

Forskere har introduceret FANToM, et nyt benchmark designet til grundigt at teste og evaluere store sprogmodellers (LLM'er) forståelse og anvendelse af Theory of Mind (ToM).
Theory of Mind refererer til evnen til at tillægge sig selv og andre overbevisninger, ønsker og viden og til at forstå, at andre har overbevisninger og perspektiver, der er forskellige fra ens egne.
ToM anses for at være grundlaget for den bevidsthed, som intelligente dyr besidder. Ud over mennesker anses primater som orangutanger, gorillaer og chimpanser for at have ToM, og det samme gælder nogle ikke-primater som papegøjer og medlemmer af kragefuglefamilien.
Efterhånden som AI-modeller bliver mere komplekse, søger AI-forskere nye metoder til at evaluere evner som ToM.
Et nyt benchmark kaldet FANToMsom er skabt af forskere fra Allen Institute for AI, University of Washington, Carnegie Mellon University og Seoul National University, udsætter maskinlæringsmodeller for dynamiske scenarier, der afspejler interaktioner i det virkelige liv.
Med FANToM går karakterer ind og ud af samtaler, hvilket udfordrer AI-modeller til at opretholde en nøjagtig forståelse af, hvem der ved hvad på et givet tidspunkt.
Ved at udsætte store sprogmodeller (LLM'er) for FANToM viste det sig, at selv de mest avancerede modeller kæmper med at opretholde en konsistent ToM.
Modellernes præstation var betydeligt lavere end de menneskelige deltageres, hvilket understreger AI's begrænsninger i forhold til at forstå og navigere i komplekse sociale interaktioner.
Faktisk dominerede mennesker alle kategorier, som det ses nedenfor.
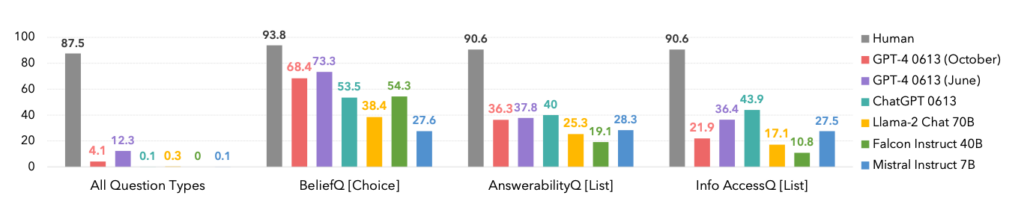
Et interessant sidepunkt er, at oktober-versionen af GPT-4-modellen blev overgået af en tidligere juni-version, hvilket kan understøtte de seneste anekdoter blandt brugerne om, at ChatGPT bliver værre og værre.
FANToM afslørede også teknikker til at forbedre LLM ToM, som f.eks. chain-of-thought ræsonnement og andre finjusteringsmetoder.
Men kløften mellem AI og menneskelige ToM-færdigheder er stadig stor.
AI springer mod menneskelignende sprogfærdigheder
I en noget relateret, men separat undersøgelse offentliggjort i Natureudviklede forskere et neuralt netværk, der var i stand til at generalisere sprog på samme måde som mennesker.
Dette nye neurale netværk viste en imponerende evne til at integrere nyligt lærte ord i sit eksisterende ordforråd. Det kunne derefter bruge disse ord i forskellige sammenhænge, en kognitiv færdighed kendt som systematisk generalisering.
Mennesker udviser naturligt systematisk generalisering og inkorporerer problemfrit nyt ordforråd i deres repertoire.
Når man f.eks. først har lært udtrykket "photobomb", kan man bruge det i forskellige situationer næsten med det samme. Der dukker hele tiden nye slangudtryk op, og mennesker optager dem naturligt i deres ordforråd.
Forskerne udsatte både deres eget brugerdefinerede neurale netværk og ChatGPT for en række tests og fandt ud af, at ChatGPT haltede bagefter den brugerdefinerede model i ydeevne.
Mens LLM'er som ChatGPT udmærker sig i mange samtalescenarier, udviser de bemærkelsesværdige uoverensstemmelser og huller i andre, et problem, som dette nye neurale netværk løser.
For at undersøge dette aspekt af sproglig kommunikation udførte forskere et eksperiment med 25 mennesker, hvor de vurderede deres evne til at anvende nyligt lærte ord i forskellige sammenhænge. Forsøgspersonerne blev introduceret til et pseudosprog bestående af nonsensord, der repræsenterede forskellige handlinger og regler.
Efter en træningsfase udmærkede deltagerne sig ved at anvende disse abstrakte regler på nye situationer, hvilket viste systematisk generalisering.
Da det nyudviklede neurale netværk blev udsat for denne opgave, afspejlede det den menneskelige præstation. Men da ChatGPT blev udsat for den samme udfordring, havde den store problemer og fejlede mellem 42 og 86% af tiden, afhængigt af den specifikke opgave.
Det er vigtigt af to grunde. For det første kan man argumentere for, at dette nye neurale netværk effektivt udkonkurrerede GPT-4 på denne specifikke opgave - hvilket er imponerende nok. For det andet afslører denne undersøgelse nye metoder til at lære AI-modeller at generalisere nyt sprog ligesom mennesker.
Som Elia Bruni, der er specialist i naturlig sprogbehandling ved Osnabrück Universitet i Tyskland, beskriver det: "Det er en stor ting at indføre systematik i neurale netværk."
Tilsammen tilbyder disse to studier nye tilgange til at træne mere intelligente AI-modeller, der kan konkurrere med mennesker på kritiske områder som lingvistik og Theory of Mind.



