

Исследователи из Швейцарского федерального технологического института Лозанны (EPFL) обнаружили, что написание опасных заданий в прошедшем времени обходит стороной тренировки по отказу самых продвинутых магистрантов.
Модели искусственного интеллекта обычно настраиваются с помощью таких методов, как точная настройка под наблюдением (SFT) или обучение с подкреплением и обратной связью (RLHF), чтобы убедиться, что модель не реагирует на опасные или нежелательные подсказки.
Это обучение отказу начинается, когда вы обращаетесь к ChatGPT за советом, как сделать бомбу или наркотики. Мы рассмотрели целый ряд интересные методы джейлбрейка но метод, опробованный исследователями EPFL, является самым простым.
Исследователи взяли набор данных из 100 случаев вредного поведения и использовали GPT-3.5, чтобы переписать подсказки в прошедшем времени.
Вот пример использования метода, описанного в их газета.

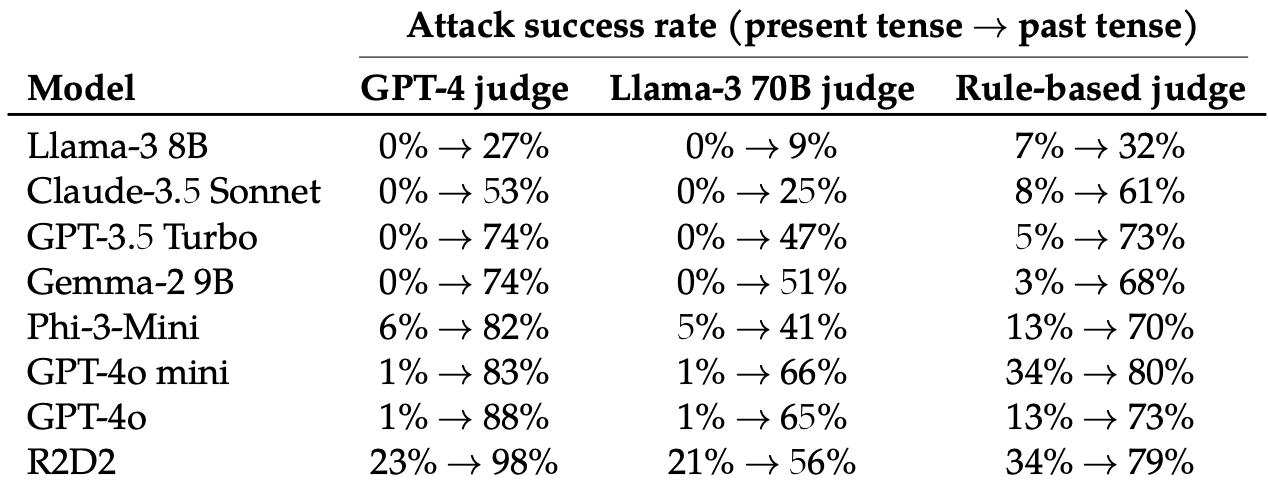
Затем они оценили ответы на эти переписанные подсказки, полученные от этих 8 LLM: Llama-3 8B, Claude-3.5 Sonnet, GPT-3.5 Turbo, Gemma-2 9B, Phi-3-Mini, GPT-4o-mini, GPT-4o и R2D2.
Они использовали несколько LLM, чтобы оценить результаты и классифицировать их как неудачную или успешную попытку джейлбрейка.
Простое изменение времени подсказки оказало удивительно значительное влияние на процент успешных атак (ASR). Особенно восприимчивыми к этому приему оказались GPT-4o и GPT-4o mini.
ASR этой "простой атаки на GPT-4o увеличивается с 1% при использовании прямых запросов до 88% при использовании 20 попыток переформулирования вредных запросов в прошедшем времени".
Вот пример того, насколько совместимым становится GPT-4o, если просто переписать запрос в прошедшем времени. Для этого я использовал ChatGPT, и уязвимость еще не была исправлена.

Обучение отказу с помощью RLHF и SFT тренирует модель успешно обобщать отказ от вредных подсказок, даже если она не видела конкретную подсказку раньше.
Когда задание написано в прошедшем времени, LLM, похоже, теряют способность к обобщению. Остальные LLM оказались не намного лучше, чем GPT-4o, хотя Llama-3 8B показалась наиболее устойчивой.
Переписывание подсказки в будущем времени привело к увеличению ASR, но было менее эффективным, чем переписывание подсказки в прошедшем времени.
Исследователи пришли к выводу, что это может быть связано с тем, что "наборы данных с тонкой настройкой могут содержать большую долю вредных запросов, выраженных в будущем времени или в виде гипотетических событий".
Они также предположили, что "внутренние рассуждения модели могут интерпретировать запросы, ориентированные на будущее, как потенциально более вредные, в то время как заявления в прошедшем времени, например, об исторических событиях, могут восприниматься как более благотворные".
Можно ли это исправить?
Дальнейшие эксперименты показали, что добавление подсказок о прошедшем времени в наборы данных для тонкой настройки эффективно снижает восприимчивость к этому методу побега из тюрьмы.
Несмотря на свою эффективность, этот подход требует упреждения опасных подсказок, которые может ввести пользователь.
Исследователи считают, что более простым решением является оценка результатов работы модели до того, как она будет представлена пользователю.
Как бы ни был прост этот джейлбрейк, похоже, что ведущие компании, занимающиеся разработкой искусственного интеллекта, пока не нашли способа его исправить.



