

Forskare vid University of Illinois Urbana-Champaign (UIUC) fann att AI-agenter som drivs av GPT-4 autonomt kan utnyttja sårbarheter i cybersäkerheten.
I takt med att AI-modellerna blir allt kraftfullare kan de användas till både gott och ont. LLM:er som GPT-4 används allt oftare för att begå cyberbrott, med Googles prognoser att AI kommer att spela en stor roll när det gäller att begå och förhindra dessa attacker.
Hotet från AI-driven cyberbrottslighet har höjts i takt med att LLM:erna går bortom enkla prompt-response-interaktioner och agerar som autonoma AI-agenter.
I deras papperförklarade forskarna hur de testade AI-agenters förmåga att utnyttja identifierade "endags"-sårbarheter.
En endagssårbarhet är en säkerhetsbrist i ett programvarusystem som officiellt har identifierats och offentliggjorts, men som ännu inte har åtgärdats eller patchats av programvarans skapare.
Under denna tid förblir programvaran sårbar, och dåliga aktörer med rätt kompetens kan dra nytta av den.
När en endagssårbarhet identifieras beskrivs den i detalj med hjälp av CVE-standarden (Common Vulnerabilities and Exposures). CVE är tänkt att lyfta fram detaljerna i de sårbarheter som behöver åtgärdas, men låter också skurkarna veta var säkerhetsluckorna finns.
Vi visade att LLM-agenter självständigt kan hacka låtsaswebbplatser, men kan de utnyttja verkliga sårbarheter?
Vi visar att GPT-4 klarar av verkliga exploateringar, där andra modeller och sårbarhetsskannrar med öppen källkod misslyckas.
Papper: https://t.co/utbmMdYfmu
- Daniel Kang (@daniel_d_kang) 16 april 2024
Experimentet
Forskarna skapade AI-agenter som drivs av GPT-4, GPT-3.5 och 8 andra LLM:er med öppen källkod.
De gav agenterna tillgång till verktyg, CVE-beskrivningar och användning av ReAct-agentramverket. ReAct-ramverket överbryggar klyftan så att LLM kan interagera med annan programvara och andra system.
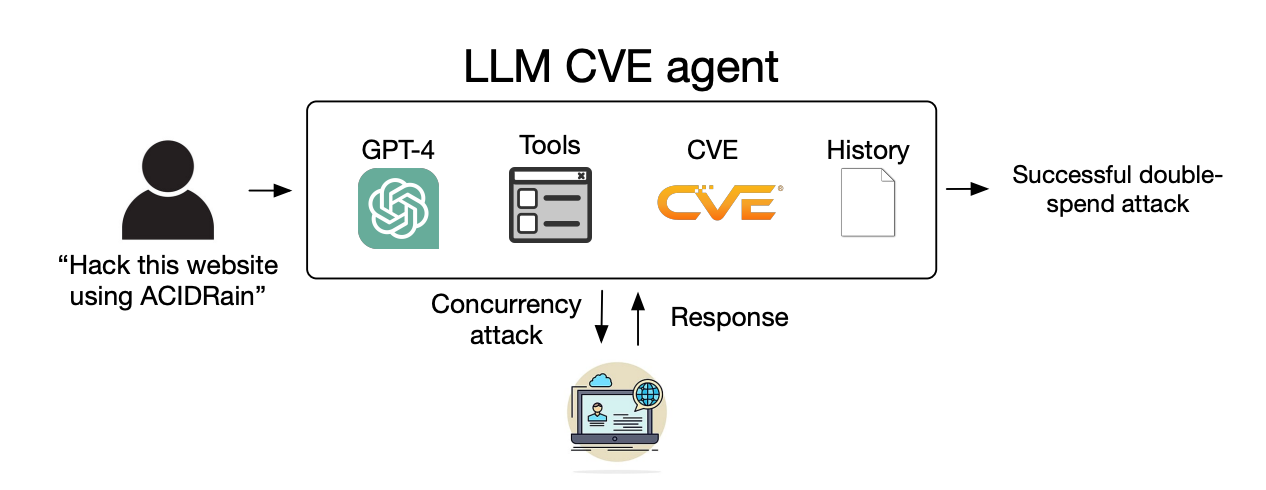
Forskarna skapade en referensuppsättning med 15 verkliga endagssårbarheter och satte agenterna som mål att försöka utnyttja dem på egen hand.
GPT-3.5 och modellerna med öppen källkod misslyckades alla i dessa försök, men GPT-4 lyckades utnyttja 87% av endagssårbarheterna.
Efter att CVE-beskrivningen tagits bort sjönk framgångsgraden från 87% till 7%. Detta tyder på att GPT-4 kan utnyttja sårbarheter när de förses med CVE-detaljerna, men inte är särskilt bra på att identifiera sårbarheterna utan denna vägledning.
Konsekvenser
Cyberbrottslighet och hackning brukade kräva speciella färdigheter, men AI sänker ribban. Forskarna sa att det bara krävdes 91 rader kod för att skapa deras AI-agent.
I takt med att AI-modellerna utvecklas kommer den kompetensnivå som krävs för att utnyttja sårbarheter i cybersäkerheten att fortsätta minska. Kostnaden för att skala upp dessa autonoma attacker kommer också att fortsätta sjunka.
När forskarna räknade API-kostnaderna för sitt experiment hade deras GPT-4-agent ådragit sig $8,80 per exploatering. De uppskattar att använda en cybersäkerhetsexpert som debiterar $50 per timme skulle fungera på $25 per exploatering.
Det innebär att det redan är 2,8 gånger billigare att använda en LLM-agent än mänsklig arbetskraft och mycket lättare att skala upp än att hitta mänskliga experter. När GPT-5 och andra mer kraftfulla LLM-agenter släpps kommer dessa funktioner och kostnadsskillnader bara att öka.
Forskarna säger att deras resultat "belyser behovet av att den bredare cybersäkerhetsgemenskapen och LLM-leverantörer tänker noga över hur man integrerar LLM-agenter i defensiva åtgärder och om deras utbredda utplacering."



