

Компания Google выпустила две модели из семейства легких, открытых моделей под названием Gemma.
В то время как модели Gemini от Google являются проприетарными, или закрытыми, модели Gemma были выпущены как "открытые модели" и свободно доступны для разработчиков.
Google выпустила модели Gemma двух размеров, с параметрами 2B и 7B, с предварительно обученными и настроенными по инструкции вариантами для каждой из них. Google выпускает весовые коэффициенты моделей, а также набор инструментов для разработчиков, позволяющих адаптировать модели под свои нужды.
По словам Google, модели Gemma были созданы с использованием той же технологии, что и флагманская модель Gemini. Несколько компаний выпустили модели 7B в попытке создать LLM, сохраняющий полезную функциональность и работающий локально, а не в облаке.
Llama-2-7B и Мистраль-7B являются заметными соперниками в этой области, но Google утверждает, что "Gemma превосходит значительно более крупные модели по ключевым показателям", и предлагает это сравнение в качестве доказательства.
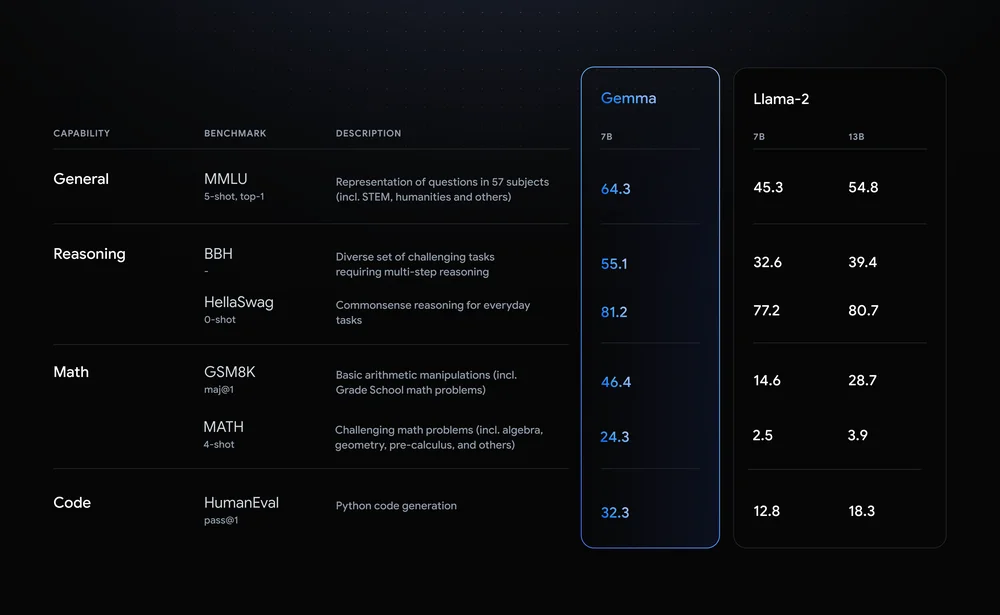
Результаты бенчмарков показывают, что Gemma превосходит даже более крупную 12B-версию Llama 2 по всем четырем параметрам.
По-настоящему интересным в Gemma является перспектива ее локального запуска. Google сотрудничает с NVIDIA, чтобы оптимизировать Gemma для графических процессоров NVIDIA. Если у вас есть ПК с одним из графических процессоров NVIDIA RTX, вы можете запустить Gemma на своем устройстве.
NVIDIA утверждает, что ее установленная база насчитывает более 100 миллионов графических процессоров NVIDIA RTX. Это делает Gemma привлекательным вариантом для разработчиков, которые пытаются решить, какую облегченную модель использовать в качестве основы для своих продуктов.
NVIDIA также добавит поддержку Gemma в свои Чат с RTX платформа, позволяющая легко запускать LLM на RTX-компьютерах.
Хотя технически это не открытый исходный код, только ограничения на использование в лицензионном соглашении не позволяют моделям Gemma получить этот ярлык. Критики открытых моделей Google утверждает, что для обеспечения безопасности Джеммы была проведена обширная ретроспективная работа.
Google утверждает, что использовала "обширную тонкую настройку и обучение с подкреплением на основе человеческих отзывов (RLHF), чтобы согласовать наши модели, настроенные на инструкции, с ответственным поведением". Компания также выпустила набор инструментов ответственного генеративного ИИ, чтобы помочь разработчикам поддерживать Gemma в соответствии с требованиями после тонкой настройки.
Настраиваемые легкие модели, такие как Gemma, могут предложить разработчикам больше пользы, чем более крупные модели, такие как GPT-4 или Gemini Pro. Возможность запускать LLM локально без затрат на облачные вычисления или вызовы API становится все более доступной с каждым днем.
После того как Gemma будет открыта для разработчиков, будет интересно посмотреть на спектр приложений, основанных на искусственном интеллекте, которые вскоре могут появиться на наших компьютерах.



