

Люк Фарритор, 21-летний студент факультета информатики Университета Небраски-Линкольна, раскрыл текст, содержащийся в карбонизированном свитке из древнего Геркуланума.
Этот свиток был нечитаем со времен извержения вулкана в 79 году нашей эры, которое также поглотило Помпеи. Алгоритм машинного обучения Фарритора успешно определил греческие буквы на свернутом папирусе, включая слово πορϕυρας (porphyras), что означает "пурпурный".
Его техника основана на выявлении мелких, нюансных различий в текстуре поверхности, чтобы обучить нейронную сеть распознавать чернила и, в свою очередь, летеринг.
"Когда я увидел первое изображение, я был потрясен". сказал Федерика Николарди, папиролог из Неаполитанского университета. "Это была такая мечта, - продолжает она, - я действительно могу увидеть что-то изнутри свитка".
Свитки, погребенные извержением Везувия в 79 году нашей эры, до сих пор остаются практически недоступными из-за их хрупкого состояния.
При ручном разворачивании обугленных свитков они расслаиваются, и ученые опасаются, что их содержимое навсегда останется тайной.

Как объяснил Николарди, "это такие сумасшедшие предметы. Они все смяты и раздавлены".
Осознавая сложность расшифровки свитков, они Вызов Везувию Был учрежден приз, предлагающий различные награды, в том числе главный приз в размере US$700 000 за расшифровку нескольких отрывков из свитка.
12 октября было объявлено, что Фарритор получил приз в размере $40 000 за идентификацию более 10 символов на небольшом участке папируса.
Другой участник, Юссеф Надер из Свободного университета Берлина, получил $10 000 за второе место.
Историк Древней Греции и Рима Теа Соммершильд назвала возможность наконец-то разглядеть буквы и слова внутри свитков "чрезвычайно захватывающей".
Соммершильд отметил, что их интерпретация может "революционизировать наши знания о древней истории и литературе" этого региона.
Исследователи уже не в первый раз пытаются прочитать эти древние карбонизированные свитки. В 2019 году Брент Силс, профессор компьютерных наук, специализирующийся на виртуальном чтении и сохранении древних свитков, попытался "виртуально развернуть" свитки с помощью рентгеновской компьютерной томографии (КТ).
В 2016 году Силсу удалось найти древнееврейский пергамент, найденный в 1970 году в Эйн-Геди (Израиль), и раскрыть часть Книги Левит.
Однако свитки из Геркуланума представляли собой другую проблему: чернила, сделанные из древесного угля и воды, не выделялись на сканах.
Именно здесь Фарритор преуспел, сосредоточившись на особой тонкой текстуре, названной "кракелюр", для следов чернил.
По словам Фарритора, "я прыгал вверх и вниз" после того, как его алгоритм выявил пять букв из недавно опубликованного сегмента. "О боже, это действительно сработает", - понял он.
Вскоре после этого он усовершенствовал свою модель и определил необходимые десять букв для приза, причем слово "пурпур" ранее не встречалось в свитках Геркуланума.
Главный приз "Везувийского вызова" еще не объявлен, а крайний срок - 31 декабря.
ИИ для расшифровки древних языков
Шесть тысячелетий назад шумеры поселились в Месопотамии, на землях, раскинувшихся вдоль рек Тигр и Евфрат.
Этот регион, охватывающий современные Ирак, Кувейт, Турцию и Сирию, стал свидетелем эволюции от небольших аграрных общин до грандиозных городских цивилизаций. Города, подобные Уруку, расцвели, объединив в себе сложные каналы, ирригационные системы и центры управления. Это была критическая эпоха для прогресса и эволюции человечества.
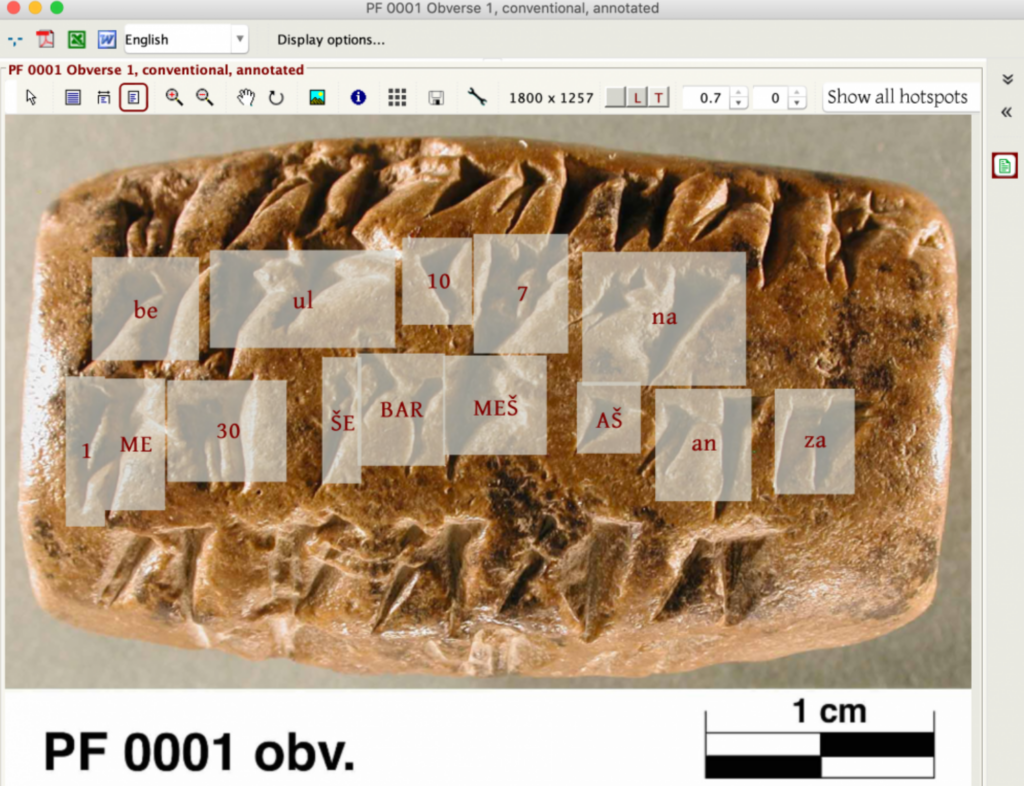
Шумеры писали письмом, известным как клинопись. Эта система письма требовала вдавливания тростника в глину, в результате чего получались сложные лого-слоговые надписи. Клинопись - это не язык, а письменность, охватывающая около 15 языков на протяжении трех тысячелетий.

Хотя клинопись использовалась в основном как административный инструмент для учета скота или сделок, к 2700 году до н. э. появился широкий спектр более философских и творческих работ.
Одним из самых заметных таких трудов является Эпос о Гильгамеше, которая распространяется на двенадцать планшетов.
Энрике Хименес из Университета Людвига Максимилиана в Мюнхене утверждает: "Половина истории человечества заключена в этих клинописных табличках".
Однако всего 75 человек, по данным New Scientist, могут расшифровать клинопись, несмотря на десятки тысяч непереведенных табличек по всему миру.
Машинное обучение помогает исследователям разгадывать истории, записанные на каменных табличках, заполнять пробелы и упорядочивать тексты в хронологическом порядке, чтобы узнать больше о том, как жили древние шумеры.
Роль машинного обучения в расшифровке древних текстов
Энрике Хименес и его команда основали Электронная вавилонская литература, сотрудничество археологов, ученых, изучающих данные, и историков.
Для анализа клинописных табличек команда использовала метод машинного обучения, изначально разработанный для сравнения генных последовательностей. Этот искусственный интеллект предсказывает содержание недостающих фрагментов и границы, на которых фрагменты выравниваются.
Эта техника привела к таким открытиям, как недостающие части "Эпоса о Гильгамеше" и новый месопотамский жанр, описывающий образовательные пародии и шутки для детей.
В 2020 году - отдельная модель, DeepScribeбыл обучен на 6 000 аннотированных изображений из Архив укреплений Персеполисав котором указано около 100 000 символов из эламитского языка (современный Иран), датируемого примерно 500 годом до нашей эры.
Используя ресурсы Исследовательского вычислительного центра Университета Чикаго, Кришнан и Эдди Уильямс обучили модель, способную декодировать эти знаки с впечатляющей точностью 80%.
Команда намерена превратить DeepScribe в универсальный инструмент дешифровки, который можно будет переучивать на другие языки, кроме эламитского.
DeepMind также исследовала расшифровку древних языков с помощью машинного обучения - в данном случае на поврежденных древнегреческих табличках.
Названный ИтакаЭта модель восстановила тексты с точностью 72%, определила их возраст в пределах трех десятилетий и даже предположила их происхождение с точностью 71%.

В процессе обучения в Итаке было изучено 60 000 текстов с 700 г. до н. э. по 500 г. н. э., снабженных данными о времени и месте их написания на 84 древних территориях.
Пересечение древних текстов и передового искусственного интеллекта показывает, что даже тысячелетние тайны не застрахованы от достижений современных технологий.
Смешивая старое с новым, исследователи одновременно сохраняют историю и открывают ранее неизвестные археологические знания.
Эти открытия подчеркивают безграничные возможности, открывающиеся при слиянии человеческого любопытства с технологическим мастерством, и доказывают, что существует новая линза, через которую можно взглянуть на чудеса нашего общего прошлого.




{kind=link}