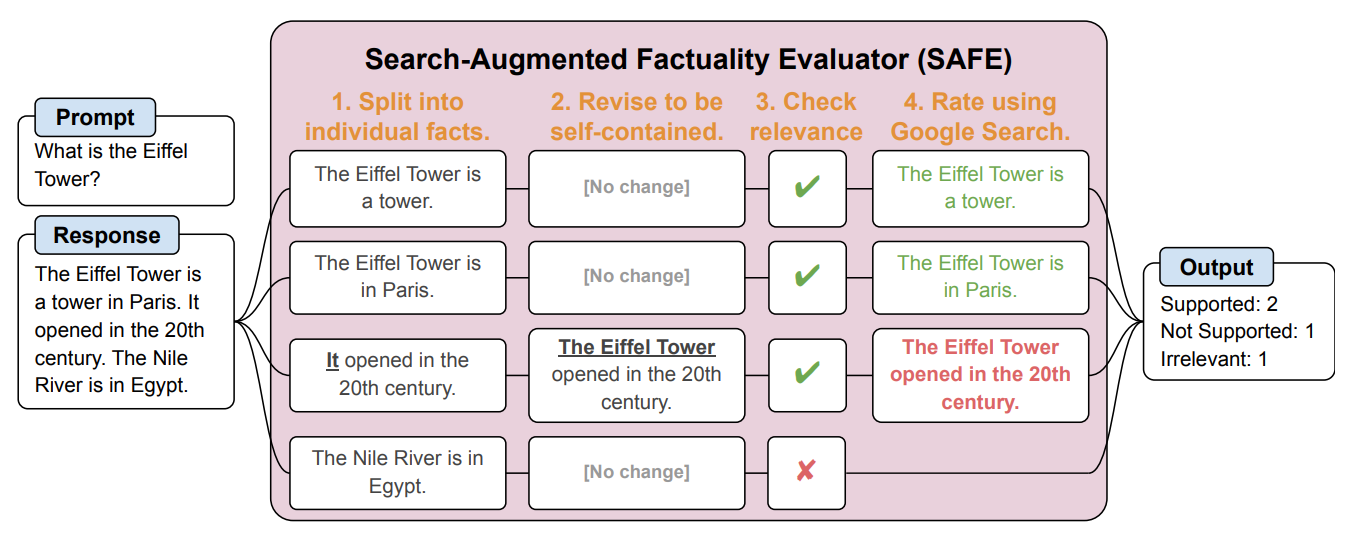
Forskerne siger, at SAFE opnår en "overmenneskelig præstation" sammenlignet med menneskelige kommentatorer, der udfører faktatjekket.
SAFE var enig med 72% af de menneskelige annotationer, og hvor den var uenig med mennesker, havde den ret i 76% af tilfældene. Det var også 20 gange billigere end crowdsourcede menneskelige kommentatorer. Så LLM'er er bedre og billigere faktatjekkere end mennesker.
Kvaliteten af svaret fra de testede LLM'er blev målt ud fra antallet af faktoider i svaret kombineret med, hvor faktuelle de enkelte faktoider var.
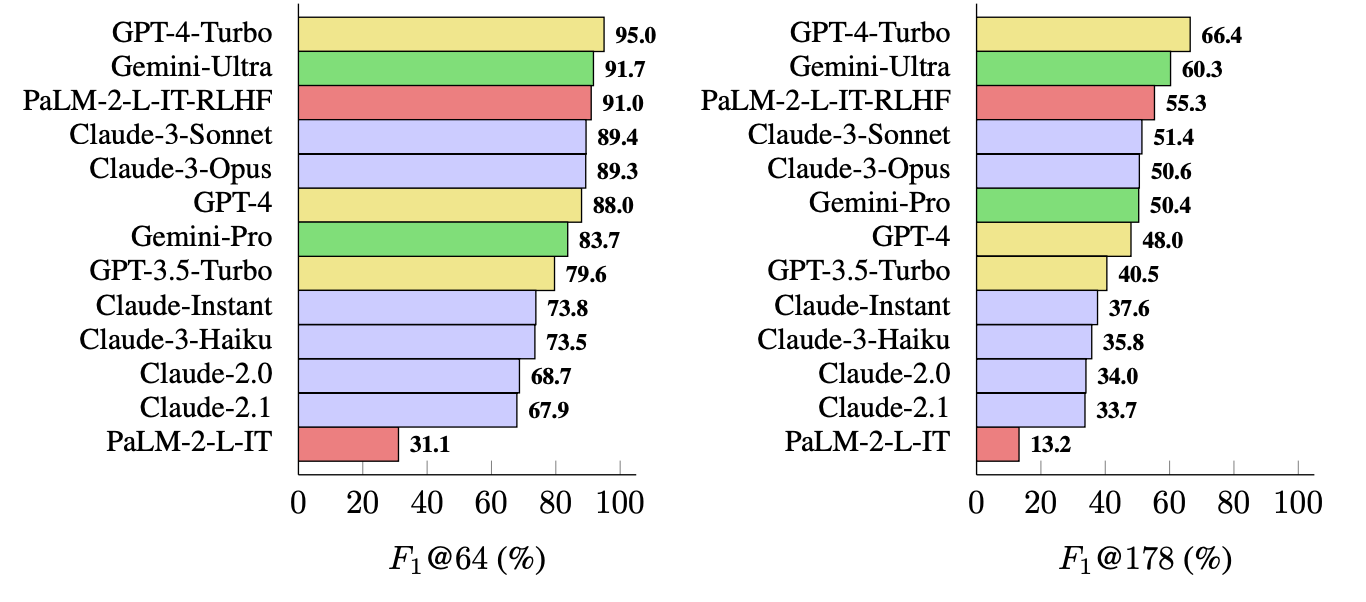
Den metrik, de brugte (F1@K), estimerer det menneskelige foretrukne "ideelle" antal fakta i et svar. Benchmark-testene brugte 64 som median for K og 178 som maksimum.
Kort sagt er F1@K et mål for "Gav svaret mig så mange fakta, som jeg ønskede?" kombineret med "Hvor mange af disse fakta var sande?".
Hvilken LLM er mest faktuel?
Forskerne brugte LongFact til at spørge 13 LLM'er fra Gemini, GPT, Claude og PaLM-2-familierne. Derefter brugte de SAFE til at evaluere, hvor faktuelle deres svar var.
GPT-4-Turbo topper listen som den mest faktuelle model, når der genereres lange svar. Den var tæt fulgt af Gemini-Ultra og PaLM-2-L-IT-RLHF. Resultaterne viste, at større LLM'er er mere faktuelle end mindre.
F1@K-beregningen ville sandsynligvis begejstre dataforskere, men for enkelhedens skyld viser disse benchmarkresultater, hvor faktuelle hver model er, når den returnerer gennemsnitlige længder og længere svar på spørgsmålene.
SAFE er en billig og effektiv måde at kvantificere LLM-langformsfakta på. Det er hurtigere og billigere end mennesker til faktatjek, men det afhænger stadig af sandfærdigheden af de oplysninger, som Google returnerer i søgeresultaterne.
DeepMind frigav SAFE til offentlig brug og foreslog, at det kunne hjælpe med at forbedre LLM-faktualiteten via bedre fortræning og finjustering. Det kan også gøre det muligt for en LLM at tjekke sine fakta, før den præsenterer sit output for en bruger.
OpenAI vil blive glade for at se, at forskning fra Google viser, at GPT-4 slår Gemini i endnu et benchmark.



