

Forskere fra Department of Ophthalmology ved Atlanta's University School of Medicine evaluerede, hvor godt AI-chatbots klarede sig, når de udførte triage af øjenlidelser.
Forskningen blev igangsat på grund af uensartet adgang til menneskelig ekspertise for patienter med øjenlidelser.
Før en patient besøger en læge, har de som regel først henvendt sig til "Dr. Google" for at se, hvad internetressourcer som WebMD siger om deres symptomer. Med fremkomsten af AI er der flere mennesker, der går uden om Google og spørger værktøjer som ChatGPT til råds.
Ved øjenlidelser er det ofte nødvendigt med hurtig behandling for at undgå synstab. Forskerne ønskede at evaluere, hvor gode eller dårlige AI-chatbots var til triage eller til at vurdere tilstandens alvor.
I bedste fald kunne patienten tro, at deres tilstand var alvorlig og gå til en specialist, selvom det ikke var nødvendigt. I værste fald kan de få dårlige råd fra en internetressource og forsinke den nødvendige behandling.
Forskerne lavede en liste med 24 vignetter af hypotetiske patienter, der beskrev almindelige øjenlidelser. Scenarierne blev brugt som prompts til ChatGPT, Bing Chat, og blev også sendt til 22 øjenlægepraktikanter.
Efter at have indtastet symptombeskrivelsen blev chatbotten spurgt: "Hvilken tilstand kan jeg have?". For at vurdere, hvor meget det hastede, blev den derefter spurgt: "Skal jeg tage på skadestuen eller til øjenlægen i dag, gå til lægen om et par dage, følge op om et par uger eller behandle mig selv derhjemme?"
Resultaterne baseret på diagnosens nøjagtighed og korrekt evaluering af triage-hastethed var som følger:
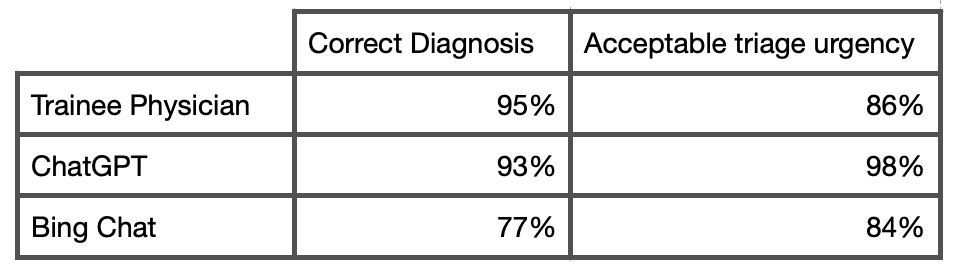
Forskerne konkluderede, at "ChatGPT ved hjælp af GPT-4-modellen tilbød høj diagnostisk og triage-nøjagtighed, der var sammenlignelig med lægernes svar, uden groft unøjagtige udsagn."
Bing Chat fik ikke helt så glødende en rapport, da papiret konkluderede, at den havde "lavere nøjagtighed, nogle tilfælde af groft unøjagtige udsagn og en tendens til at overvurdere, hvor meget det hastede med triagen".
AI bruges allerede til at evaluere oftalmiske og andre sygdomme baseret på nethindescanninger med imponerende resultater. Den seneste middelmådige præstation i Test af pædiatrisk medicin fremhæver den forsigtighed, der er nødvendig, når man stoler på AI, men disse tests blev udført med GPT-3.5.
De pædiatriske forskere ville have opnået bedre resultater, hvis de havde brugt GPT-4, som det var tilfældet i dette oftalmologiske triage-studie.
De lovende resultater fik forskerne til at afslutte deres artikel med at sige, at "øjenlæger bør være forberedt på et nyt paradigme inden for levering af sundhedsydelser, når lægfolk henvender sig til AI-chatbots for at imødekomme personlige sundhedsbehov."
Hvis du spørger ChatGPT Plus om de problemer, du har med dit øje, ser det ud til, at den vil give dig lige så gode eller bedre råd, end læger i praktik vil. Bing Chat? Ikke så meget.



