

Stanford University släppte sin AI Index Report 2024 där man konstaterade att AI:s snabba utveckling gör att jämförelser med människor blir allt mindre relevanta.
Den årsredovisning ger en omfattande inblick i trender och läget för AI-utvecklingen. Enligt rapporten förbättras AI-modellerna nu så snabbt att de riktmärken vi använder för att mäta dem blir alltmer irrelevanta.
Många branschriktmärken jämför AI-modeller med hur bra människor är på att utföra uppgifter. Benchmarken Massive Multitask Language Understanding (MMLU) är ett bra exempel.
Den använder flervalsfrågor för att utvärdera LLM:er i 57 ämnen, inklusive matematik, historia, juridik och etik. MMLU har varit det självklara AI-riktmärket sedan 2019.
Den mänskliga baslinjen på MMLU är 89,8%, och redan 2019 fick den genomsnittliga AI-modellen drygt 30%. Bara 5 år senare blev Gemini Ultra den första modellen som slog den mänskliga baslinjen med en poäng på 90,04%.
Rapporten konstaterar att nuvarande "AI-system rutinmässigt överträffar mänsklig prestanda på standardbenchmarks." Trenderna i diagrammet nedan verkar tyda på att MMLU och andra riktmärken behöver bytas ut.
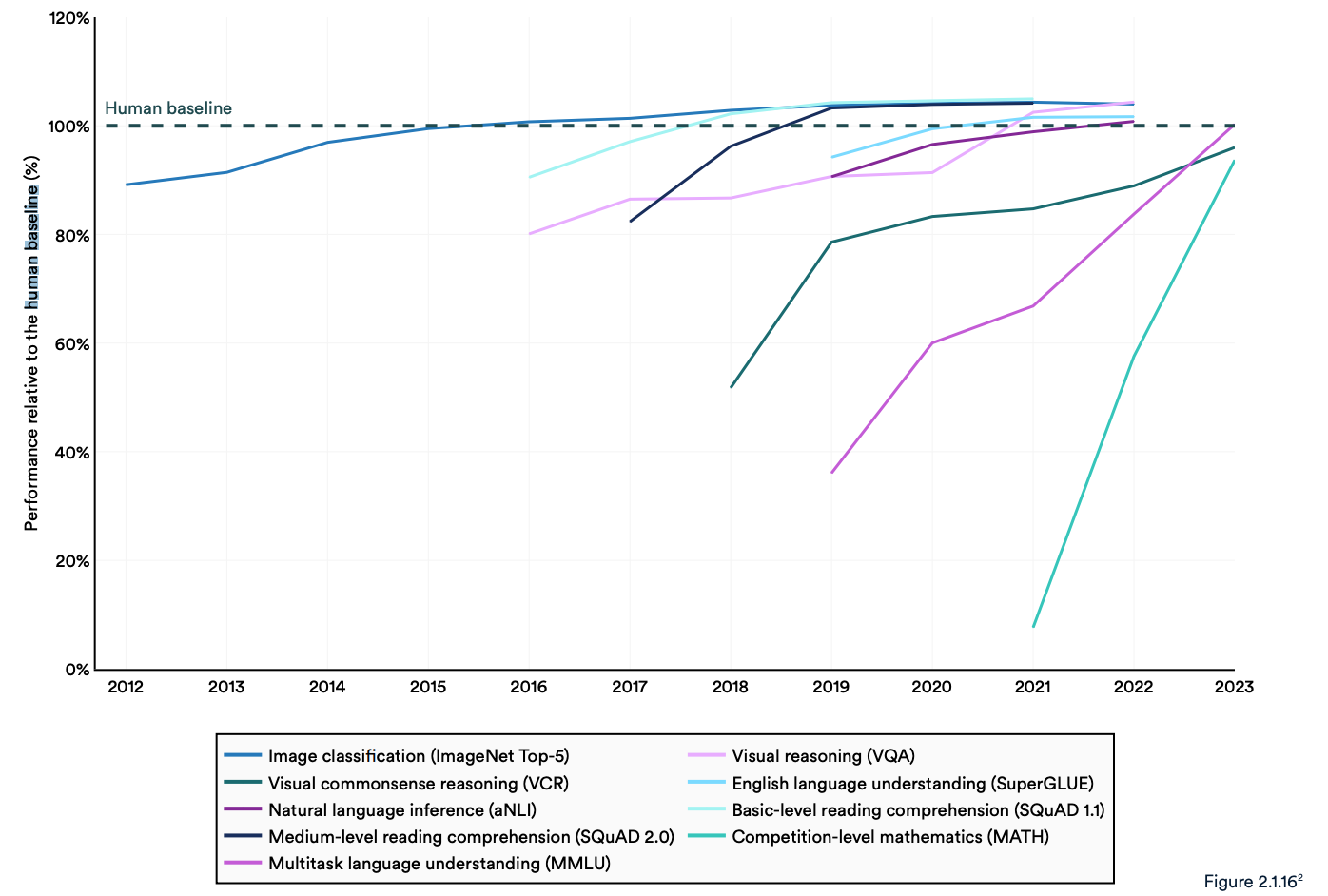
AI-modeller har nått prestandamättnad på etablerade benchmarks som ImageNet, SQuAD och SuperGLUE, så forskarna utvecklar mer utmanande tester.
Ett exempel är Graduate-Level Google-Proof Q&A Benchmark (GPQA), som gör att AI-modeller kan jämföras med riktigt smarta människor, snarare än med genomsnittlig mänsklig intelligens.
GPQA-testet består av 400 tuffa flervalsfrågor på forskarnivå. Experter som har eller håller på att doktorera svarar korrekt på frågorna 65% av gångerna.
I GPQA:s rapport står det att "högt kvalificerade validerare som inte är experter når endast 34% noggrannhet när de får frågor utanför sitt område, trots att de i genomsnitt tillbringar över 30 minuter med obegränsad tillgång till webben".
Förra månaden meddelade Anthropic att Claude 3 fick strax under 60% med 5-skott CoT prompting. Vi kommer att behöva ett större riktmärke.
Claude 3 får ~60% noggrannhet på GPQA. Det är svårt för mig att underskatta hur svåra dessa frågor är - bokstavliga doktorer (inom andra domäner än frågorna) med tillgång till internet får 34%.
Doktorander * i samma domän* (även med internetåtkomst!) får 65% - 75% noggrannhet. https://t.co/ARAiCNXgU9 pic.twitter.com/PH8J13zIef
- david rein (@idavidrein) 4 mars 2024
Utvärderingar och säkerhet för människor
I rapporten konstateras att AI fortfarande står inför betydande problem: "Den kan inte på ett tillförlitligt sätt hantera fakta, utföra komplexa resonemang eller förklara sina slutsatser."
Dessa begränsningar bidrar till en annan egenskap hos AI-systemet som enligt rapporten är dåligt mätt; AI-säkerhet. Vi har inga effektiva riktmärken som gör att vi kan säga: "Den här modellen är säkrare än den andra."
Det beror delvis på att det är svårt att mäta och delvis på att "AI-utvecklare saknar transparens, särskilt när det gäller att offentliggöra utbildningsdata och metoder".
I rapporten konstateras att en intressant trend i branschen är att låta människor utvärdera AI-prestanda i stället för att göra benchmark-tester.
Att rangordna en modells bildestetik eller prosa är svårt att göra med ett test. Som ett resultat av detta säger rapporten att "benchmarking långsamt har börjat skifta mot att införliva mänskliga utvärderingar som Chatbot Arena Leaderboard snarare än datoriserade rankningar som ImageNet eller SQuAD."
När AI-modellerna ser den mänskliga baslinjen försvinna i backspegeln kan känslan i slutändan avgöra vilken modell vi väljer att använda.
Trenderna pekar på att AI-modellerna så småningom kommer att bli smartare än oss och svårare att mäta. Snart kanske vi säger: "Jag vet inte varför, men jag tycker bättre om den här."



