

Apples ingeniører har udviklet et AI-system, der løser komplekse referencer til enheder på skærmen og brugersamtaler. Den lette model kan være en ideel løsning til virtuelle assistenter på enheden.
Mennesker er gode til at løse referencer i samtaler med hinanden. Når vi bruger udtryk som "den nederste" eller "ham", forstår vi, hvad personen henviser til ud fra samtalens kontekst og de ting, vi kan se.
Det er meget sværere for en AI-model at gøre det. Multimodale LLM'er som GPT-4 er gode til at besvare spørgsmål om billeder, men de er dyre at træne og kræver et stort computeroverhead for at behandle hver forespørgsel om et billede.
Apples ingeniører valgte en anden tilgang til deres system, som de kaldte ReALM (Reference Resolution As Language Modeling). Avisen er værd at læse for at få flere detaljer om deres udviklings- og testproces.
ReALM bruger en LLM til at behandle samtale-, skærm- og baggrundsenheder (alarmer, baggrundsmusik), som udgør en brugers interaktion med en virtuel AI-agent.
Her er et eksempel på den slags interaktion, en bruger kan have med en AI-agent.
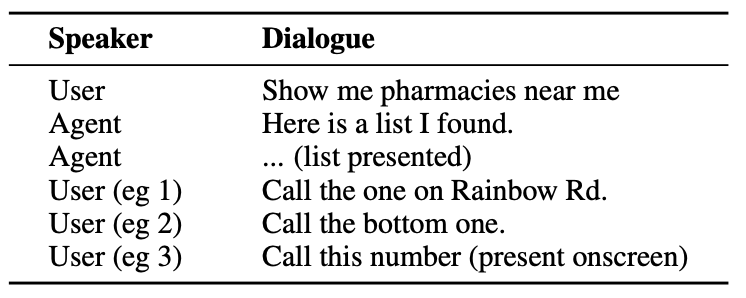
Agenten skal forstå samtaleenheder som det faktum, at når brugeren siger "den ene", henviser de til telefonnummeret til apoteket.
Den skal også forstå den visuelle kontekst, når brugeren siger "den nederste", og det er her, ReALM's tilgang adskiller sig fra modeller som GPT-4.
ReALM er afhængig af upstream-kodere til først at analysere elementerne på skærmen og deres positioner. ReALM rekonstruerer derefter skærmen i rent tekstuelle repræsentationer fra venstre mod højre og fra top til bund.
Enkelt sagt bruger den naturligt sprog til at opsummere brugerens skærm.
Når en bruger nu stiller et spørgsmål om noget på skærmen, behandler sprogmodellen tekstbeskrivelsen af skærmen i stedet for at skulle bruge en synsmodel til at behandle billedet på skærmen.
Forskerne skabte syntetiske datasæt med samtale-, skærm- og baggrundsenheder og testede ReALM og andre modeller for at afprøve deres effektivitet i forhold til at løse referencer i samtalesystemer.
ReALM's mindre version (80M parametre) klarede sig sammenligneligt med GPT-4, og den større version (3B parametre) klarede sig væsentligt bedre end GPT-4.
ReALM er en lille model sammenlignet med GPT-4. Dens overlegne referenceopløsning gør den til et ideelt valg til en virtuel assistent, der kan eksistere på enheden uden at gå på kompromis med ydeevnen.
ReALM fungerer ikke så godt med mere komplekse billeder eller nuancerede brugeranmodninger, men den kunne fungere godt som en virtuel assistent i bilen eller på enheden. Forestil dig, at Siri kunne "se" din iPhone-skærm og reagere på henvisninger til elementer på skærmen.
Apple har været lidt langsom ud af starthullerne, men nylige udviklinger som deres MM1-modellen og ReALM viser, at der sker meget bag lukkede døre.



