

Googles DeepMind lanserade Gecko, ett nytt riktmärke för omfattande utvärdering av AI-modeller för text-till-bild (T2I).
Under de senaste två åren har vi sett AI-bildgeneratorer som DALL-E och Midjourney blir successivt bättre för varje version som släpps.
Att avgöra vilken av de underliggande modeller som dessa plattformar använder som är bäst har dock i hög grad varit subjektivt och svårt att jämföra.
Att påstå att en modell är "bättre" än en annan är inte så enkelt. Olika modeller utmärker sig inom olika aspekter av bildgenerering. En kan vara bra på textrendering medan en annan kan vara bättre på objektinteraktion.
En viktig utmaning för T2I-modellerna är att följa varje detalj i uppmaningen och få den korrekt återgiven i den genererade bilden.
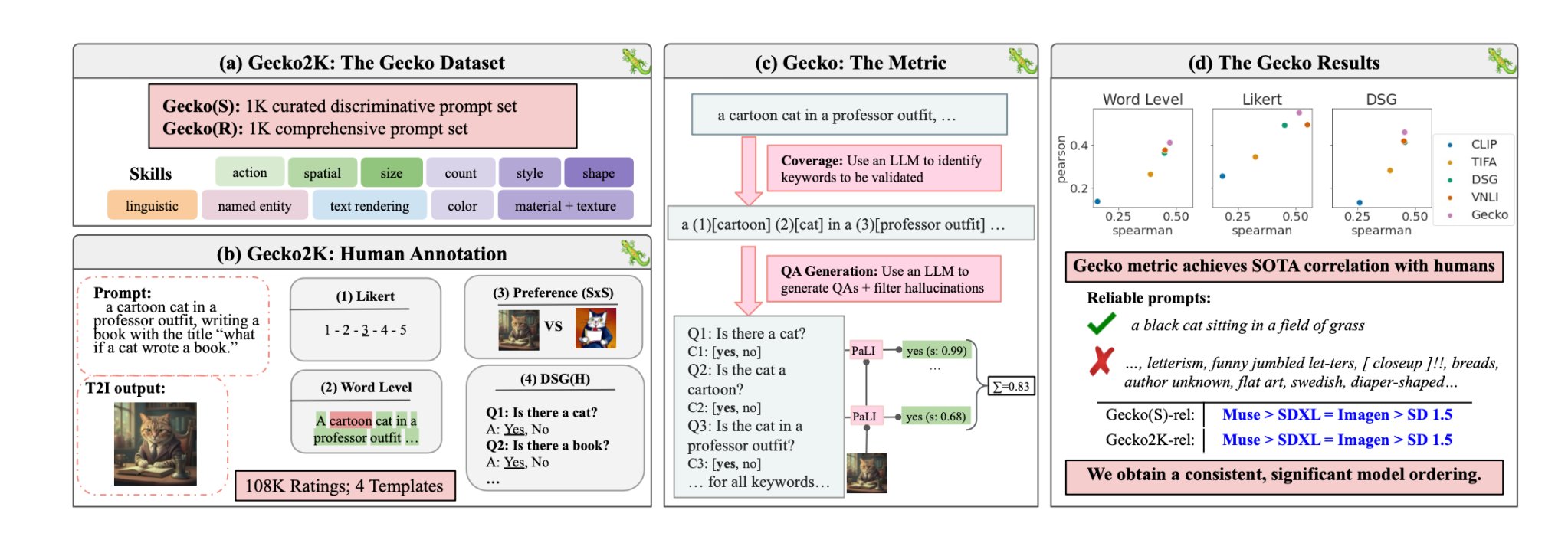
Med Gecko är DeepMind forskare har skapat en riktmärke som utvärderar T2I-modellernas kapacitet på samma sätt som människor gör.
Färdigheter
Forskarna definierade först ett omfattande dataset med färdigheter som är relevanta för T2I-generering. Dessa omfattar bland annat rumslig förståelse, handlingsigenkänning och textåtergivning. De delade vidare upp dessa i mer specifika delfärdigheter.
Till exempel kan underfärdigheterna för textåtergivning omfatta återgivning av olika teckensnitt, färger eller textstorlekar.
En LLM användes sedan för att generera uppmaningar för att testa T2I-modellens kapacitet för en specifik färdighet eller delfärdighet.
Detta gör det möjligt för skaparna av en T2I-modell att fastställa inte bara vilka färdigheter som är utmanande, utan också på vilken komplexitetsnivå en färdighet blir utmanande för deras modell.
Utvärdering mellan människa och bil
Gecko mäter också hur noggrant en T2I-modell följer alla detaljer i en fråga. Även här användes en LLM för att isolera viktiga detaljer i varje inmatningsfråga och sedan generera en uppsättning frågor relaterade till dessa detaljer.
Dessa frågor kan vara både enkla, direkta frågor om synliga element i bilden (t.ex. "Finns det en katt i bilden?") och mer komplexa frågor som testar förståelsen av scenen eller relationerna mellan objekt (t.ex. "Sitter katten ovanför boken?").
En VQA-modell (Visual Question Answering) analyserar sedan den genererade bilden och svarar på frågorna för att se hur exakt T2I-modellen anpassar sin utmatade bild till en inmatad uppmaning.
Forskarna samlade in över 100.000 mänskliga kommentarer där deltagarna poängsatte en genererad bild baserat på hur väl bilden stämde överens med specifika kriterier.
Människorna ombads att ta hänsyn till en specifik aspekt av inmatningsuppmaningen och poängsätta bilden på en skala från 1 till 5 baserat på hur väl den stämde överens med uppmaningen.
Med hjälp av de mänskligt kommenterade utvärderingarna som guldstandard kunde forskarna bekräfta att deras auto-eval-mått "är bättre korrelerat med mänskliga betyg än befintliga mått för vår nya dataset".
Resultatet är ett benchmarkingsystem som kan sätta siffror på specifika faktorer som gör att en genererad bild blir bra eller dålig.
Gecko poängsätter i princip utdatabilden på ett sätt som ligger nära hur vi intuitivt bestämmer om vi är nöjda med den genererade bilden eller inte.
Så vilken är den bästa text-till-bild-modellen?
I deras papperkom forskarna fram till att Googles Muse-modell slår Stable Diffusion 1.5 och SDXL i Gecko-jämförelsen. De kanske är partiska men siffrorna ljuger inte.



