

Förenade Arabemiratens Technology Innovation Institute (TII) släppte sin Falcon 180B LLM på Hugging Face förra veckan och den levererade imponerande prestanda i tidiga tester.
Modellen, som är öppet tillgänglig för forskare och kommersiella användare, är resultatet av en växande AI-industri i Mellanöstern.
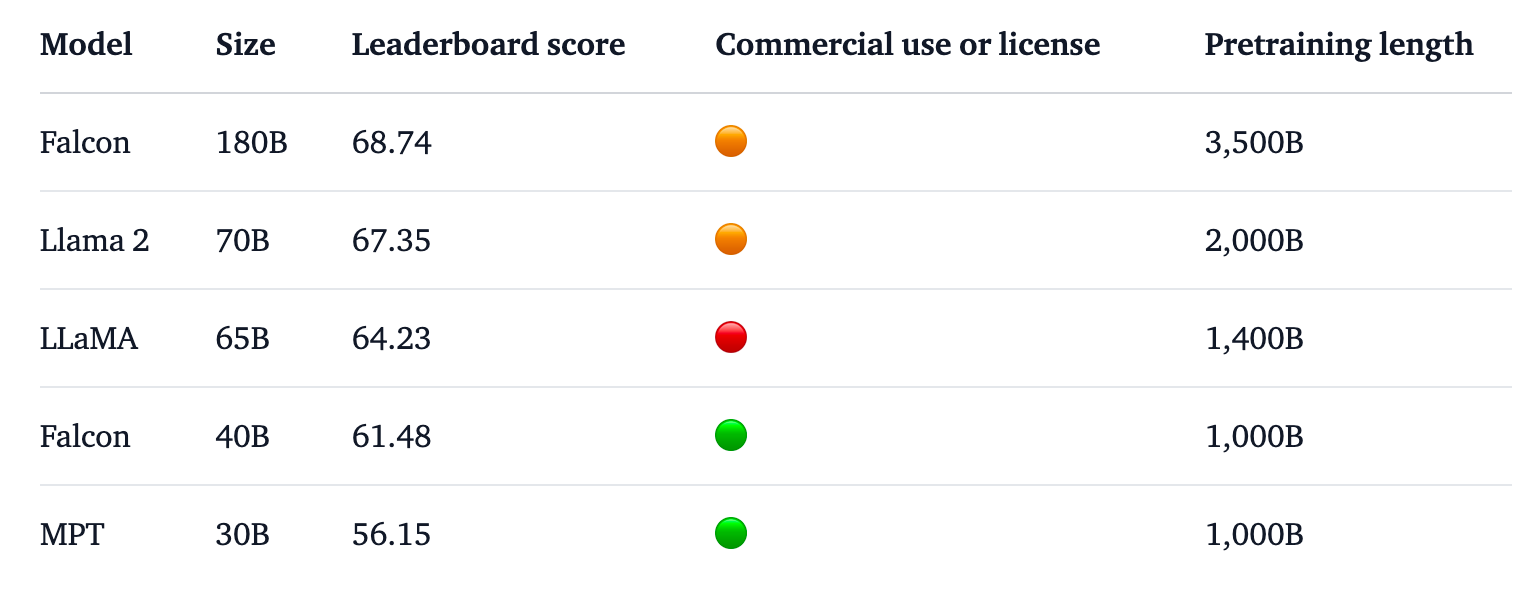
Falcon 180B är 2,5 gånger större än Metas Lama 2 och tränades med 4 gånger mer beräkningskraft. TII tränade modellen på massiva 3,5 biljoner tokens. Det är den unika datasetmetoden som till stor del är ansvarig för modellens imponerande prestanda.
För att träna en modell behöver du inte bara mycket data, du behöver vanligtvis mycket kurerad data av god kvalitet. Det kostar mycket pengar att producera och det finns inte många riktigt stora kuraterade datamängder som är allmänt tillgängliga. TII bestämde sig för att prova ett nytt tillvägagångssätt för att undvika behovet av kurering.
I juni använde forskare noggrann filtrering och deduplicering av allmänt tillgängliga CommonCrawl-data för att skapa RefinedWeb-datasetet. Det här datasetet var inte bara enklare att producera, utan det ger också bättre prestanda än att bara använda kuraterade korpusar eller webbdata.
Falcon 180B tränades på hela 3,5 biljoner tokens i RefinedWeb-datasetet, vilket är betydligt mer än de 2 biljoner tokens som fanns i Llama 2:s förträningsdataset.
Falcon 180B prestanda
Falcon 180B toppar Hugging Face-rankingen för LLM-utbildningar med öppen tillgång. Modellen överträffar Llama 2, den tidigare ledaren, på ett antal riktmärken inklusive resonemang, kodning, färdighet och kunskapstester.
Falcon 180B får även höga poäng när den jämförs med slutna, proprietära modeller. Den rankas strax efter GPT-4 och är i nivå med Googles PaLM 2 Large, som är dubbelt så stor som Falcon 180B.
Källa: Kramande ansikte
TII säger att trots den redan imponerande prestandan med sin förtränade modell, avser man "att tillhandahålla alltmer kapabla versioner av Falcon i framtiden, baserat på förbättrade dataset och RLHF/RLAIF".
Du kan prova en chattversion av modellen med detta Demo av Falcon 180B på Hugging Face.
Chattversionen är finjusterad och sanerad, men basmodellen har ännu inte några skyddsräcken för anpassning. TII sade att eftersom den ännu inte hade gått igenom en finjustering eller anpassningsprocess kunde den ge "problematiska" svar.
Det kommer att ta lite tid att få det så pass anpassat att det kan användas kommersiellt med tillförsikt.
Trots detta visar den här modellens imponerande prestanda att det finns möjligheter till förbättringar utöver att bara skala upp dataresurserna.
Falcon 180B visar att mindre modeller som tränas på dataset av god kvalitet kan vara en mer kostnadseffektiv och ändamålsenlig inriktning för AI-utvecklingen.
Lanseringen av denna imponerande modell understryker den kometartade tillväxten inom AI-utveckling i Mellanösterntrots den senaste tidens exportrestriktioner för GPU:er till regionen.
Eftersom företag som TII och Meta fortsätter att släppa sina kraftfulla modeller under licenser med öppen tillgång, kommer det att bli intressant att se vad Google och OpenAI gör för att driva antagandet av sina slutna modeller.
Skillnaden i prestanda mellan open access och proprietära modeller verkar definitivt minska.



