

Apple har endnu ikke officielt frigivet en AI-model, men en ny forskningsartikel giver et indblik i virksomhedens fremskridt med at udvikle modeller med avancerede multimodale funktioner.
Avisenmed titlen "MM1: Methods, Analysis & Insights from Multimodal LLM Pre-training", introducerer Apples familie af MLLM'er kaldet MM1.
MM1 viser imponerende evner inden for billedtekstning, visuel spørgsmålssvar (VQA) og udledning af naturligt sprog. Forskerne forklarer, at omhyggelige valg af billedtekstpar gjorde det muligt for dem at opnå overlegne resultater, især i læringsscenarier med få billeder.
Det, der adskiller MM1 fra andre MLLM'er, er dens overlegne evne til at følge instruktioner på tværs af flere billeder og til at ræsonnere over de komplekse scener, den bliver præsenteret for.
MM1-modellerne indeholder op til 30B parametre, hvilket er tre gange så meget som GPT-4V, den komponent, der giver OpenAI's GPT-4 sine synsfunktioner.
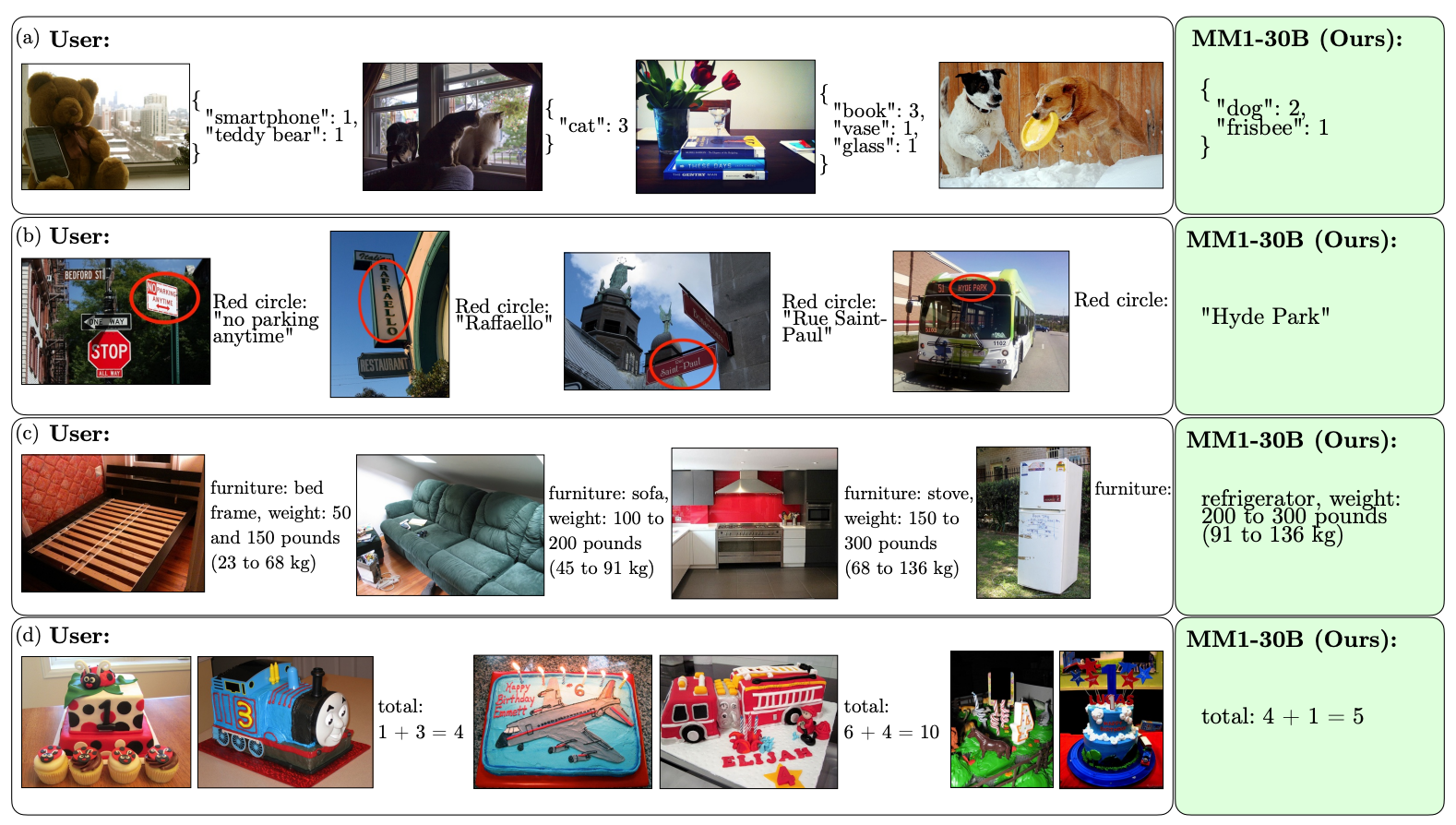
Her er nogle eksempler på MM1's VQA-evner.

MM1 gennemgik en storstilet multimodal pretræning på "et datasæt med 500M sammenflettede billed-tekstdokumenter, der indeholder 1B billeder og 500B teksttokens."
Omfanget og mangfoldigheden af fortræningen gør det muligt for MM1 at udføre imponerende forudsigelser i kontekst og følge brugerdefineret formatering med et lille antal eksempler på få billeder. Her er eksempler på, hvordan MM1 lærer det ønskede output og format ud fra kun 3 eksempler.
At lave AI-modeller, der kan "se" og ræsonnere, kræver en vision-sprog-forbindelse, der oversætter billeder og sprog til en samlet repræsentation, som modellen kan bruge til videre behandling.
Forskerne fandt ud af, at designet af syns-sprogforbindelsen var en mindre faktor i forhold til MM1's præstation. Interessant nok var det billedopløsningen og antallet af billedtokens, der havde den største indvirkning.
Det er interessant at se, hvor åben Apple har været med hensyn til at dele sin forskning med det bredere AI-samfund. Forskerne siger, at "i denne artikel dokumenterer vi MLLM-byggeprocessen og forsøger at formulere designlektioner, som vi håber kan være til nytte for samfundet."
De offentliggjorte resultater vil sandsynligvis påvirke den retning, som andre MMLM-udviklere tager med hensyn til arkitektur og valg af data til prætræning.
Præcis hvordan MM1-modellerne vil blive implementeret i Apples produkter, er endnu uvist. De offentliggjorte eksempler på MM1's evner antyder, at Siri bliver meget smartere, når hun til sidst lærer at se.



