

OpenAI-chef Sam Altman langede ud efter EU og antydede, at EU's udkast til en AI-lov var overregulerende og umulig at opfylde. Få dage senere tweetede han, at OpenAI er begejstret for at fortsætte sine aktiviteter i EU.
Altman har rejst rundt i Europa og mødt politikere fra Tyskland, Frankrig, Spanien, Polen og Storbritannien. Men han aflyste efter sigende en aftale i Bruxelles, hvor lovgiverne er ved at udarbejde EU's AI Act.
Han har tidligere udtalt, at OpenAI vil kæmpe for at overholde loven: "Hvis vi kan overholde den, gør vi det, og hvis vi ikke kan, holder vi op med at arbejde. Vi vil forsøge. Men der er tekniske grænser for, hvad der er muligt."
Efter en del modreaktioner på de sociale medier syntes Altman at vende om på sine kommentarer: "Vi er glade for at fortsætte med at arbejde her og har selvfølgelig ingen planer om at forlade stedet."
meget produktiv uge med samtaler i europa om, hvordan man bedst regulerer AI! vi er glade for at kunne fortsætte med at arbejde her og har selvfølgelig ingen planer om at forlade stedet.
- Sam Altman (@sama) 26. maj 2023
Altman havde tidligere fortalte Reuters"Det nuværende udkast til EU's AI-lov ville være overregulerende, men vi har hørt, at det vil blive trukket tilbage."
EU reagerede - den hollandske MEP Kim van Sparrentak sagde, at de lovgivere, der udarbejder AI-loven, "ikke bør lade sig afpresse af amerikanske virksomheder".
Hun fortsatte med at sige: "Hvis OpenAI ikke kan overholde de grundlæggende krav til datastyring, gennemsigtighed og sikkerhed, så er deres systemer ikke egnede til det europæiske marked."
AI Act kan placere store sprogmodeller (LLM'er) i en "højrisiko"-kategori
EU's AI Act definerer forskellige kategorier af AI, herunder en "højrisiko"-kategori, der er underlagt strenge regler for gennemsigtighed og overvågning. Dette synes at være centrum for Altmans frygt.
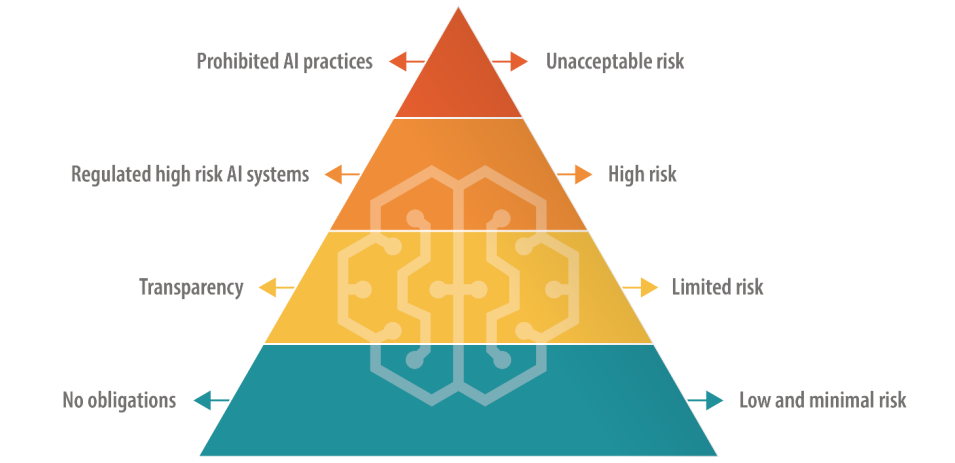
I det nuværende udkast skal virksomheder, der anvender højrisiko-AI, oplyse om alt ophavsretligt beskyttet materiale, der indgår i træningsdata og logaktiviteter, for at sikre reproducerbarhed og sporbarhed af output. Det kan blive dyrt og besværligt for mindre AI-virksomheder.
Ophavsretligt beskyttet materiale er stadig et stridspunkt
OpenAI er langt fra en åben bog, når det gælder ophavsretligt beskyttet materiale i deres træningsdata.
Det har vist sig, at AI'en gentage linjer fra flere romaner, bl.a. Harry Potter og Game of Thrones. Forskere foreslår Dette skyldes sandsynligvis, at passager fra bøger ofte er offentligt tilgængelige.
Der er mange verserende copyright-relaterede retssager mod OpenAI, Microsoft og skaberne bag billedgeneratorer som Midt på rejsen. Lige nu kender vi simpelthen ikke omfanget af AI's brug af copyright-data og metoderne til at hente dem.
Det vil EU lave om på ved at indføre regler om gennemsigtighed, som kan ændre, hvordan AI'er trænes, og dermed også deres præstationer.
Vi lever måske i en ureguleret AI-boble, som er ved at briste.



