

I takt med att den generativa AI-eran går framåt har ett stort antal företag anslutit sig till kampen, och modellerna i sig har blivit alltmer varierade.
Mitt i denna AI-boom har många företag presenterat sina modeller som "open source", men vad innebär det egentligen i praktiken?
Begreppet öppen källkod har sina rötter i mjukvaruutvecklingsvärlden. Traditionell programvara med öppen källkod gör källkoden fritt tillgänglig för alla som vill se, ändra och distribuera den.
I grund och botten är öppen källkod en samarbetsform för kunskapsdelning som drivs av mjukvaruinnovation, vilket har lett till utvecklingar som operativsystemet Linux, webbläsaren Firefox och programmeringsspråket Python.
Det är dock långt ifrån okomplicerat att tillämpa öppen källkod på dagens massiva AI-modeller.
Dessa system tränas ofta på stora datamängder som innehåller terabyte eller petabyte av data, med hjälp av komplexa neurala nätverksarkitekturer med miljarder parametrar.
De dataresurser som krävs kostar miljontals dollar, talangerna är knappa och immateriella rättigheter är ofta väl skyddade.
Vi kan se detta i OpenAI, som, precis som namnet antyder, tidigare var ett AI-forskningslaboratorium som till stor del ägnade sig åt öppen forskning.
Det är dock etos snabbt urholkad när företaget kände lukten av pengar och behövde attrahera investeringar för att nå sina mål.
Varför är det så? Eftersom produkter med öppen källkod inte är inriktade på vinst, och AI är dyrt och värdefullt.
Men i takt med att generativ AI har exploderat släpper företag som Mistral, Meta, BLOOM och xAI modeller med öppen källkod för att främja forskningen och samtidigt förhindra att företag som Microsoft och Google får för stort inflytande.
Men hur många av dessa modeller är verkligen open source till sin natur, och inte bara till namnet?
Klargöra hur öppna open source-modeller verkligen är
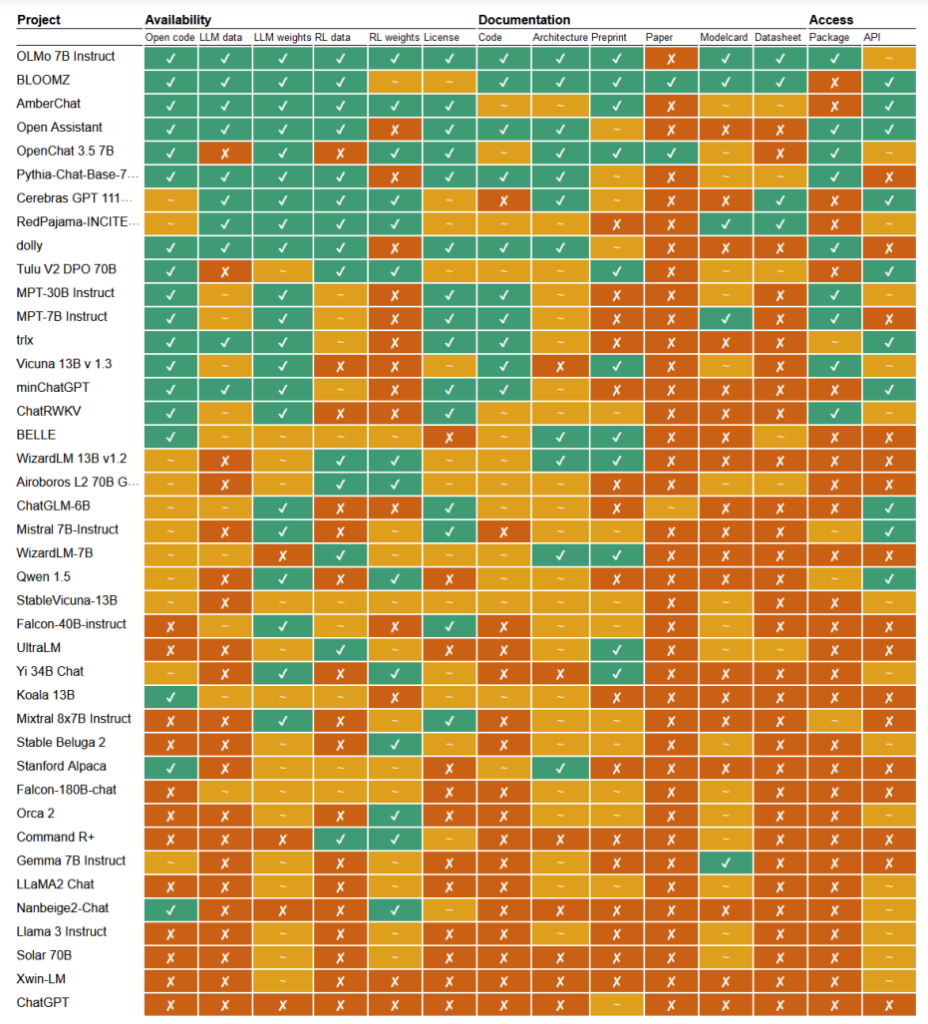
I en nyligen publicerad studieForskarna Mark Dingemanse och Andreas Liesenfeld från Radboud University i Nederländerna har analyserat ett stort antal framstående AI-modeller för att undersöka hur öppna de är. De studerade flera kriterier, till exempel tillgängligheten av källkod, träningsdata, modellvikter, forskningsartiklar och API: er.
Till exempel visade sig Metas LLaMA-modell och Googles Gemma helt enkelt vara "öppen vikt" - vilket innebär att den utbildade modellen släpps offentligt för användning utan full insyn i dess kod, utbildningsprocess, data och finjusteringsmetoder.
I den andra änden av spektrumet lyfte forskarna fram BLOOM, en stor flerspråkig modell som utvecklats av ett samarbete mellan över 1.000 forskare världen över, som ett exempel på AI med öppen källkod. Varje del av modellen är fritt tillgänglig för inspektion och vidare forskning.
I rapporten utvärderades över 30 modeller (både text och bild), men dessa visar på den enorma variationen bland dem som hävdar att de har öppen källkod:
- BloomZ (BigScience): Helt öppen i alla kriterier, inklusive kod, träningsdata, modellvikter, forskningsrapporter och API. Lyfts fram som ett exempel på AI med öppen källkod.
- OLMo (Allen Institute for AI): Öppen kod, utbildningsdata, vikter och forskningsrapporter. API endast delvis öppet.
- Mistral 7B-Instruct (Mistral AI): Öppna modellvikter och API. Kod och forskningsrapporter endast delvis öppna. Utbildningsdata är inte tillgängliga.
- Orca 2 (Microsoft): Delvis öppna modellvikter och forskningsrapporter. Kod, utbildningsdata och API stängt.
- Gemma 7B instruktör (Google): Delvis öppen kod och vikter. Utbildningsdata, forskningsartiklar och API stängt. Beskrivs som "öppen" av Google snarare än "öppen källkod".
- Llama 3 Instruktion (Meta): Delvis öppna vikter. Kod, utbildningsdata, forskningsrapporter och API stängt. Ett exempel på en modell med "öppna vikter" utan fullständig transparens.
Bristande öppenhet
Bristen på transparens kring AI-modeller, särskilt de som utvecklats av stora teknikföretag, väcker allvarliga farhågor om ansvarighet och tillsyn.
Utan full tillgång till modellens kod, träningsdata och andra viktiga komponenter blir det extremt utmanande att förstå hur dessa modeller fungerar och fattar beslut. Detta gör det svårt att identifiera och åtgärda potentiella fördomar, fel eller missbruk av upphovsrättsskyddat material.
Upphovsrättsintrång i AI-träningsdata är ett utmärkt exempel på de problem som uppstår på grund av denna brist på transparens. Många proprietära AI-modeller, som GPT-3.5/4/40/Claude 3/Gemini, är sannolikt tränade på upphovsrättsskyddat material.
Men eftersom utbildningsdata förvaras under lås och bom är det nästan omöjligt att identifiera specifika data i detta material.
The New York Times's ny stämning mot OpenAI visar på de verkliga konsekvenserna av denna utmaning. OpenAI anklagade NYT för att ha använt "prompt engineering"-attacker för att exponera träningsdata och förmå ChatGPT att ordagrant återge sina artiklar, och därmed bevisa att OpenAI:s träningsdata innehåller upphovsrättsskyddat material.
"The Times betalade någon för att hacka OpenAI:s produkter", säger OpenAI.
Ian Crosby, NYT:s chefsjurist, svarade: "Det som OpenAI på ett bisarrt sätt beskriver som 'hackning' är helt enkelt att OpenAI:s produkter används för att leta efter bevis på att de stulit och reproducerat The Times upphovsrättsskyddade verk. Och det är precis vad vi hittade."
Det är faktiskt bara ett exempel från en enorm stapel av stämningar som för närvarande är blockerade delvis på grund av AI-modellernas ogenomskinliga, ogenomträngliga natur.
Detta är bara toppen av isberget. Utan robusta åtgärder för transparens och ansvarsutkrävande riskerar vi en framtid där oförklarliga AI-system fattar beslut som har en djupgående inverkan på våra liv, vår ekonomi och vårt samhälle, men som inte granskas.
Uppmanar till öppenhet
Det har framförts krav på att företag som Google och OpenAI ska ge tillgång till sina modellers inre arbete för säkerhetsutvärdering.
Sanningen är dock att inte ens AI-företagen riktigt förstår hur deras modeller fungerar.
Detta kallas för "black box"-problemet och uppstår när man försöker tolka och förklara modellens specifika beslut på ett sätt som är begripligt för människor.
En utvecklare kan till exempel veta att en modell för djupinlärning är korrekt och ger bra resultat, men det kan vara svårt att exakt fastställa vilka funktioner som modellen använder för att fatta sina beslut.
Anthropic, som utvecklat Claude-modellerna, har nyligen genomförde ett experiment för att identifiera hur Claude 3 Sonnet fungerar och förklarade: "Vi behandlar oftast AI-modeller som en svart låda: något går in och ett svar kommer ut, och det är inte klart varför modellen gav just det svaret istället för ett annat. Det gör det svårt att lita på att modellerna är säkra: om vi inte vet hur de fungerar, hur kan vi då veta att de inte ger skadliga, partiska, osanna eller på annat sätt farliga svar? Hur kan vi lita på att de är säkra och tillförlitliga?"
Det är egentligen ett ganska anmärkningsvärt erkännande att skaparen av en teknik inte förstår sin produkt i AI-eran.
Detta antropiska experiment illustrerade att det är en utomordentligt svår uppgift att objektivt förklara utdata. Faktum är att Anthropic uppskattade att det skulle krävas mer datorkraft för att "öppna den svarta lådan" än för att träna själva modellen!
Utvecklare försöker aktivt bekämpa problemet med svarta lådor genom forskning som "Explainable AI" (XAI), som syftar till att utveckla tekniker och verktyg för att göra AI-modeller mer transparenta och tolkningsbara.
XAI-metoderna syftar till att ge insikter i modellens beslutsprocess, lyfta fram de mest inflytelserika funktionerna och generera förklaringar som är läsbara för människor. XAI har redan tillämpats på modeller som används i högintressanta tillämpningar såsom läkemedelsutvecklingdär det kan vara avgörande för säkerheten att förstå hur en modell fungerar.
Initiativ med öppen källkod är avgörande för XAI och annan forskning som syftar till att tränga igenom den svarta lådan och ge insyn i AI-modeller.
Utan tillgång till modellens kod, träningsdata och andra viktiga komponenter kan forskare inte utveckla och testa tekniker för att förklara hur AI-system verkligen fungerar och identifiera specifika data som de tränats på.
Regleringar kan göra situationen för öppen källkod ännu mer förvirrad
Europeiska unionens nyligen antagen AI-lag kommer att införa nya regler för AI-system, med bestämmelser som särskilt tar sikte på modeller med öppen källkod.
Enligt lagen kommer modeller med öppen källkod för allmänt bruk upp till en viss storlek att undantas från omfattande krav på transparens.
Som Dingemanse och Liesenfeld påpekar i sin studie är dock den exakta definitionen av "open source AI" enligt AI-lagen fortfarande oklar och kan bli en tvistefråga.
Lagen definierar för närvarande modeller med öppen källkod som de som släpps under en "fri och öppen" licens som gör det möjligt för användare att ändra modellen. Ändå specificerar den inte krav kring tillgång till utbildningsdata eller andra viktiga komponenter.
Denna tvetydighet lämnar utrymme för tolkning och potentiell lobbyverksamhet från företagsintressen. Forskarna varnar för att en förfining av definitionen av öppen källkod i AI-lagen "förmodligen kommer att utgöra en enda tryckpunkt som företagslobbyer och storföretag kommer att rikta in sig på".
Det finns en risk för att regelverket, utan tydliga och robusta kriterier för vad som utgör AI med öppen källkod, oavsiktligt kan skapa kryphål eller incitament för företag att ägna sig åt "open-washing" - att hävda öppenhet för de juridiska och PR-mässiga fördelarna men ändå hålla viktiga aspekter av sina modeller skyddade.
AI-utvecklingens globala karaktär innebär dessutom att olika regelverk i olika jurisdiktioner kan komplicera situationen ytterligare.
Om stora AI-tillverkare som USA och Kina har olika syn på kraven på öppenhet och transparens kan det leda till ett fragmenterat ekosystem där graden av öppenhet varierar kraftigt beroende på varifrån en modell kommer.
Författarna till studien betonar behovet av att tillsynsmyndigheter har ett nära samarbete med forskarvärlden och andra intressenter för att säkerställa att alla bestämmelser om öppen källkod i AI-lagstiftning bygger på en djup förståelse av tekniken och principerna om öppenhet.
Som Dingemanse och Liesenfeld konstaterar i en diskussion med naturen"Det är rimligt att säga att termen öppen källkod kommer att få en oöverträffad juridisk tyngd i de länder som omfattas av EU:s AI Act."
Hur detta utspelar sig i praktiken kommer att få stora konsekvenser för den framtida inriktningen på forskning och användning av AI.



