

En undersøgelse foretaget af psykologer på UCLA har vist, at GPT-3 er omtrent lige så god som universitetsstuderende til at løse ræsonnementsproblemer.
Vi ved, at LLM'er som GPT-3 er gode til at generere svar baseret på de data, de er blevet trænet på, men deres evne til at ræsonnere er tvivlsom. Analogisk ræsonnement er den evne, mennesker har til at tage det, vi lærer af en ikke-relateret erfaring, og anvende det på et problem, vi ikke har stået over for før.
Det er den evne, du har brug for, når du skal besvare et spørgsmål, du aldrig har set før. Du kan ræsonnere dig frem til det på baggrund af tidligere problemer, du har løst. Og ud fra forskningen ser det ud til, at GPT-3 også har udviklet den evne.
Den Forskere fra UCLA sætte GPT-3 til at arbejde på et sæt problemer, der ligner Raven's Progressive Matrices som går ud på at forudsige det næste billede i en serie af billeder. Her er en nem opgave, som du kan prøve.
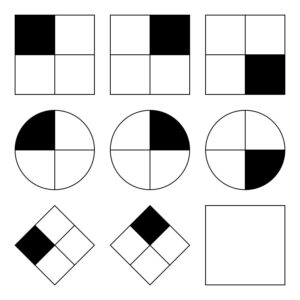
GPT-3 var i stand til at klare sig i forhold til de 40 UCLA-studerende, der blev bedt om at tage den samme test. AI'en svarede rigtigt i 80% af tilfældene, mens de 40 studerende havde et gennemsnit på omkring 60%. De bedste studerende scorede omtrent det samme som GPT-3 gjorde.
UCLA-psykologiprofessor Hongjing Lu, undersøgelsens hovedforfatter, sagde: "Overraskende nok klarede GPT-3 sig ikke kun omtrent lige så godt som mennesker, men den begik også lignende fejl."
Forskerne bad også GPT-3 om at løse nogle ordassociationsproblemer. For eksempel: "'Bil' er til 'vej' som 'båd' er til hvilket ord?". Svaret er naturligvis "vand", men den slags spørgsmål kan være vanskelige for en AI.
Forskerne troede i hvert fald, at det kunne være svært. Det viser sig, at GPT-3 klarede sig bedre end gennemsnittet af collegeansøgere i deres SAT-test.
GPT-3 kæmper med problemer, der er lette for mennesker
Hvad AI-modeller kæmper med, er problemer, der kræver en visuel forståelse af det fysiske rum. Hvis du præsenterer GPT-3 for en liste med værktøjer som en hammer, et søm og et billede, er den ikke i stand til at komme med den indlysende løsning til at hænge billedet op på væggen.
Den slags problemer er nemme for mennesker at løse, fordi vi kan se, holde og føle fysiske genstande i et rum, vi befinder os i. Disse erfaringer gør det nemt for vores hjerner at lære og løse problemer på en måde, som AI-modeller ikke kan. Når det er sagt, bliver GPT-4 bedre til denne form for ræsonnement nu.
Mens forskerne kunne måle GPT-3's ydeevne, har de ingen idé om den "tankeproces", den følger for at få svarene. Følger den en lignende tankeproces som mennesker, eller gør den noget helt andet? Da GPT-3 er en lukket model, er det ikke muligt at kigge under motorhjelmen for at se, hvad der sker.
Det overraskende resultat af denne forskning er, at GPT-3 ser ud til at være i stand til at løse nye problemer uden nogen direkte træning. Det er helt i tråd med, hvordan mennesker løser nye problemer. GPT-4 forventes at klare sig endnu bedre til disse problemer, og hvem ved, hvilke andre "tænkeevner" der kan dukke op med flere tests.
Mens rumlig ræsonnering er en udfordring for LLM'er, kan disse udfordringer løses med visuelle modeller som f.eks. Googles RT-2 som blev annonceret for nylig. Når AI-modeller kan begynde at "se" og interagere fysisk med deres omgivelser, vil deres evne til at løse problemer blive eksponentielt forbedret.



