

Художники и авторы ставят разработчиков ИИ на кон из-за возможного нарушения авторских прав.
Введите запрос в генератор изображений ИИ, например DALL-E, MidJourney или Stable Diffusion, и он в считанные секунды создаст уникальное на первый взгляд изображение.
Несмотря на кажущуюся уникальность, tЭти изображения создаются из миллиардов других изображений с помощью сложной техники цифрового коллажа.
Исходные изображения взяты из "публичных" или "открытых" источников.
Если вы спросите ChatGPT, как работает генератор изображений вроде DALL-E, он ответит что-то вроде: "Думайте о DALL-E как о суперпродвинутом цифровом художнике, который видел миллионы изображений и может нарисовать новое на основе вашего описания, стараясь сделать его как можно более точным. Он делает это, смешивая и сопоставляя элементы, которые он узнал из своих предыдущих "наблюдений"".
Это похоже на блуждание по художественным галереям мира и фотографирование каждого произведения - только вас не выгонят.
В Интернете нет охранников и камер, следящих за людьми, чтобы предотвратить пиратство или воровство, а практика data scraping - сбора данных из Интернета с помощью ботов - всегда занимала туманную правовую территорию.
Художники утверждают, что обучение искусственного интеллекта преобразованию текста в изображение на основе публичных наборов данных равносильно величайшей в мире краже произведений искусства.
Что чувствуют художники от детекторов ИИ?
Для некоторых успешных художников, чьи работы были скопированы тысячи и даже миллионы раз, влияние искусства, созданного искусственным интеллектом, стало причиной того, что им стало трудно отличить свои работы от копий, созданных искусственным интеллектом.
Эстетические различия просто слишком малы, возможно, потому, что популярные изображения часто появляются в наборах данных.
Среди них Грег Рутовски, который сказал: "Мои работы использовались в искусственном интеллекте чаще, чем работы Пикассо".

Фэнтезийные иллюстрации Рутовки используются в таких франшизах, как Dungeons and Dragons и Magic: The Gathering, и могут быть воспроизведены с помощью генераторов "текст-изображение", если просто добавить имя художника в запрос, например, "Создайте дракона, сражающегося с людоедом, в стиле Грега Рутовски".
Он рассказал Би-би-си"В первый же месяц, когда я обнаружил это, я понял, что это явно повлияет на мою карьеру, и я не смогу узнавать и находить свои работы в Интернете", - добавил он, - "Результаты будут связаны с моим именем, но это будет не мой образ. Оно не будет создано мной. Так что это внесет путаницу для людей, которые открывают для себя мои работы".
Он продолжил: "Все, над чем мы работали столько лет, так легко отнять у нас с помощью искусственного интеллекта".
Последнее утверждение действительно попадает в цель, поскольку ИИ воспроизводит сложные, талантливые работы за считанные секунды, а это значит, что не только работы художников становятся ненужными, но и навыки, использованные для их создания, теряются.
ЧеловечествоОтсутствие подлинных навыков и знаний - один из самых серьезных рисков ИИ, получивший название "ослабление,", проиллюстрированный диснеевским фильмом WALL-E, где люди теряют способность двигаться из-за технологий.
Еще один художник, высказавшийся о том, что ИИ воспроизводит их работы, - Келли МакКернан, иллюстратор из Теннесси, которая обнаружила, что более 50 ее работ были включены в список обучающих данных в крупномасштабной открытой сети искусственного интеллекта (LAION).
Вы можете найти около 5,8 миллиарда изображений в обучающих наборах ИИ с помощью инструмента "Прошел ли я обучение?"Именно так МакКернан наткнулся на ее работу.
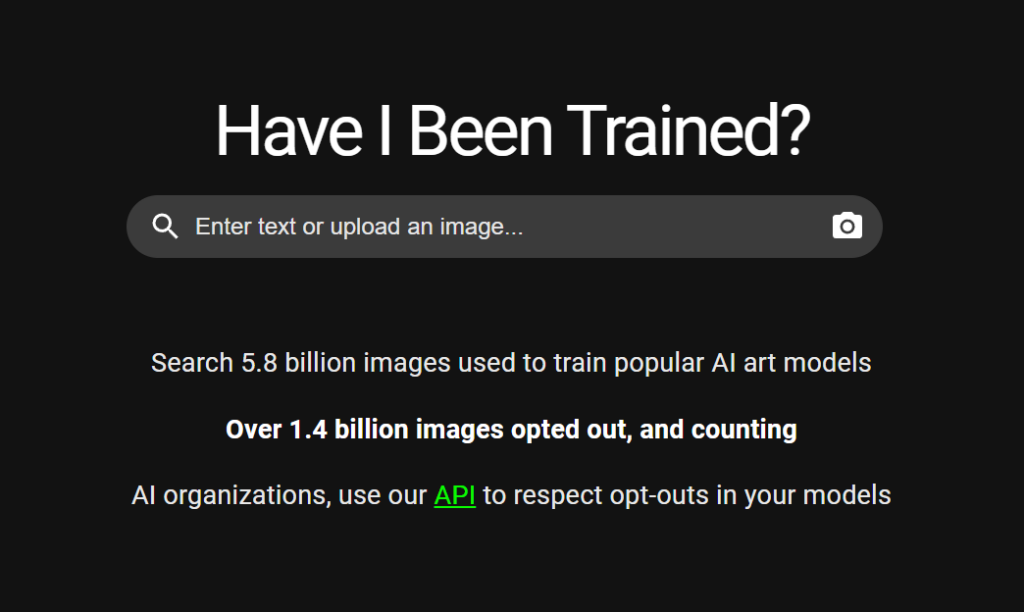
LAION - некоммерческая организация, создающая модели и наборы данных с открытым исходным кодом, многие из которых были использованы для обучения известных моделей преобразования текста в изображения, включая Stable Diffusion и Imagen.
"Внезапно все эти картины, с которыми у меня были личные отношения и путешествия, обрели новый смысл, это изменило мое отношение к этим произведениям искусства", - говорит МакКернан.
Юридические баталии продолжаются
МакКернан, к которой присоединились художницы Сара Андерсон и Карла Ортиз, подала в суд на Stability AI, DeviantArt и Midjourney.
Их иск присоединяется к потоку судебных исков против компаний, занимающихся разработкой искусственного интеллекта, как со стороны писателей, так и со стороны визуальных художников.
Крупные компании также подают или планируют подать в суд на разработчиков ИИ, в том числе Getty Images, которая заявила, что Stability AI незаконно скопировала и обработала 12 миллионов ее изображений без разрешения.
МакКернан сказал: "В нынешнем виде авторские права могут быть применены только к моему полному изображению. Я надеюсь, что это [судебный иск] будет способствовать защите артистов, чтобы искусственный интеллект не мог быть использован для замены нас. Если мы выиграем, я надеюсь, что многим художникам заплатят. Это бесплатный труд, а некоторые люди наживаются на его эксплуатации".
Стиль МакКернана, показанный ниже, был использован в 12 000 подсказок MidJourney.
Посмотреть это сообщение на Instagram
Фундаментальная проблема заключается в том, что закон об авторском праве просто не был создан для эпохи искусственного интеллекта.
Лиам Бадд из профсоюза исполнительских искусств и развлечений Equity выступил за обновление законов, отражающих потенциальные возможности для бизнеса, которые открывает генеративный ИИ.
Он заявилНам нужна большая ясность в законодательстве, и мы ведем кампанию за обновление Закона об авторском праве".
В ответ на растущую волну нарушений авторских прав с помощью ИИ различные юрисдикции, такие как ЕС, предложили разработчикам ИИ раскрывать все материалы, защищенные авторским правом, которые используются для обучения.
Будет ли этого достаточно? Разработчики ИИ уже показали, что им, скорее всего, все сойдет с рук?
В конце концов, большинство из этих наборов данных уже собраны, и компании, занимающиеся разработкой искусственного интеллекта, могут утверждать, что они просто обновляют модели, чтобы обойти необходимость декларировать авторские права на материалы.
Имеют ли иски прочную юридическую основу?
Нынешний раунд коллективных исков в основном вращается вокруг двух аргументов.
- Во-первых, утверждение, что компании нарушают авторские права художников, используя их работы без разрешения.
- Во-вторых, утверждение о том, что результаты работы ИИ являются по сути производным контентом из-за их включения в обучающие данные.
Применение этих аргументов различается по всему миру, например, в США, где законы о "добросовестном использовании" в целом более либеральны, чем в ЕС. Это еще больше усложняет ситуацию с авторским правом на ИИ. Если компании работают, например, в Великобритании, им может быть сложнее аргументировать "добросовестное использование".
Кроме того, в суд подают компании, занимающиеся разработкой генеративного ИИ, а не организации, составляющие наборы данных, как, например, LAION в случае с MidJourney. Элиана Торрес, юрист по вопросам интеллектуальной собственности из юридической фирмы Nixon Peabody, отмечает, что если LAION создала набор данных, то предполагаемое нарушение произошло в этот момент, а не тогда, когда этот набор данных был использован для обучения моделей.
Доказать, что работы, созданные ИИ, являются репродукциями оригинальных произведений, довольно сложно из-за сложной природы ИИ, использующего алгоритмическую обработку для разбивки и повторной сборки изображений.
Регулирующие органы были застигнуты врасплох правовыми последствиями генеративного ИИ, и хотя сейчас разрабатываются временные решения, такие как автоматические фильтры и положения об отказе от участия для художников, их может оказаться недостаточно.
Пока судьи не вынесут вердикт по отдельным делам, что может занять несколько месяцев, компании, занимающиеся разработкой генеративного ИИ, подвергают себя значительным юридическим рискам во многих юрисдикциях.
История показывает, что закон об авторском праве может адаптироваться к новым технологиям, но пока не выработан консенсус, и художники, и разработчики ИИ находятся в полном неведении.
Судьи не дают хода искам
Пока что судьи не дали артистам повода для оптимизма.
Например, окружной судья США Уильям Оррик поставил под сомнение иск Келли МакКернан.
По словам судьи ОррикаМакКернан и другие истцы должны были "предоставить больше фактов" о предполагаемом нарушении авторских прав и четко разграничить свои претензии к каждой компании (Stability AI, DeviantArt и Midjourney).
Оррик отметил, что системы были обучены на "пяти миллиардах сжатых изображений", поэтому художники должны предоставить более веские доказательства того, что именно их работы были задействованы в предполагаемом нарушении авторских прав. A сайт, отслеживающий этот судебный процесс недавно выложили техническую информацию о том, как работают эти модели, интерполируя содержимое изображений из обучающего набора.
Дело представляет Юридическая фирма Джозефа Саверикоторая также представляет по меньшей мере 5 других подобных дел против компаний, занимающихся искусственным интеллектом.
И опять же, авторские права потенциально нарушаются при сборе данных, а не при их создании.
Раздел 1202(b) американского Закона об авторском праве в цифровую эпоху "касается идентичных "копий... произведения", а не случайных фрагментов и адаптаций", - утверждение о том, что произведения "копируются" в процессе работы модели искусственного интеллекта, является потенциально неубедительным.
Мнение Оррика также поднимает вопрос об ответственности таких компаний, как MidJourney и DeviantArt, которые используют технологию Stable Diffusion от Stability AI в своих собственных генеративных системах искусственного интеллекта.
IЕсли на разработчиков ИИ, таких как OpenAI, Meta и т. д., будет возложена ответственность за нарушение авторских прав художников, они станут уязвимы для дальнейших судебных разбирательств.
Авторы и писатели также начинают судебные процессы
В другом недавний судебный процессАмериканская комедиантка и писательница Сара Сильверман, а также авторы Кристофер Голден и Ричард Кадри утверждают, что их слова были незаконно использованы для обучения таких моделей искусственного интеллекта, как ChatGPT и LLaMA.
В иске содержатся претензии, аналогичные тем, что подают художники, но на этот раз искусственный интеллект обучается на открытых текстовых данных.
В иске утверждается, что ChatGPT смог точно составить краткое содержание таких книг, как "Постельничий" Сильвермана, "Арарат" Голдена и "Сэндмен Слим" Кэдри. Важно отметить, что уровень детализации резюме не может быть объяснен выдержками из книг, выложенными в Википедии или на сайтах книжных магазинов.
Истцы обвиняют OpenAI и Meta в использовании защищенных авторским правом книг из "теневых библиотек" без согласия.
В теневых библиотеках, таких как Bibliotik, Library Genesis и Z-Library, хранятся большие объемы нелегально скопированной информации.
Хотя очевидно, что ИИ-компании монетизируют продукты с помощью работ, защищенных авторским правом, они имеют несколько уровней защиты, включая сложную природу их моделей и идиосинкразическое пространство, которое они занимают в моральном, этическом и правовом ландшафте.
Что должны решать суды?
В то время как регулирующие органы все еще обсуждают правила, касающиеся искусственного интеллекта, судьи могут первыми приступить к формированию будущего ландшафта авторского права.
Это может Это приведет к тому, что законодательство будет ограничено спецификой каждого дела и юрисдикцией, в которой оно было рассмотрено.
В настоящее время необходимо ответить на многие вопросы, в том числе:
Вопрос 1: Требуется ли лицензия для обучения модели на материалах, защищенных авторским правом?
- Добросовестное использование против лицензирования: Судам, возможно, придется решать, подпадает ли временное копирование данных во время обучения под "добросовестное использование", которое разрешает использование без лицензии. Это может зависеть от таких факторов, как цель копирования, характер работы, защищенной авторским правом, объем и существенность используемой части, а также влияние на рыночную стоимость работы, защищенной авторским правом.
- Международные перспективы: В разных юрисдикциях могут быть разные позиции по этому вопросу. Например, Директива ЕС по авторскому праву может быть истолкована иначе, чем Закон США об авторском праве.
Вопрос 2: Нарушает ли генеративный ИИ авторские права на материалы, на которых обучалась модель?
- Определение производного произведения: Является ли генеративный результат просто преобразованием, или он действительно создает производное произведение, нарушающее авторские права? Этот вопрос может потребовать комплексного анализа сходства и творчества.
- Вопросы ответственности: Если есть нарушение, кто несет ответственность? Создатель ИИ? Пользователь ИИ? Дистрибьютор?
Вопрос 3: Нарушает ли генеративный ИИ ограничения на удаление, изменение или фальсификацию информации об управлении авторскими правами?
- Конкретные случаи: Анализ конкретных алгоритмов, таких как Stable Diffusion, может потребоваться для определения того, могут ли созданные работы случайно воспроизводить или манипулировать водяными знаками или другой информацией об авторских правах.
- Намеренное и случайное нарушение: Судам может потребоваться определить, было ли намерение удалить или изменить информацию об авторских правах или это было непреднамеренным следствием работы ИИ.
Вопрос 4: Нарушает ли создание работ в стиле кого-то права этого человека?
- Определение права на публичность: Право на публичность варьируется от юрисдикции к юрисдикции. Судам, возможно, придется решать, является ли создание произведений в чьем-либо стиле равносильным использованию его образа или личности.
- Коммерческое и некоммерческое использование: Применение может отличаться в зависимости от того, используются ли результаты работы ИИ для получения коммерческой выгоды.
Вопрос 5: Как лицензии с открытым исходным кодом применяются к обучению моделей ИИ и распространению полученных результатов?
- Понимание лицензирования открытых источников: Судам может потребоваться определить, как лицензии на открытые источники применяются к обучающим данным ИИ и полученным результатам.
Сейчас нам не хватает одного: решения. Сейчас было бы глупо предсказывать, останется ли беспричинное соскабливание данных приемлемым. Если создатели найдут брешь в юридической броне индустрии ИИ, ущерб может быть значительным. Но пока это выглядит как большое "если".
Как только начнут поступать судебные решения и мы приблизимся к вступлению в силу нормативных актов, будущее направление развития ИИ станет более понятным. - До следующих испытаний.



