

På trods af hurtige fremskridt inden for LLM'er er vores forståelse af, hvordan disse modeller håndterer længere input, stadig dårlig.
Mosh Levy, Alon Jacoby og Yoav Goldberg fra Bar-Ilan University og Allen Institute for AI undersøgte, hvordan ydeevnen for store sprogmodeller (LLM'er) varierer med ændringer i længden af den inputtekst, de får til behandling.
De udviklede et ræsonnementssystem specifikt til dette formål, så de kunne analysere inputlængdens indflydelse på LLM-ræsonnementet i et kontrolleret miljø.
Spørgerammen foreslog forskellige versioner af det samme spørgsmål, som hver især indeholdt de nødvendige oplysninger til at besvare spørgsmålet, men som var fyldt med yderligere, irrelevant tekst af varierende længde og type.
Det gør det muligt at isolere inputlængden som en variabel og sikre, at ændringer i modellens ydeevne kan tilskrives inputlængden direkte.
Vigtige resultater
Levy, Jacoby og Goldberg afslørede, at LLM'er udviser et bemærkelsesværdigt fald i ræsonnementspræstation ved inputlængder langt under, hvad udviklere hævder, at de kan håndtere. De dokumenterede deres resultater i denne undersøgelse.
Faldet blev konsekvent observeret på tværs af alle versioner af datasættet, hvilket indikerer et systemisk problem med håndtering af længere input snarere end et problem, der er knyttet til specifikke dataeksempler eller modelarkitekturer.
Som forskerne beskriver: "Vores resultater viser en bemærkelsesværdig forringelse af LLM'ernes ræsonnementsevne ved meget kortere inputlængder end deres tekniske maksimum. Vi viser, at tendensen til forringelse optræder i alle versioner af vores datasæt, men med forskellig intensitet."

Desuden fremhæver undersøgelsen, hvordan traditionelle målinger som perplexitet, der ofte bruges til at evaluere LLM'er, ikke korrelerer med modellernes ydeevne på ræsonneringsopgaver, der involverer lange input.
Yderligere undersøgelser viste, at forringelsen af ydeevnen ikke kun var afhængig af tilstedeværelsen af irrelevant information (padding), men blev observeret, selv når en sådan padding bestod af duplikeret relevant information.
Når vi holder de to kerneområder sammen og tilføjer tekst omkring dem, falder nøjagtigheden allerede. Når vi indfører afsnit mellem spændene, falder resultaterne meget mere. Faldet sker både, når de tekster, vi tilføjer, ligner opgaveteksterne, og når de er helt forskellige. 3/7 pic.twitter.com/c91l9uzyme
- Mosh Levy (@mosh_levy) 26. februar 2024
Det tyder på, at udfordringen for LLM'er ligger i at filtrere støj og den iboende behandling af længere tekstsekvenser fra.
Ignorerer instruktioner
Et kritisk område for fejltilstand, der blev fremhævet i undersøgelsen, er LLM'ernes tendens til at ignorere instruktioner, der er indlejret i inputtet, når inputlængden øges.
Modellerne ville også nogle gange generere svar, der indikerede usikkerhed eller mangel på tilstrækkelig information, såsom "Der er ikke nok information i teksten" på trods af al den nødvendige information.
Generelt ser det ud til, at LLM'erne konsekvent kæmper med at prioritere og fokusere på vigtige informationer, herunder direkte instruktioner, når inputlængden vokser.
Udviser bias i svarene
Et andet bemærkelsesværdigt problem var øgede skævheder i modellernes svar, når input blev længere.
Specifikt var LLM'erne tilbøjelige til at svare "Falsk", når inputlængden steg. Denne bias indikerer en skævhed i sandsynlighedsvurderingen eller beslutningsprocesserne i modellen, muligvis som en defensiv mekanisme som reaktion på øget usikkerhed på grund af længere inputlængder.
Tilbøjeligheden til at favorisere "Falske" svar kan også afspejle en underliggende ubalance i træningsdataene eller en artefakt i modellernes træningsproces, hvor negative svar kan være overrepræsenteret eller forbundet med sammenhænge med usikkerhed og tvetydighed.
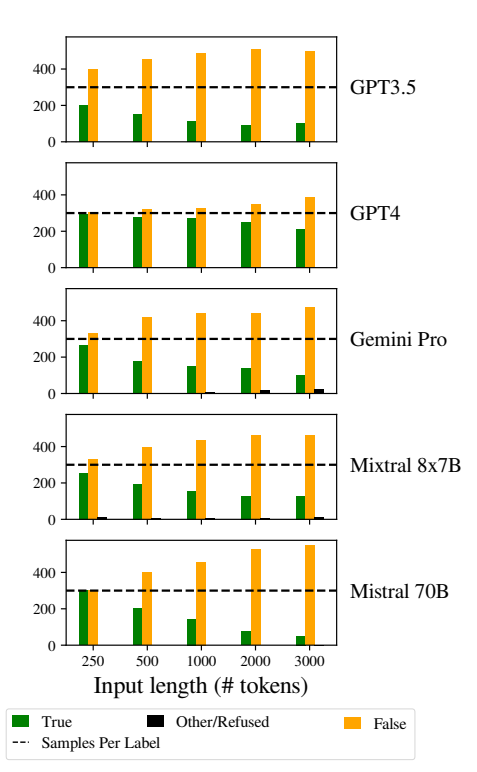
Denne skævhed påvirker nøjagtigheden af modellernes output og giver anledning til bekymring for LLM'ernes pålidelighed og retfærdighed i applikationer, der kræver nuanceret forståelse og upartiskhed.
Implementering af robuste strategier til påvisning og afbødning af bias under modeltræning og finjusteringsfaser er afgørende for at reducere ubegrundede bias i modelresponser.
EHvis man sørger for, at træningsdatasættene er forskellige, afbalancerede og repræsentative for en bred vifte af scenarier, kan det også hjælpe med at minimere bias og forbedre generaliseringen af modellerne.
Dette bidrager til andre nyere undersøgelser der på samme måde fremhæver grundlæggende problemer i, hvordan LLM'er fungerer, og dermed fører til en situation, hvor den "tekniske gæld" kan true modellens funktionalitet og integritet over tid.



