
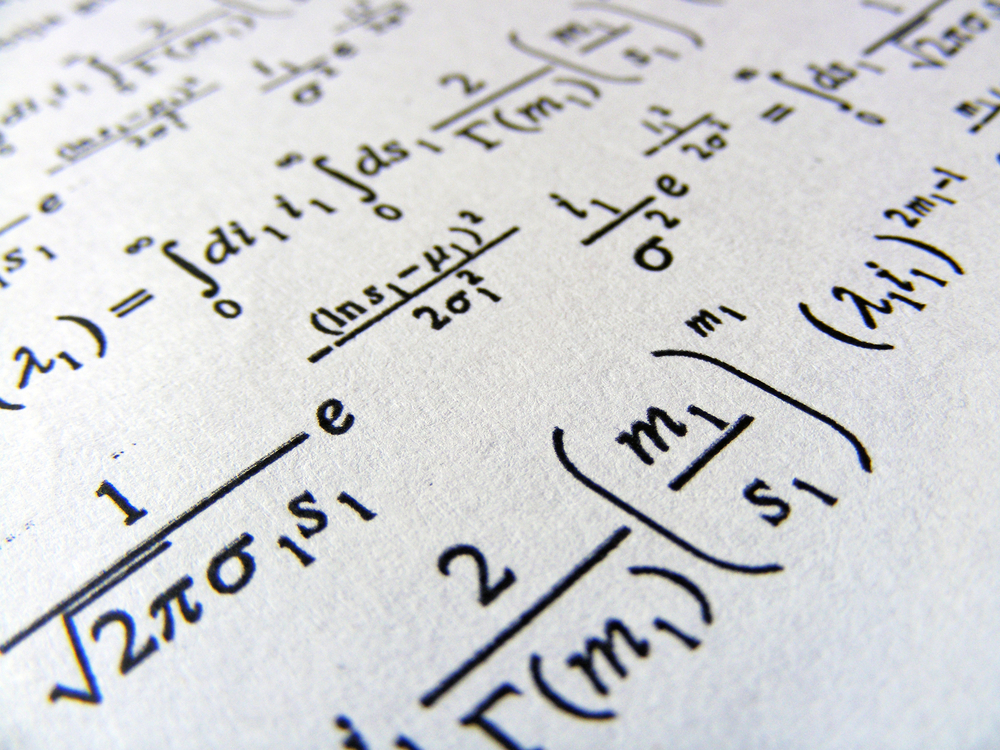
Meta har udviklet en ny AI-model kaldet Nougat, som på pålidelig vis kan omdanne videnskabelig tekst til maskinlæsbar tekst.
Hvis du nogensinde har prøvet at læse en videnskabelig forskningsartikel, så begynder du at forstå, hvorfor det er svært at behandle den elektronisk. De nuværende OCR-værktøjer (Optical Character Recognition) analyserer teksten linje for linje.
Det er fint nok til rent tekstbaserede dokumenter, men videnskabelige artikler tilføjer et niveau af kompleksitet, som disse standardværktøjer ikke kan håndtere.
Videnskabelige artikler indeholder matematiske og videnskabelige symboler og formler, der ofte tilføjes som subskriptioner eller superscripts. Selv de bedste OCR'er har problemer med at fange disse korrekt.
Det, der gør det endnu mere udfordrende, er, at mange af disse forskningsartikler er dårligt scannede, og at originalerne ikke længere er tilgængelige. Nougat, som står for Neural Optical Understanding for Academic Documents, er klar til at tage udfordringen op.
I stedet for at scanne linje for linje behandler Nougat hele siden ved hjælp af en variant af Meta's Vision Transformer til billedanalyse. Modellen blev trænet på et datasæt med artikler udgivet på PubMed Central og arXiv, som havde tilsvarende LaTeX-kildekode.
LaTeX er software, der bruges til at skrive videnskabelige artikler, som kræver komplekse formler og matematiske symboler. Modellen blev trænet ved at se på billedet af papiret og sammenligne det med den kode, der genererede den komplekse tekst.
Her er et eksempel på et af Metas eksperimenter med at digitalisere et gammelt forskningspapir.

Kilde: Meta
Der er nogle mere imponerende eksempler på Forskningsside på Facebook.
Nougat er ikke perfekt, men den opnåede stadig en BLEU-score på over 91% og en nøjagtighed på over 96% med løbende tekst. BLEU-scoren måler ligheden mellem den maskinoversatte tekst og et sæt referenceoversættelser af høj kvalitet.
For formler og tabeller gik det lidt dårligere med en nøjagtighed på lidt over 75%. Det er stadig meget bedre end konkurrerende modeller som GROBID, der kun formår at ramme rigtigt i 11% af tilfældene.
Der er millioner af forskningssider, som ikke kan indekseres eller søges i, fordi de kun kan læses effektivt af mennesker. Nougat ændrer på det ved at gøre det muligt at konvertere selv dårligt scannede forsknings-PDF'er til maskinlæsbar tekst.
Som med så mange af de andre nye værktøjer har Meta gjort dette frit tilgængeligt. tilgængelig på GitHub. Der kan dog være en vis grad af egeninteresse i denne udvikling. Når gamle forskningsartikler er maskinlæsbare, bliver de tilgængelige for træning af andre AI-modeller.
Det bliver interessant at se, hvilke forsvundne forskningsperler der bliver genopdaget ved hjælp af Nougat.



