

Tidligere på måneden annoncerede Google stolt, at deres mest kraftfulde Gemini-model slog GPT-4 i Massive Multitask Language Understanding MMLU-benchmark-tests. Med Microsofts nye prompting-teknik genvinder GPT-4 førstepladsen, om end med en brøkdel af en procent.
Ud over dramaet omkring markedsføringsvideoen er Googles Gemini en stor sag for virksomheden, og dens MMLU-benchmarkresultater er imponerende. Men Microsoft, OpenAI's største investor, ventede ikke længe med at kaste skygge over Googles indsats.
Overskriften er, at Microsoft fik GPT-4 til at slå Gemini Ultras MMLU-resultater. Virkeligheden er, at den slog Geminis score på 90,04% med kun 0,06%.
Baggrunden for, hvad der gjorde det muligt, er mere spændende end den inkrementelle overlegenhed, vi ser på disse ranglister. Microsofts nye prompting-teknikker kan øge ældre AI-modellers ydeevne.
Kan du huske, at Googles uudgivne Gemini Ultra lige har slået GPT-4 og er blevet den bedste AI?
Microsoft har netop demonstreret, at GPT-4 med den rette vejledning faktisk slår Gemini på benchmarks.
Der er masser af plads til forbedringer, selv med ældre modeller. https://t.co/YQ5zJI6Gad pic.twitter.com/X3HFmXa30X
- Ethan Mollick (@emollick) 12. december 2023
Medprompt
Når man hører folk tale om at "styre" en model, mener de bare, at man med omhyggelig vejledning kan få en model til at give et output, der er bedre i overensstemmelse med det, man ønskede.
Microsoft udviklede en kombination af promptteknikker, som viste sig at være rigtig gode til dette. Medprompt startede som et projekt for at få GPT-4 til at give bedre svar på benchmarks for medicinske udfordringer som MultiMedQA-testsættet.
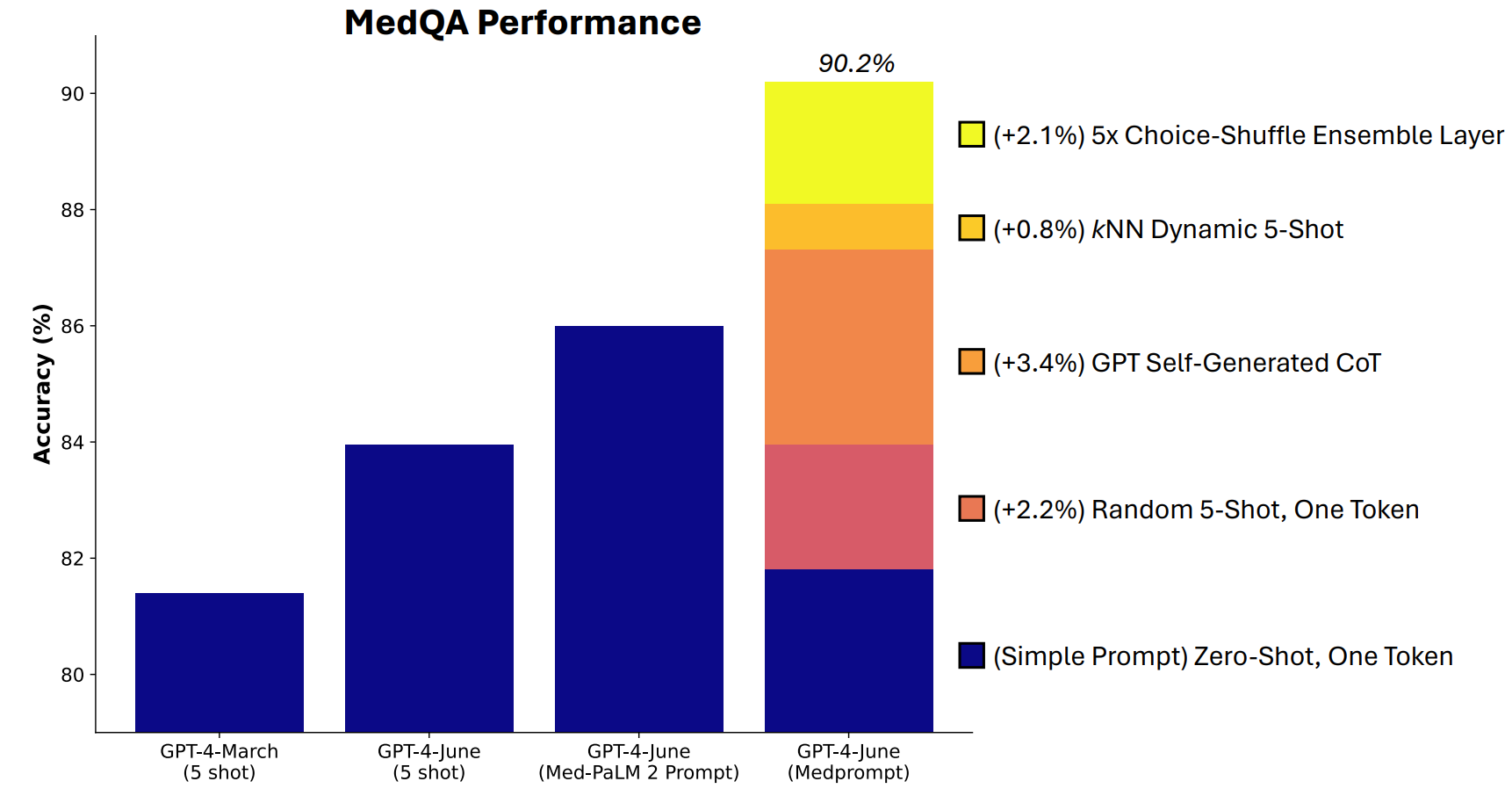
Microsoft-forskerne tænkte, at hvis Medprompt fungerede godt i specialiserede medicinske tests, kunne det også forbedre GPT-4's generalistpræstation. Og dermed genvandt Microsoft og OpenAI retten til at prale med GPT-4 over Gemini Ultra.
Hvordan fungerer Medprompt?
Medprompt er en kombination af smarte promptteknikker, der alle er samlet i én. Den bygger på tre hovedteknikker.
Dynamisk læring med få skud (DFSL)
"Few-shot learning" henviser til, at man giver GPT-4 nogle få eksempler, før man beder den om at løse et lignende problem. Når du ser en reference som "5-shot", betyder det, at modellen fik 5 eksempler. "Zero-shot" betyder, at den skulle svare uden nogen eksempler.
Medprompt-artiklen forklarede, at "af hensyn til enkelhed og effektivitet er de få eksempler, der anvendes i prompten til en bestemt opgave, typisk faste; de er uændrede på tværs af testeksemplerne."
Resultatet er, at de eksempler, modellerne præsenteres for, ofte kun er bredt relevante eller repræsentative.
Hvis dit træningssæt er stort nok, kan du få modellen til at se alle eksemplerne igennem og vælge dem, der semantisk ligner det problem, den skal løse. Resultatet er, at de få læringseksempler er mere specifikt tilpasset et bestemt problem.
Selvgenereret tankekæde (CoT)
Chain of Thought (CoT) er en god måde at styre en LLM på. Når du beder den om at "tænke sig om" eller "løse det trin for trin", bliver resultaterne meget bedre.
Du kan blive meget mere specifik i den måde, du styrer den tankekæde, som modellen skal følge, men det involverer manuel prompt engineering.
Forskerne fandt ud af, at de "simpelthen kunne bede GPT-4 om at generere tankekæder til træningseksemplerne". Deres tilgang fortæller grundlæggende GPT-4: "Her er et spørgsmål, svarmulighederne og det korrekte svar. Hvilken CoT skal vi inkludere i en prompt, der vil føre til dette svar?
Valg af blanding af ensembler
De fleste af MMLU's benchmarktests er multiple choice-spørgsmål. Når en AI-model besvarer disse spørgsmål, kan den blive offer for positionel bias. Med andre ord kan den favorisere mulighed B over tid, selv om det ikke altid er det rigtige svar.
Choice Shuffle Ensembling blander svarmulighedernes positioner og får GPT-4 til at besvare spørgsmålet igen. Det gør den flere gange, og derefter vælges det mest konsekvent valgte svar som det endelige svar.
Det var kombinationen af disse tre teknikker, der gav Microsoft mulighed for at kaste lidt skygge over Geminis resultater. Det bliver interessant at se, hvilke resultater Gemini Ultra ville opnå, hvis den brugte en lignende tilgang.
Medprompt er spændende, fordi det viser, at ældre modeller kan præstere endnu bedre, end vi troede, hvis vi beder dem om det på en smart måde. Den ekstra processorkraft, der er nødvendig for disse ekstra trin, gør det dog måske ikke til en brugbar tilgang i de fleste scenarier.



