

Luke Farritor, en 21-årig datalogistuderende fra University of Nebraska-Lincoln, har afsløret teksten i en forkullet skriftrulle fra det gamle Herculaneum.
Denne rulle har været ulæselig siden vulkanudbruddet i år 79 e.Kr., som også opslugte Pompeji. Farritors maskinlæringsalgoritme lokaliserede græske bogstaver på den sammenrullede papyrus, herunder ordet πορϕυρας (porphyras), som betyder 'lilla'.
Hans teknik gik ud på at identificere små, nuancerede forskelle i overfladeteksturen for at træne sit neurale netværk til at opdage blæk og dermed leterring.
"Da jeg så det første billede, blev jeg chokeret". sagde Federica Nicolardi, en papyrolog fra universitetet i Napoli. "Det var sådan en drøm," fortsatte hun, "jeg kan faktisk se noget fra indersiden af en skriftrulle."
Rullerne, som blev begravet af Vesuvs udbrud i 79 e.Kr., har været stort set utilgængelige på grund af deres skrøbelige tilstand.
Når man manuelt ruller de forkullede ruller ud, falder de fra hinanden, hvilket fik de lærde til at frygte, at indholdet ville forblive et mysterium for evigt.

Som Nicolardi forklarede: "Det er så skøre objekter. De er alle sammen krøllede og knuste."
I erkendelse af udfordringen med at dechifrere rullerne blev Vesuvius-udfordringen blev oprettet med forskellige priser, herunder en hovedpræmie på US$700.000 for at dechifrere flere passager fra en skriftrulle.
Den 12. oktober blev det offentliggjort, at Farritor havde vundet en præmie på $40.000 for at have identificeret over 10 tegn i et lille udsnit af papyrussen.
En anden deltager, Youssef Nader fra Freie Universität Berlin, modtog $10.000 for sin andenplads.
Historikeren Thea Sommerschield, som beskæftiger sig med det antikke Grækenland og Rom, beskriver det som "ekstremt spændende", at man nu endelig kan se bogstaver og ord i rullerne.
Sommerschield nævnte, at fortolkningen af disse kunne "revolutionere vores viden om oldtidens historie og litteratur" fra regionen.
Det er ikke første gang, at forskere har forsøgt at læse disse gamle karboniserede skriftruller. I 2019 forsøgte Brent Seales, professor i datalogi med speciale i virtuel læsning og bevaring af gamle skriftruller, at "pakke skriftrullerne virtuelt ud" ved hjælp af røntgencomputertomografi-scanninger (CT).
I 2016 lykkedes det Seales med et gammelt hebraisk pergament, der blev fundet i 1970 i Ein Gedi i Israel, at afsløre dele af Tredje Mosebog.
Men Herculaneum-rullerne udgjorde en anden udfordring: Blækket, der var lavet af trækul og vand, stod ikke frem i scanningerne.
Det var her, Farritor fik succes ved at fokusere på en specifik subtil tekstur, kaldet "krakelering", for spor af blæk.
Farritor sagde: "Jeg hoppede op og ned", da hans algoritme afslørede fem bogstaver fra et nyligt udgivet segment. "Du godeste, det her kommer faktisk til at virke," indså han.
Kort tid efter forfinede han sin model og identificerede de nødvendige ti bogstaver til prisen, hvor ordet 'purpur' ikke tidligere var identificeret i Herculaneum-rullerne.
Hovedpræmien i Vesuvius Challenge er endnu ikke afsløret, og fristen er sat til den 31. december.
AI til afkodning af gamle sprog
For seks årtusinder siden bosatte sumererne sig i Mesopotamien, landet der strækker sig over floderne Tigris og Eufrat.
Denne region, der dækker det nuværende Irak, Kuwait, Tyrkiet og Syrien, var vidne til udviklingen fra små landbrugssamfund til store bycivilisationer. Byer som Uruk blomstrede op og integrerede indviklede kanaler, vandingsanlæg og styringscentre. Det var en kritisk æra for menneskehedens fremskridt og udvikling.
Sumererne skrev med en skrift, der kaldes kileskrift. Dette skriftsystem krævede, at man pressede siv ned i ler, hvilket skabte komplekse logo-syllabiske inskriptioner. Kileskrift er ikke et sprog - det er en skrift, der omfatter omkring 15 sprog gennem tre årtusinder.

Mens kileskrift primært blev brugt som administrativt værktøj til f.eks. at registrere husdyr eller transaktioner, opstod der omkring 2700 f.Kr. en lang række mere filosofiske og kreative skrifter.
Et af de mest bemærkelsesværdige af disse skrifter er Gilgamesh-eposetsom strækker sig over tolv tavler.
Enrique Jiménez fra Ludwig Maximilians University i München siger: "Halvdelen af menneskehedens historie er indkapslet i disse kileskrifttavler."
Men kun 75 personer, ifølge New Scientistkan afkode kileskrift på trods af titusindvis af uoversatte tavler verden over.
Maskinlæring hjælper nu forskere med at opklare de historier, der er indgraveret i stentavler, og hjælper dem med at udfylde huller og ordne teksterne kronologisk for at finde ud af mere om, hvordan de gamle sumerere levede.
Maskinlæringens rolle i dekryptering af gamle tekster
Enrique Jiménez og hans team har grundlagt Elektronisk babylonisk litteratur, et samarbejde mellem arkæologer, dataforskere og historikere.
For at analysere kileskrifttavler brugte teamet en maskinlæringsteknik, der oprindeligt var designet til sammenligning af gensekvenser. Denne AI forudsiger indholdet af manglende sektioner og grænserne for, hvornår fragmenter passer sammen.
Denne teknik førte til opdagelser som manglende dele af Gilgamesh-eposet og en nyopdaget mesopotamisk genre, der beskriver pædagogiske parodier og vittigheder for børn.
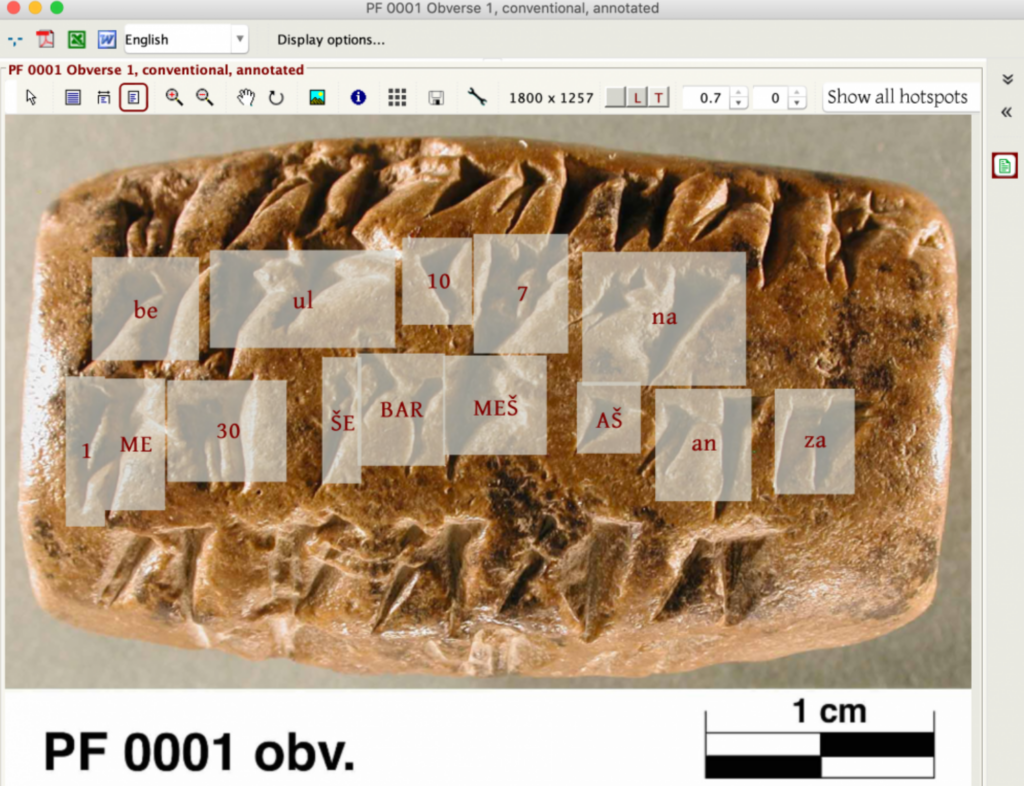
I 2020 en separat model, DeepScribeblev trænet på 6.000 annoterede billeder fra Persepolis' befæstningsarkivsom angiver ca. 100.000 symboler fra det elamitiske sprog (fra det nuværende Iran), dateret omkring 500 f.Kr.
Ved at udnytte ressourcer fra UChicago Research Computing Center trænede Krishnan og Eddie Williams en model, der var i stand til at afkode disse tegn med en imponerende nøjagtighed på 80%.
Teamet har til hensigt at udvikle DeepScribe til et alsidigt afkodningsværktøj, der kan omskoles til andre sprog end elamit.
DeepMind har også undersøgt afkodning af gamle sprog ved hjælp af maskinlæring - i dette tilfælde beskadigede oldgræske tavler.
Navngivet IthacaDenne model gendannede tekster med 72% præcision, anslog deres alder inden for tre årtier og formodede endda deres oprindelse med 71% nøjagtighed.

Ithacas træning omfattede 60.000 tekster fra 700 f.Kr. til 500 e.Kr. mærket med data om deres tid og sted på tværs af 84 gamle territorier.
Krydsfeltet mellem gamle tekster og avanceret AI viser, at selv årtusindgamle mysterier ikke er immune over for den moderne teknologis fremskridt.
Ved at blande det gamle med det nye bevarer forskerne både historien og skaber hidtil ukendte muligheder. arkæologisk viden.
Disse gennembrud understreger de ubegrænsede muligheder, når vi forener menneskelig nysgerrighed med teknologisk dygtighed, og viser, at der er en ny optik, hvorigennem vi kan se vores kollektive fortids vidundere.




{kind=link}