

Trots de snabba framstegen inom LLM är vår förståelse för hur dessa modeller hanterar längre inmatningar fortfarande dålig.
Mosh Levy, Alon Jacoby och Yoav Goldberg, från Bar-Ilan University och Allen Institute for AI, undersökte hur prestandan hos stora språkmodeller (LLM) varierar med förändringar i längden på den inmatade text som de får bearbeta.
De utvecklade ett ramverk för resonemang specifikt för detta ändamål, vilket gjorde det möjligt för dem att analysera hur inputlängden påverkar LLM-resonemang i en kontrollerad miljö.
Frågeramen föreslog olika versioner av samma fråga, var och en innehållande den information som var nödvändig för att besvara frågan, utfylld med ytterligare, irrelevant text av varierande längd och typ.
Detta gör det möjligt att isolera ingångslängden som en variabel, vilket säkerställer att förändringar i modellens prestanda kan hänföras direkt till ingångslängden.
Viktiga resultat
Levy, Jacoby och Goldberg upptäckte att LLM:er uppvisar en anmärkningsvärd nedgång i resonemangsprestanda vid indatalängder långt under vad utvecklarna hävdar att de kan hantera. De dokumenterade sina resultat i denna studie.
Nedgången observerades konsekvent i alla versioner av datasetet, vilket tyder på ett systemfel i hanteringen av längre inmatningar snarare än ett problem som är knutet till specifika datasamplingar eller modellarkitekturer.
Som forskarna beskriver: "Våra resultat visar en märkbar försämring av LLM:s resonemangsprestanda vid mycket kortare inmatningslängder än deras tekniska maximum. Vi visar att försämringstrenden förekommer i alla versioner av vårt dataset, även om det är olika intensivt."

Studien visar också att traditionella mått som perplexitet, som ofta används för att utvärdera LLM-modeller, inte korrelerar med modellernas prestanda i resonemangsuppgifter med långa inmatningar.
Ytterligare undersökningar visade att den försämrade prestandan inte enbart berodde på förekomsten av irrelevant information (utfyllnad), utan observerades även när utfyllnaden bestod av duplicerad relevant information.
När vi håller ihop de två kärnspannen och lägger till text runt dem sjunker noggrannheten redan. När vi lägger till stycken mellan spännena sjunker resultaten ännu mer. Nedgången inträffar både när de texter vi lägger till liknar uppgiftstexterna och när de är helt annorlunda. 3/7 pic.twitter.com/c91l9uzyme
- Mosh Levy (@mosh_levy) 26 februari 2024
Detta tyder på att utmaningen för LLM ligger i att filtrera bort brus och den inneboende bearbetningen av längre textsekvenser.
Ignorera instruktioner
Ett kritiskt felområde som lyfts fram i studien är LLM:s tendens att ignorera instruktioner som är inbäddade i indata när indatans längd ökar.
Modellerna kan också ibland generera svar som indikerar osäkerhet eller brist på tillräcklig information, till exempel "Det finns inte tillräckligt med information i texten", trots att all nödvändig information finns.
Överlag verkar LLM:erna konsekvent ha svårt att prioritera och fokusera på viktiga informationsdelar, inklusive direkta instruktioner, när längden på inmatningen ökar.
Uppvisande av fördomar i svaren
Ett annat anmärkningsvärt problem var att modellernas svar blev alltmer snedvridna när indata blev längre.
I synnerhet var LLM:erna partiska mot att svara "Falskt" när längden på indata ökade. Denna förskjutning indikerar en skevhet i sannolikhetsuppskattning eller beslutsprocesser inom modellen, möjligen som en defensiv mekanism som svar på ökad osäkerhet på grund av längre inmatningslängder.
Benägenheten att gynna "falska" svar kan också återspegla en underliggande obalans i träningsdata eller en artefakt i modellernas träningsprocess, där negativa svar kan vara överrepresenterade eller associerade med sammanhang av osäkerhet och tvetydighet.
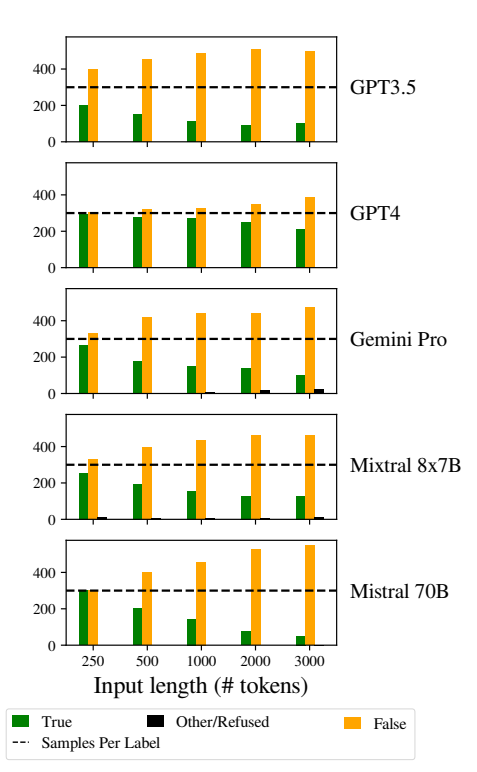
Denna partiskhet påverkar noggrannheten i modellernas resultat och väcker farhågor om LLM:s tillförlitlighet och rättvisa i tillämpningar som kräver nyanserad förståelse och opartiskhet.
Det är viktigt att implementera robusta strategier för upptäckt och begränsning av bias under modellens tränings- och finjusteringsfaser för att minska omotiverade bias i modellsvar.
Ett se till att träningsdataset är mångsidiga, balanserade och representativa för ett brett spektrum av scenarier kan också bidra till att minimera felaktigheter och förbättra modellgeneraliseringen.
Detta bidrar till andra nyligen genomförda studier som på liknande sätt belyser grundläggande problem i hur LLM-programmen fungerar, vilket leder till en situation där den "tekniska skulden" kan hota modellens funktionalitet och integritet över tid.



