

Elon Musk annoncerede betalanceringen af xAI's chatbot kaldet Grok, og de første statistikker giver os en idé om, hvordan den klarer sig i forhold til andre modeller.
Den Grok chatbot er baseret på xAI's frontier-model kaldet Grok-1, som virksomheden har udviklet i løbet af de sidste fire måneder. xAI har ikke sagt, hvor mange parametre den blev trænet med, men drillede med nogle tal for sin forgænger.
Grok-0, prototypen for den nuværende model, blev trænet på 33 milliarder parametre, så vi kan nok antage, at Grok-1 blev trænet på mindst lige så mange.
Det lyder ikke af meget, men xAI hævder, at Grok-0's ydeevne "nærmer sig LLaMA 2 (70B) på standard LM-benchmarks", selv om den brugte halvdelen af træningsressourcerne.
I mangel af et parameter-tal må vi tage virksomhedens ord for gode varer, når den beskriver Grok-1 som "state-of-the-art", og at den er "betydeligt mere kraftfuld" end Grok-0.
Grok-1 blev testet ved at evaluere den på disse standard benchmarks for maskinlæring:
- GSM8k: Matematikopgaver til mellemtrinnet
- MMLU: Multidisciplinære multiple choice-spørgsmål
- HumanEval: Opgave til færdiggørelse af Python-kode
- MATH: Matematikopgaver til mellemtrinnet og udskolingen skrevet i LaTeX
Her er et sammendrag af resultaterne.
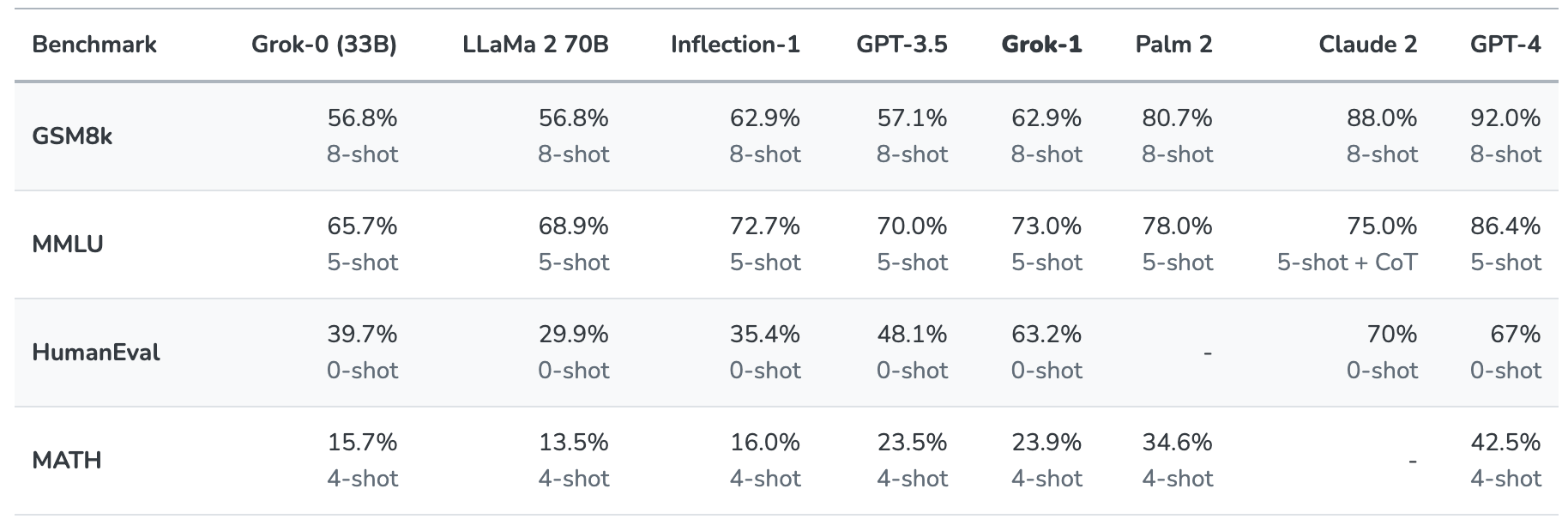
Resultaterne er interessante, fordi de i det mindste giver os en idé om, hvordan Grok klarer sig i forhold til andre frontier-modeller.
xAI siger, at disse tal viser, at Grok-1 slår "alle andre modeller i sin beregningsklasse" og kun blev slået af modeller, der var trænet af en "betydeligt større mængde træningsdata og beregningsressourcer".
GPT-3.5 har 175 milliarder parametre, så vi kan gå ud fra, at Grok-1 har mindre end det, men sandsynligvis mere end de 33 milliarder i prototypen.
Grok-chatbotten er beregnet til at behandle opgaver som besvarelse af spørgsmål, informationssøgning, kreativ skrivning og hjælp til kodning. Det er mere sandsynligt, at den vil blive brugt til kortere interaktioner end superhurtige brugssager på grund af dens mindre kontekstvindue.
Med en kontekstlængde på 8.192 har Grok-1 kun halvdelen af den kontekst, som GPT-3.5 har. Dette er en indikation af, at xAI sandsynligvis havde til hensigt, at Grok-1 skulle bytte en længere kontekst ud med bedre effektivitet.
Virksomheden siger, at noget af den nuværende forskning fokuserer på "forståelse og hentning af lange kontekster", så den næste udgave af Grok kan meget vel have et større kontekstvindue.
Det nøjagtige datasæt, der blev brugt til at træne Grok-1, er ikke klart, men det omfattede næsten helt sikkert dine tweets på X, og Grok-chatbotten har også adgang til internettet i realtid.
Vi bliver nødt til at vente på mere feedback fra betatestere for at få en fornemmelse af, hvor god modellen faktisk er.
Vil Grok hjælpe os med at opklare livets, universets og altings mysterier? Måske ikke helt endnu, men det er en underholdende start.



