
Screening af patienter for at finde egnede deltagere til kliniske forsøg er en arbejdskrævende, dyr og fejlbehæftet opgave, men AI kan snart løse det.
Et hold forskere fra Brigham and Women's Hospital, Harvard Medical School og Mass General Brigham Personalized Medicine gennemførte en undersøgelse for at se, om en AI-model kunne behandle lægejournaler for at finde egnede kandidater til kliniske forsøg.
De brugte GPT-4V, OpenAI's LLM med billedbehandling, aktiveret af Retrieval-Augmented Generation (RAG) til at behandle potentielle kandidaters elektroniske sundhedsjournaler (EHR) og kliniske notater.
LLM'er er trænet på forhånd ved hjælp af et fast datasæt og kan kun besvare spørgsmål baseret på disse data. RAG er en teknik, der gør det muligt for en LLM at hente data fra eksterne datakilder som internettet eller en organisations interne dokumenter.
Når deltagere udvælges til et klinisk forsøg, afgøres deres egnethed ud fra en liste med inklusions- og eksklusionskriterier. Det indebærer normalt, at uddannet personale finkæmmer hundredvis eller tusindvis af patienters EPJ'er for at finde dem, der matcher kriterierne.
Forskerne indsamlede data fra et forsøg, der havde til formål at rekruttere patienter med symptomatisk hjertesvigt. De brugte disse data til at se, om GPT-4V med RAG kunne gøre arbejdet mere effektivt end forsøgspersonalet, samtidig med at nøjagtigheden blev opretholdt.
De strukturerede data i de potentielle kandidaters EPJ'er kan bruges til at fastlægge 5 ud af 6 inklusionskriterier og 5 ud af 17 eksklusionskriterier for det kliniske forsøg. Det er den nemme del.
De resterende 13 kriterier skulle bestemmes ved at undersøge ustrukturerede data i hver patients kliniske noter, hvilket er den arbejdskrævende del, som forskerne håbede, at AI kunne hjælpe med.
🔍Kan @Microsoft @Azure @OpenAI's #GPT4 præstere bedre end et menneske til screening af kliniske forsøg? Det spørgsmål stillede vi i vores seneste undersøgelse, og jeg er meget begejstret for at kunne dele vores resultater i preprint:https://t.co/lhOPKCcudP
At integrere GPT4 i kliniske forsøg er ikke...- Ozan Unlu (@OzanUnluMD) 9. februar 2024
Resultater
Forskerne indhentede først strukturerede vurderinger udført af studiepersonalet og kliniske notater for de sidste to år.
De udviklede en arbejdsgang til et klinisk notatbaseret spørgsmål-svar-system, der er drevet af RAG-arkitektur og GPT-4V, og kaldte denne arbejdsgang RECTIFIER (RAG-Enabled Clinical Trial Infrastructure for Inclusion Exclusion Review).
Noter fra 100 patienter blev brugt som udviklingsdatasæt, 282 patienter som valideringsdatasæt og 1894 patienter som testsæt.
En klinisk ekspert gennemførte en blindet gennemgang af patienternes journaler for at besvare spørgsmålene om berettigelse og bestemme "guldstandard"-svarene. Disse blev derefter sammenlignet med svarene fra forsøgspersonalet og RECTIFIER baseret på følgende kriterier:
- Sensitivitet - En tests evne til korrekt at identificere patienter, der er kvalificerede til forsøget (sande positive).
- Specificitet - En tests evne til korrekt at identificere patienter, der ikke er kvalificerede til forsøget (ægte negative).
- Nøjagtighed - Den samlede andel af korrekte klassifikationer (både sande positive og sande negative).
- Matthews korrelationskoefficient (MCC) - En metrik, der bruges til at måle, hvor god modellen var til at vælge eller udelukke en person. En værdi på 0 er det samme som et møntkast, og 1 betyder, at man rammer rigtigt 100% af gangene.
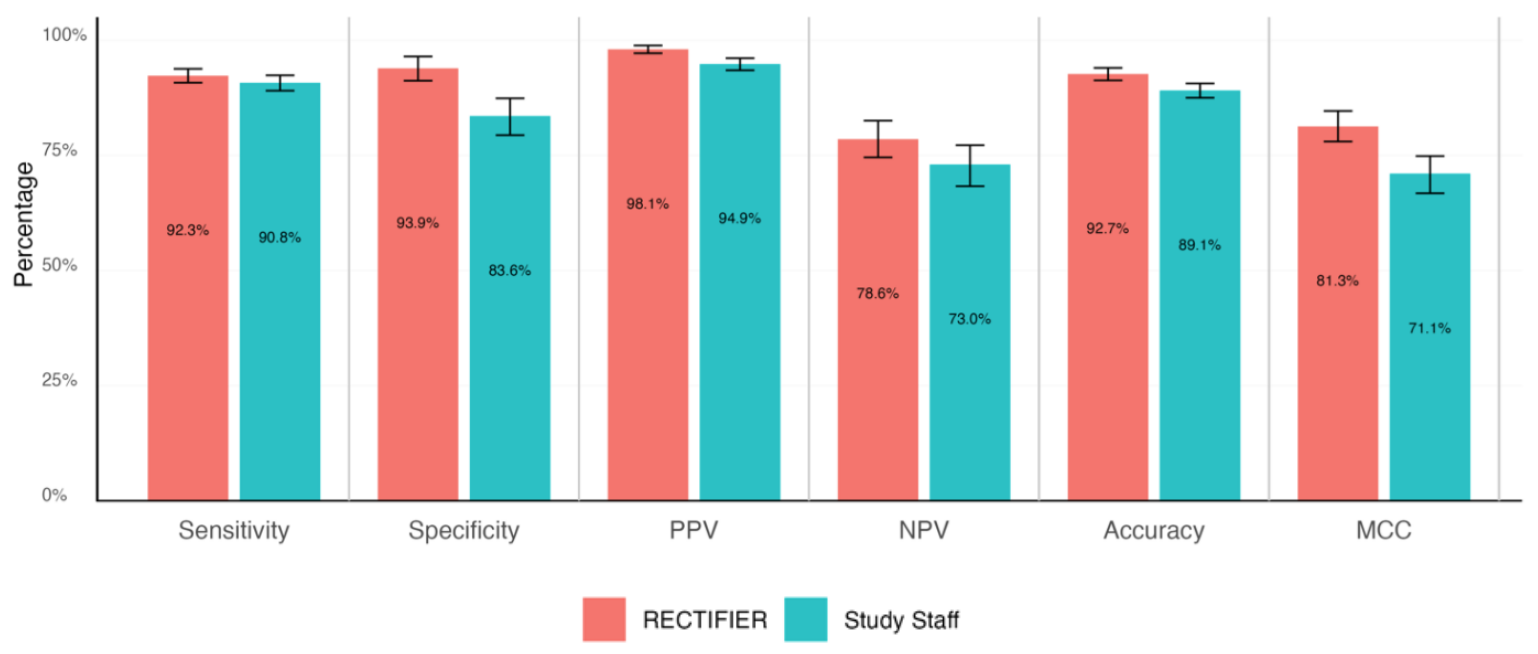
RECTIFIER klarede sig lige så godt, og i nogle tilfælde bedre, end studiepersonalet. Det mest betydningsfulde resultat af undersøgelsen kom sandsynligvis fra omkostningssammenligningen.
Der blev ikke oplyst tal for aflønningen af forsøgspersonalet, men det må have været betydeligt mere end omkostningerne ved at bruge GPT-4V, som varierede mellem $0,02 og $0,10 pr. patient. At bruge AI til at evaluere en pulje på 1.000 potentielle kandidater ville tage et par minutter og koste omkring $100.
Forskerne konkluderede, at brugen af en AI-model som GPT-4V med RAG kan opretholde eller forbedre nøjagtigheden i identifikationen af kandidater til kliniske forsøg og gøre det mere effektivt og meget billigere end at bruge menneskelige medarbejdere.
De bemærkede, at man skal være forsigtig med at overlade lægehjælp til automatiserede systemer, men det ser ud til, at AI vil gøre et bedre stykke arbejde, end vi kan, hvis det styres korrekt.



