

En ny undersøgelse viser, at træning af AI-billedgeneratorer med AI-genererede billeder i sidste ende fører til en betydelig reduktion af outputkvaliteten.
Baraniuk og hans team demonstrerede, hvordan denne problematiske AI-træningssløjfe påvirker generative AI'er, herunder StyleGAN og diffusionsmodeller. Disse er blandt de modeller, der bruges til AI-billedgeneratorer som Stable Diffusion, DALL-E og MidJourney.
I deres eksperimentTeamet trænede AI'erne på enten AI-genererede eller virkelige billeder. 70.000 rigtige menneskeansigter fra Flickr.
Når hver AI blev trænet på sine egne AI-genererede billeder, begyndte StyleGAN-billedgeneratorens output at vise forvrængede og bølgede visuelle mønstre, mens diffusionsbilledgeneratorens output blev mere uskarpt.
I begge tilfælde resulterede træning af AI'er på AI-genererede billeder i et tab af kvalitet.
En af de undersøgelse forfatterne, Richard Baraniuk fra Rice University i Texas, advarer: "Der vil være en glidebane til at bruge syntetiske data, enten bevidst eller ubevidst."
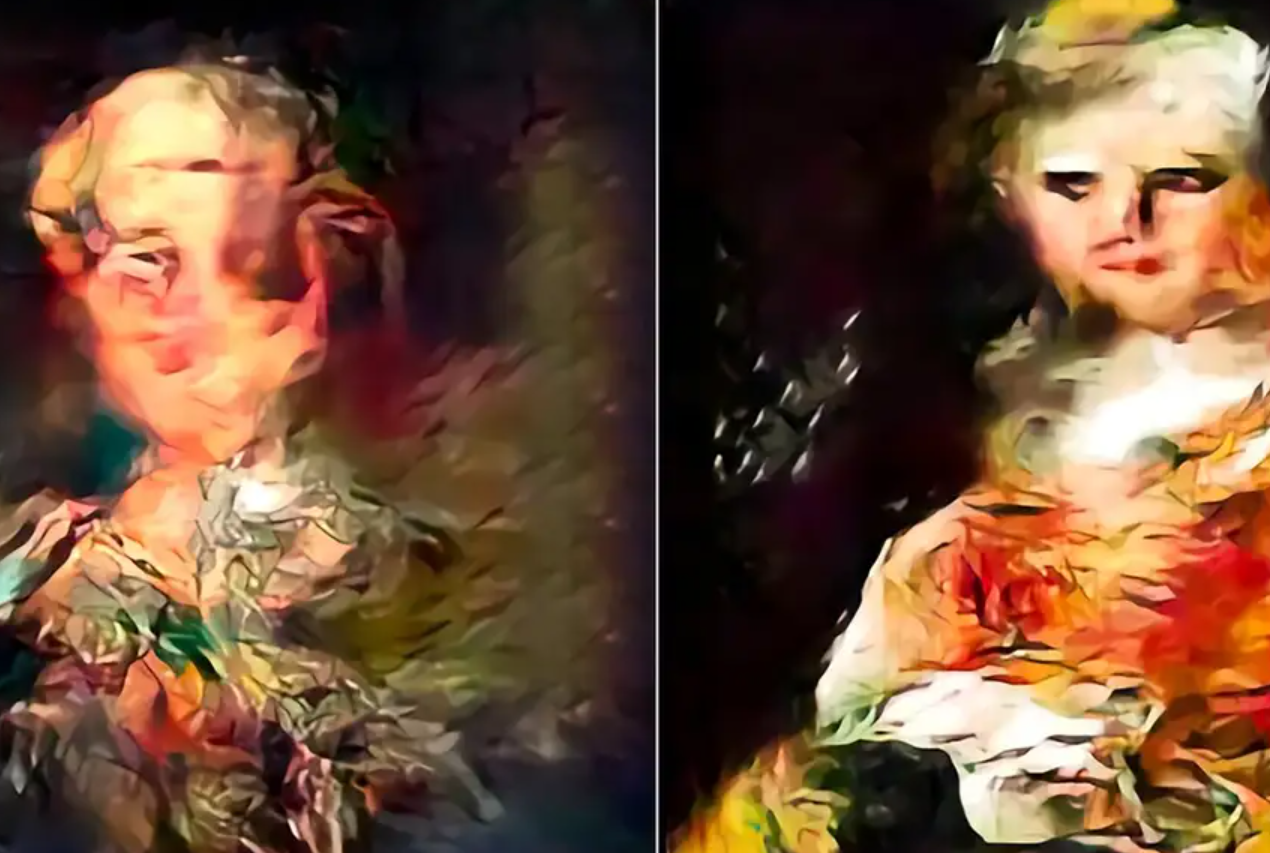
Selvom faldet i billedkvalitet blev reduceret ved at vælge AI-genererede billeder af højere kvalitet til træning, førte det til et tab af billeddiversitet.
Forskerne forsøgte også at inkorporere et fast sæt rigtige billeder i træningssæt, der primært indeholdt AI-genererede billeder, en metode, der nogle gange bruges til at supplere små træningssæt.
Men det forsinkede kun faldet i billedkvalitet - det virker uundgåeligt, at jo mere AI-genereret data, der kommer ind i træningsdatasættene, jo dårligere bliver resultatet. Det er bare et spørgsmål om hvornår.
Rimelige resultater blev opnået, da hver AI blev trænet på en blanding af AI-genererede billeder og et konstant skiftende sæt af autentiske billeder. Det hjalp med at bevare billedernes kvalitet og mangfoldighed.
Det er en udfordring at finde en balance mellem kvantitet og kvalitet - syntetiske billeder er potentielt ubegrænsede i forhold til rigtige billeder, men det har sin pris at bruge dem.
AI'er er ved at løbe tør for data
AI'er er datahungrende, men autentiske data af høj kvalitet er en begrænset ressource.
Resultaterne i denne forskning er et ekko lignende undersøgelser for tekstgenereringhvor AI-resultater har en tendens til at lide, når modeller trænes på AI-genereret tekst.
Forskerne fremhæver, at mindre organisationer med begrænset mulighed for at indsamle autentiske data står over for de største udfordringer med at filtrere AI-genererede billeder fra deres datasæt.
Problemet forstærkes desuden af, at internettet bliver oversvømmet med AI-genereret indhold, hvilket gør det utroligt vanskeligt at afgøre, hvilken type data modellerne er trænet på.
Sina Alemohammad fra Rice University foreslår, at det kan hjælpe at udvikle vandmærker til at identificere AI-genererede billeder, men advarer om, at oversete skjulte vandmærker kan forringe kvaliteten af AI-genererede billeder.
Alemohammad konkluderer: "Du er forbandet, hvis du gør det, og forbandet, hvis du ikke gør det. Men det er helt sikkert bedre at vandmærke billedet end ikke at gøre det."
De langsigtede konsekvenser af, at AI forbruger sit output, diskuteres heftigt, men lige nu er AI-udviklere nødt til at finde løsninger for at sikre kvaliteten af deres modeller.



