

Vi hör mycket om AI-säkerhet, men betyder det att det är en viktig del av forskningen?
En ny studie från Georgetown University's Emerging Technology Observatory tyder på att AI-säkerhetsforskning trots allt bara upptar en liten minoritet av branschens forskningsfokus.
Forskarna analyserade över 260 miljoner vetenskapliga publikationer och fann att endast 2% av AI-relaterade artiklar som publicerades mellan 2017 och 2022 direkt behandlade ämnen relaterade till AI-säkerhet, etik, robusthet eller styrning.
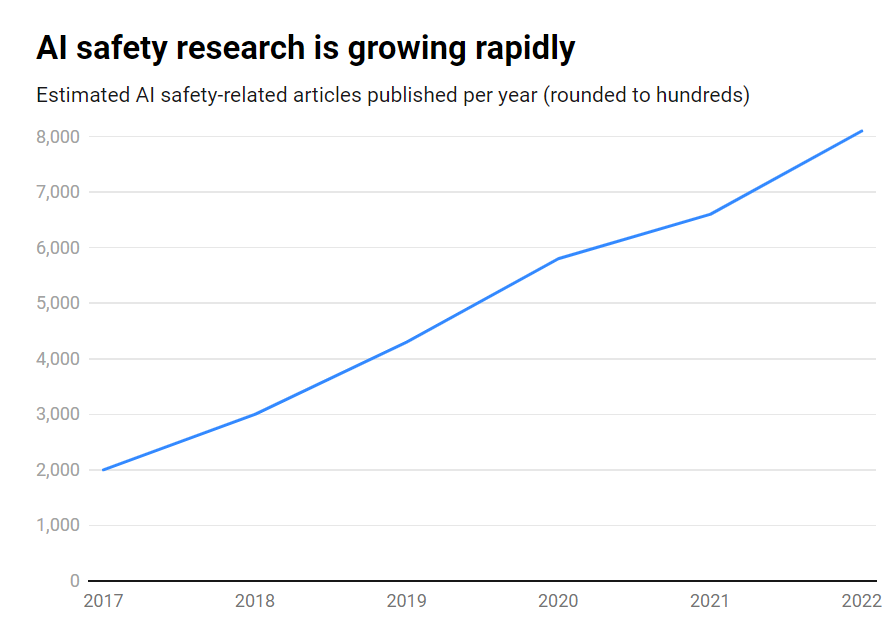
Även om antalet publikationer om AI-säkerhet ökade med imponerande 315% under den perioden, från cirka 1.800 till över 7.000 per år, är det fortfarande en perifer fråga.
Här är de viktigaste resultaten:
- Endast 2% av AI-forskningen under 2017-2022 fokuserade på AI-säkerhet
- AI-säkerhetsforskningen växte med 315% under samma period, men är mindre än den totala AI-forskningen
- USA ledande inom AI-säkerhetsforskning, medan Kina släpar efter
- Viktiga utmaningar är bland annat robusthet, rättvisa, transparens och bibehållen mänsklig kontroll
Många ledande AI-forskare och etiker har varnat för existentiella risker om artificiell allmän intelligens (AGI) utvecklas utan tillräckliga skyddsåtgärder och försiktighetsmått.
Föreställ dig ett AGI-system som kan förbättra sig självt rekursivt och snabbt överträffa mänsklig intelligens samtidigt som det strävar efter mål som inte stämmer överens med våra värderingar. Det är ett scenario som vissa hävdar skulle kunna utvecklas bortom vår kontroll.
Men det är ingen enkelriktad trafik. Faktum är att ett stort antal AI-forskare tror AI-säkerhet är överdrivet.
Utöver det tror vissa till och med att hypen har skapats för att hjälpa Big Tech att genomdriva regler och eliminera gräsrots- och Konkurrenter med öppen källkod.
Men även dagens snäva AI-system, som tränas på tidigare data, kan uppvisa fördomar, producera skadligt innehåll, kränka integriteten och användas på ett illvilligt sätt.
Så även om AI-säkerhet måste se in i framtiden måste den också hantera risker här och nu, vilket förmodligen är otillräckligt eftersom djupa förfalskningar, partiskhet och andra problem fortsätter att vara stora.
Effektiv forskning om AI-säkerhet måste ta itu med såväl kortsiktiga utmaningar som mer långsiktiga spekulativa risker.
USA leder forskningen om AI-säkerhet
När man går ner på djupet i data är USA den tydliga ledaren inom AI-säkerhetsforskning, med 40% av relaterade publikationer jämfört med 12% från Kina.
Kinas säkerhetsresultat ligger dock långt efter landets totala AI-forskning - medan 5% av den amerikanska AI-forskningen berörde säkerhet, gjorde endast 1% av Kinas det.
Man kan spekulera i att det är en mycket svår uppgift att undersöka kinesisk forskning. Dessutom har Kina varit proaktiv om reglering - kanske mer än i USA - så dessa uppgifter kanske inte ger landets AI-industri en rättvis bild.
På institutionsnivå är det Carnegie Mellon University, Google, MIT och Stanford som ligger i topp.
Men globalt sett producerade ingen organisation mer än 2% av det totala antalet säkerhetsrelaterade publikationer, vilket understryker behovet av en större och mer samlad insats.
Obalanser i säkerheten
Så vad kan man göra för att rätta till denna obalans?
Det beror på om man anser att AI-säkerhet är en akut risk på samma nivå som kärnvapenkrig, pandemier etc. Det finns inget entydigt svar på denna fråga, vilket gör AI-säkerhet till ett mycket spekulativt ämne med liten ömsesidig avtal mellan forskare.
Säkerhetsforskning och etik är också något av en tangentiell domän till maskininlärning, vilket kräver olika kompetensuppsättningar, akademiska bakgrunder etc., som kanske inte är välfinansierade.
För att komma till rätta med säkerhetsklyftan inom AI krävs också att man tar itu med frågor om öppenhet och sekretess inom AI-utvecklingen.
De största teknikföretagen bedriver omfattande intern säkerhetsforskning som aldrig har publicerats. I takt med att kommersialiseringen av AI tar fart blir företagen alltmer rädda om sina AI-genombrott.
OpenAI var till exempel ett kraftcentrum för forskning under sin första tid.
Företaget brukade göra djupgående oberoende granskningar av sina produkter, märkningsbias och risker - som t.ex. sexistiska fördomar i sitt CLIP-projekt.
Anthropic är fortfarande aktivt engagerad i forskning om AI-säkerhet för allmänheten och publicerar ofta studier om förspänning och jailbreaking.
DeepMind har också dokumenterat möjligheten att AI-modeller etablerar "emergent goals" och aktivt motsäger sina instruktioner eller blir motståndare till sina skapare.
På det hela taget har dock säkerheten fått stå tillbaka för framstegen, eftersom Silicon Valley lever efter sitt motto "move fast and break stuff".
Georgetown-studien visar att universitet, myndigheter, teknikföretag och forskningsfinansiärer måste satsa mer på AI-säkerhet och investera mer pengar i detta.
Vissa har också efterlyst en internationellt organ för AI-säkerhet, i likhet med Internationella atomenergiorganet (IAEA), som inrättades efter en rad kärnkraftsincidenter som gjorde ett djupgående internationellt samarbete obligatoriskt.
Kommer AI att behöva sin egen katastrof för att engagera den nivån av samarbete mellan stater och företag? Låt oss hoppas att så inte blir fallet.



