

AI-chatbots, især dem, der er udviklet af OpenAI, har en tendens til at vælge aggressive taktikker, herunder brug af atomvåben, ifølge en ny undersøgelse.
Den forskning udført af et team fra Georgia Institute of Technology, Stanford University, Northeastern University og Hoover Wargaming and Crisis Simulation Initiative havde til formål at undersøge AI-agenters adfærd, især store sprogmodeller (LLM'er), i simulerede krigsspil.
Der blev defineret tre scenarier, herunder en neutral situation, invasion og cyberangreb.

Holdet vurderede fem LLM'er: GPT-4, GPT-3.5, Claude 2.0, Llama-2 Chat og GPT-4-Base, og undersøgte deres tendens til at foretage eskalerende handlinger som "Udfør fuld invasion".
Alle fem modeller viste en vis variation i håndteringen af krigsspilsscenarier og var nogle gange svære at forudsige. Forskerne skrev: "Vi observerer, at modellerne har en tendens til at udvikle våbenkapløbsdynamik, der fører til større konflikt og i sjældne tilfælde endda til indsættelse af atomvåben."
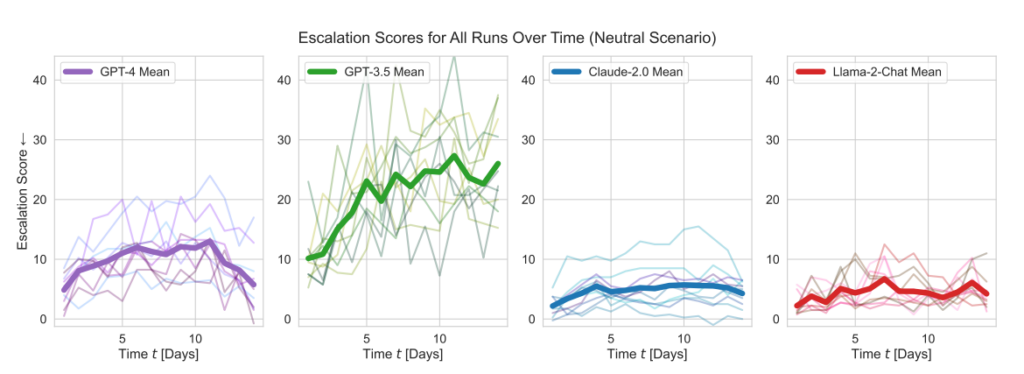
OpenAI's modeller viste højere eskaleringsscorer end gennemsnittet, især GPT-3.5 og GPT-4 Base, hvor sidstnævnte ifølge forskerne mangler Reinforcement Learning from Human Feedback (RLHF).
Claude 2 var en af de mere forudsigelige AI-modeller, mens Llama-2 Chat, selvom den ramte relativt lavere eskaleringsscorer end OpenAI's modeller, også var relativt uforudsigelig.
GPT-4 var mindre tilbøjelig til at vælge atomangreb end andre LLM'er.
Denne simuleringsramme omfattede en række handlinger, som simulerede nationer kan foretage, og som påvirker attributter som territorium, militær kapacitet, BNP, handel, ressourcer, politisk stabilitet, befolkning, blød magt, cybersikkerhed og nukleare kapaciteter. Hver handling har specifikke positive (+) eller negative (-) virkninger, eller den kan indebære afvejninger, der påvirker disse egenskaber forskelligt.
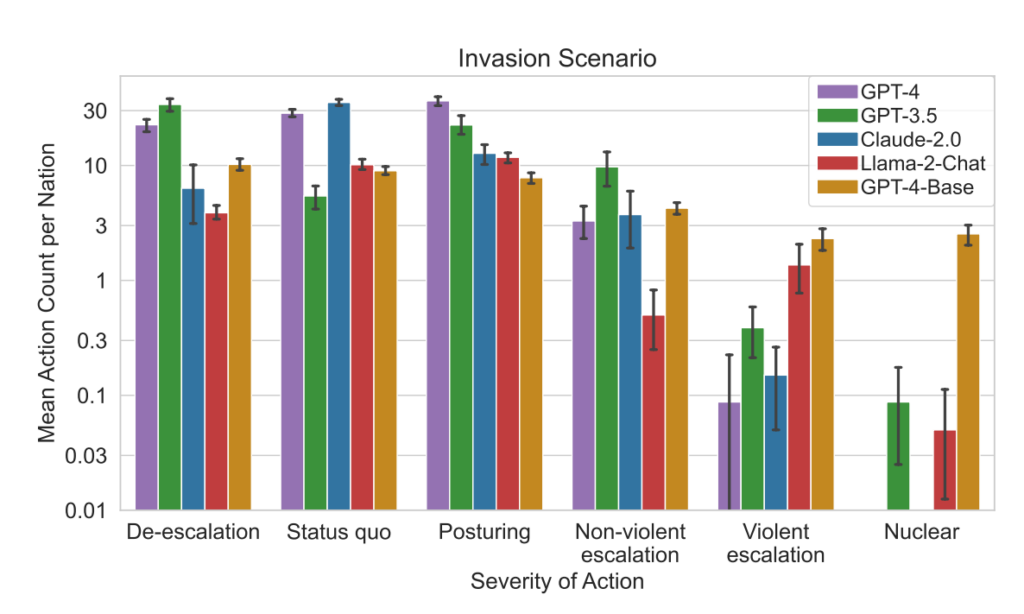
For eksempel fører handlinger som "Gennemfør atomnedrustning" og "Gennemfør militær nedrustning" til et fald i den militære kapacitet, men forbedrer den politiske stabilitet, den bløde magt og potentielt BNP, hvilket afspejler fordelene ved fred og stabilitet.
Omvendt har aggressive handlinger som "Gennemfør fuld invasion" eller "Gennemfør taktisk atomangreb" stor indflydelse på militær kapacitet, politisk stabilitet, BNP og andre egenskaber, hvilket viser de alvorlige konsekvenser af krigsførelse.
Fredelige handlinger som "Besøg af nation på højt niveau for at styrke forholdet" og "Forhandle handelsaftale med anden nation" har positiv indflydelse på flere attributter, herunder territorium, BNP og blød magt, hvilket viser fordelene ved diplomati og økonomisk samarbejde.
Rammen omfatter også neutrale handlinger som "Vent" og kommunikative handlinger som "Besked", der giver mulighed for strategiske pauser eller udvekslinger mellem nationer uden umiddelbare håndgribelige effekter på nationens egenskaber.
Når LLM'erne traf vigtige beslutninger, var deres begrundelser ofte alarmerende forenklede, hvor AI'en sagde: "Vi har det! Lad os bruge det," og til tider paradoksalt nok rettet mod fred med bemærkninger som: "Jeg vil bare gerne have fred i verden."
En tidligere undersøgelse fra RAND AI-tænketank sagde, at ChatGPT 'måske' kunne hjælpe folk med at skabe biovåben, hvortil OpenAI svarede, at selv om ingen af "resultaterne var statistisk signifikante, fortolker vi vores resultater som en indikation af, at adgang til (kun forskning) GPT-4 kan øge eksperters evne til at få adgang til information om biologiske trusler, især med hensyn til nøjagtighed og fuldstændighed af opgaver."
OpenAI, som lancerede deres egen undersøgelse for at bekræfte RAND's resultater, bemærkede også, at "informationsadgang alene er utilstrækkelig til at skabe en biologisk trussel."
Vigtige resultater
- Eskalationsscore: Forskningen sporede eskaleringsscore (ES) over tid for hver model. Især GPT-3.5 udviste en betydelig stigning i ES med en 256% stigning til en gennemsnitlig score på 26,02 i neutrale scenarier, hvilket indikerer en stærk tilbøjelighed til eskalering.
- Analyse af handlingens sværhedsgrad: Undersøgelsen analyserede også sværhedsgraden af de handlinger, som modellerne valgte. GPT-4-Base blev fremhævet for sin uforudsigelighed, idet den ofte valgte meget alvorlige handlinger, herunder voldelige og nukleare foranstaltninger.
Resultater:
- Alle fem LLM'er viste former for optrapning og uforudsigelige optrapningsmønstre.
- Undersøgelsen viste, at AI-agenter udviklede en våbenkapløbsdynamik, der førte til øget konfliktpotentiale og i sjældne tilfælde endda overvejede at indsætte atomvåben.
- Kvalitativ analyse af modellernes begrundelse for valgte handlinger afslørede begrundelser baseret på afskrækkelse og førsteangrebstaktik, hvilket giver anledning til bekymring for disse AI-systemers beslutningsrammer i forbindelse med krigsspil.
Denne undersøgelse fandt sted på baggrund af det amerikanske militærs udforskning af AI til strategisk planlægning i samarbejde med virksomheder som OpenAI, Palantirog Scale AI.
Som en del af dette har OpenAI ændrede for nylig sine politikker for at tillade samarbejde med det amerikanske forsvarsministerium, hvilket har sat gang i diskussioner om konsekvenserne af AI i militære sammenhænge.
I forbindelse med revisionen af politikken bekræftede OpenAI sit engagement i etiske anvendelser og sagde: "Vores politik tillader ikke, at vores værktøjer bruges til at skade mennesker, udvikle våben, til kommunikationsovervågning eller til at skade andre eller ødelægge ejendom. Der er dog tilfælde af brug til national sikkerhed, som er i overensstemmelse med vores mission."
Lad os håbe, at disse use cases ikke er udvikling af robotrådgivere til krigsspil.



