

Forskere fra UC San Diego og New York University har udviklet V*, en LLM-styret søgealgoritme, som er meget bedre end GPT-4V til at forstå konteksten og til at ramme specifikke visuelle elementer i billeder.
Multimodale store sprogmodeller (MLLM) som OpenAI's GPT-4V slog benene væk under os sidste år med deres evne til at besvare spørgsmål om billeder. Hvor imponerende GPT-4V end er, så kæmper den nogle gange, når billederne er meget komplekse og ofte overser små detaljer.
V*-algoritmen bruger en Visual Question Answering (VQA) LLM til at guide den i at identificere, hvilket område af billedet den skal fokusere på for at besvare en visuel forespørgsel. Forskerne kalder denne kombination for Show, sEArch og telL (SEAL).
Hvis nogen gav dig et billede i høj opløsning og stillede dig et spørgsmål om det, ville din logik få dig til at zoome ind på et område, hvor der er størst sandsynlighed for at finde den pågældende genstand. SEAL bruger V* til at analysere billeder på en lignende måde.
En visuel søgemodel kunne simpelthen opdele et billede i blokke, zoome ind på hver blok og derefter behandle det for at finde det pågældende objekt, men det er beregningsmæssigt meget ineffektivt.
Når V* får en tekstforespørgsel om et billede, forsøger den først at finde billedmålet direkte. Hvis det ikke lykkes, beder den MLLM om at bruge sin sunde fornuft til at identificere det område i billedet, hvor det er mest sandsynligt, at målet befinder sig.
Derefter fokuserer den sin søgning på netop det område i stedet for at forsøge en "indzoomet" søgning på hele billedet.

Når GPT-4V bliver bedt om at besvare spørgsmål om et billede, der kræver omfattende visuel behandling af højopløselige billeder, har den det svært. SEAL, der bruger V*, klarer sig meget bedre.

På spørgsmålet "Hvilken slags drik kan vi købe i den automat?" svarede SEAL "Coca-Cola". svarede SEAL "Coca-Cola", mens GPT-4V fejlagtigt gættede på "Pepsi".
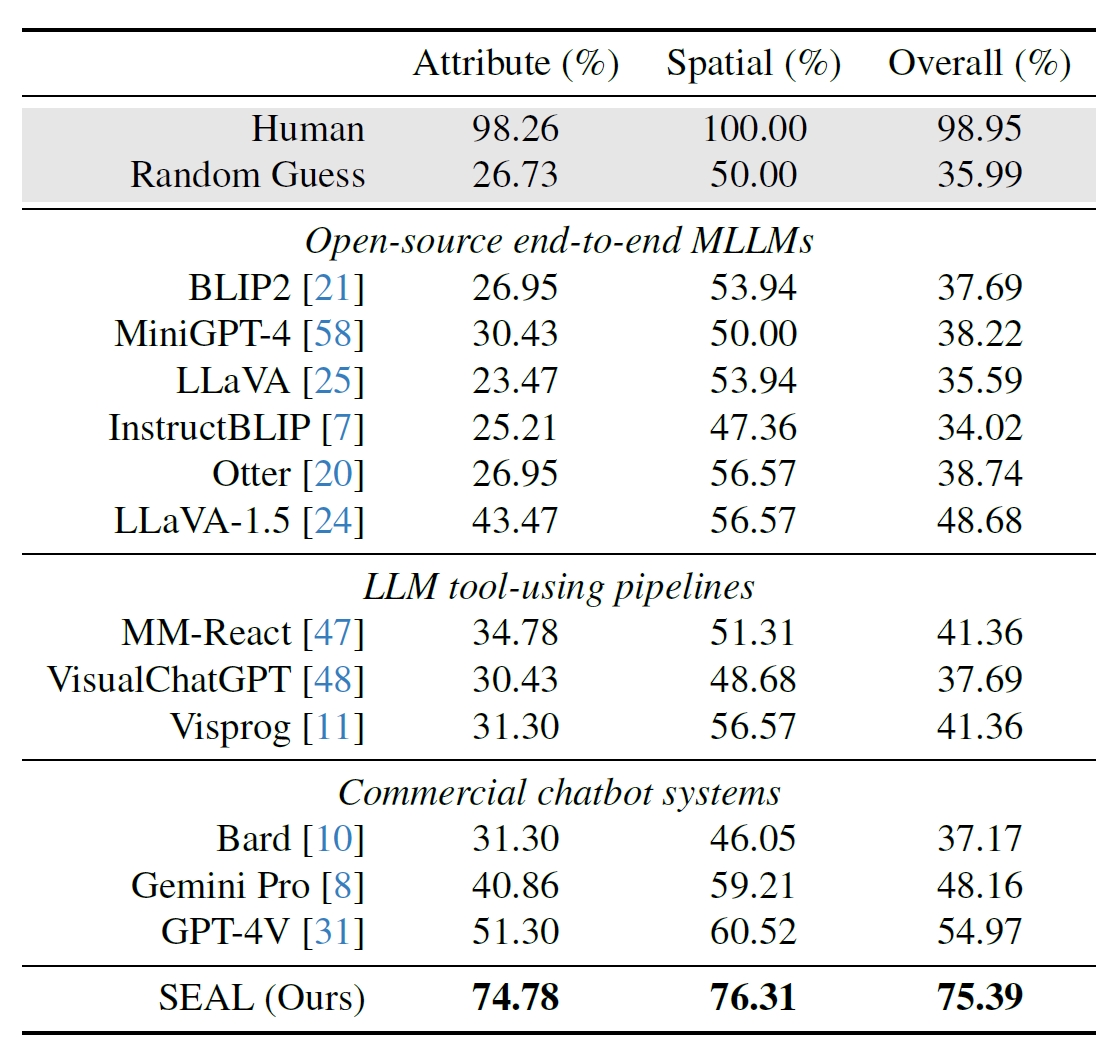
Forskerne brugte 191 billeder i høj opløsning fra Meta's Segment Anything (SAM)-datasæt og skabte et benchmark for at se, hvordan SEALs præstation var sammenlignet med andre modeller. V*Bench-benchmarken tester to opgaver: genkendelse af attributter og rumlige relationer.
Figurerne nedenfor viser den menneskelige ydeevne sammenlignet med open source-modeller, kommercielle modeller som GPT-4V og SEAL. Det løft, som V* giver i SEALs præstation, er særligt imponerende, fordi den underliggende MLLM, den bruger, er LLaVa-7b, som er meget mindre end GPT-4V.
Denne intuitive tilgang til at analysere billeder ser ud til at fungere rigtig godt med en række imponerende eksempler på papirets resumé på GitHub.
Det bliver interessant at se, om andre MLLM'er som dem fra OpenAI eller Google anvender en lignende tilgang.
På spørgsmålet om, hvilken drik der blev solgt fra automaten på billedet ovenfor, svarede Googles Bard: "Der er ingen automat i forgrunden." Måske vil Gemini Ultra gøre et bedre stykke arbejde.
Indtil videre ser det ud til, at SEAL og dens nye V*-algoritme er langt foran nogle af de største multimodale modeller, når det gælder visuel afhøring.



