

Компания Nvidia анонсировала новое программное обеспечение с открытым исходным кодом, которое, по ее словам, позволит увеличить производительность вычислений на ее графических процессорах H100.
В настоящее время графические процессоры Nvidia востребованы в основном для создания вычислительных мощностей для обучения новых моделей. Но после обучения эти модели нужно использовать. Под умозаключением в ИИ понимается способность LLM, например ChatGPT, делать выводы или прогнозы на основе данных, на которых она была обучена, и генерировать результаты.
Когда вы пытаетесь использовать ChatGPT и появляется сообщение о том, что серверы испытывают нагрузку, это потому, что вычислительное оборудование не справляется со спросом на умозаключения.
Nvidia утверждает, что ее новое программное обеспечение, TensorRT-LLM, может заставить существующее оборудование работать намного быстрее, а также повысить энергоэффективность.
Программное обеспечение включает оптимизированные версии самых популярных моделей, включая Meta Llama 2, OpenAI GPT-2 и GPT-3, Falcon, Mosaic MPT и BLOOM.
Для повышения производительности в нем используются такие умные приемы, как более эффективное пакетирование задач вывода и методы квантования.
LLM обычно используют 16-битные значения с плавающей точкой для представления весов и активаций. При квантовании эти значения уменьшаются до 8-битных значений с плавающей точкой. Большинство моделей сохраняют свою точность при таком снижении точности.
Компании, имеющие вычислительную инфраструктуру на базе графических процессоров Nvidia H100, могут рассчитывать на значительное повышение производительности вычислений, не потратив при этом ни цента, благодаря использованию TensorRT-LLM.
Nvidia использовала пример запуска небольшой модели с открытым исходным кодом GPT-J 6 для обобщения статей в наборе данных CNN/Daily Mail. В качестве базовой скорости используется более старый чип A100, который затем сравнивается с H100 без TensorRT-LLM, а затем с TensorRT-LLM.
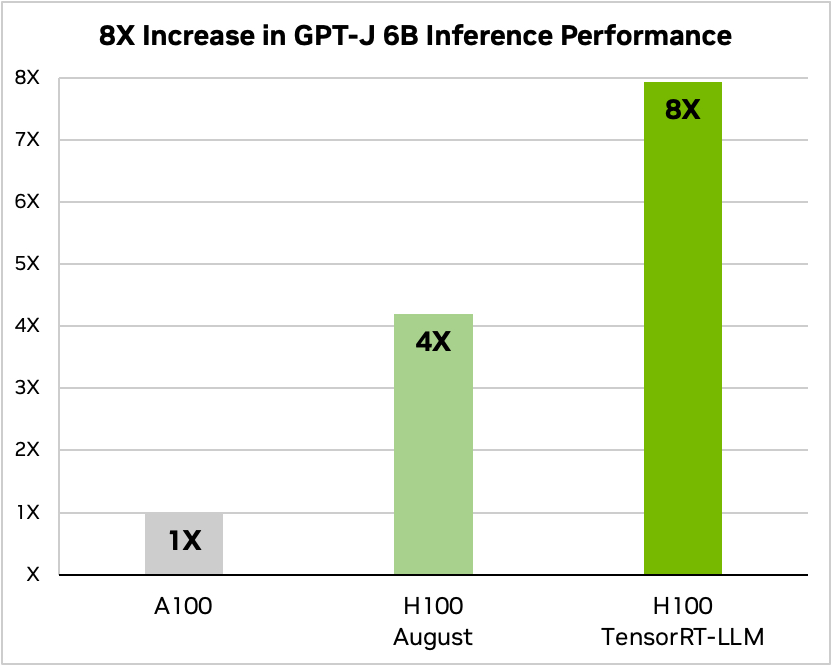
Источник: Nvidia
А вот сравнение при работе с Meta's Llama 2
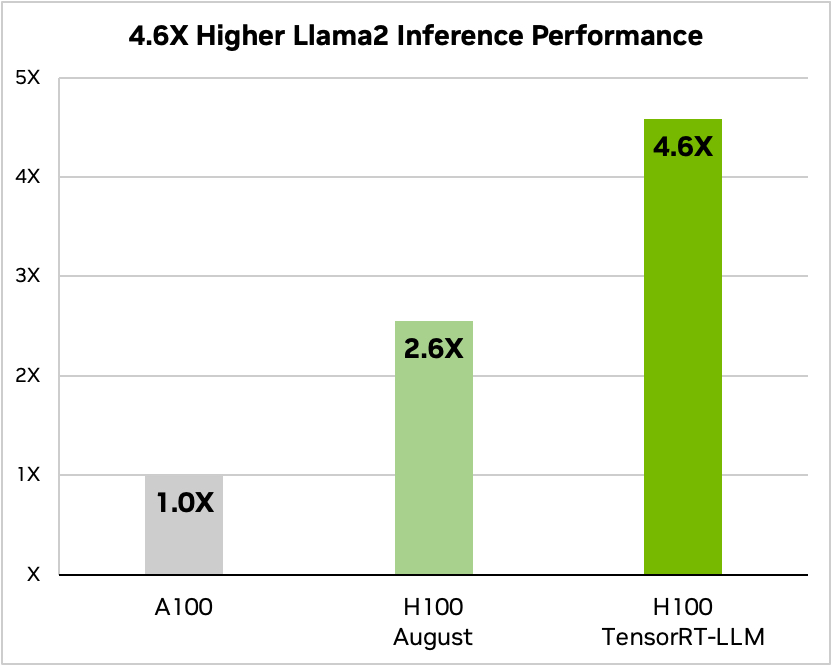
Источник: Nvidia
По словам Nvidia, тестирование показало, что в зависимости от модели, H100, работающий с TensorRT-LLM, потребляет от 3,2 до 5,6 раз меньше энергии, чем A100 во время вычислений.
Если вы используете модели ИИ на оборудовании H100, это означает, что производительность ваших выводов не только увеличится почти вдвое, но и ваши счета за электроэнергию станут намного меньше после установки этого программного обеспечения.
TensorRT-LLM также будет доступен для Nvidia's Суперчипы Грейс Хоппер но компания не опубликовала данные о производительности GH200 с новым программным обеспечением.
Новое программное обеспечение еще не было готово, когда Nvidia подвергла свой суперчип GH200 стандартным для отрасли тестам производительности MLPerf AI. Результаты показали, что GH200 работает на 17% лучше, чем однокристальная система H100 SXM.
Если Nvidia добьется хотя бы скромного прироста производительности вычислений с помощью TensorRT-LLM в GH200, это выведет компанию далеко вперед по сравнению с ближайшими конкурентами. Быть торговым представителем Nvidia сейчас, должно быть, самая легкая работа в мире.



