

Руководитель OpenAI Сэм Альтман обрушился на ЕС, заявив, что проект закона ЕС об искусственном интеллекте чрезмерно зарегулирован и не может быть удовлетворен. Несколько дней спустя он написал в твиттере, что OpenAI с радостью продолжит работу в ЕС.
Альтман путешествует по Европе, встречаясь с политиками из Германии, Франции, Испании, Польши и Великобритании. Однако, как сообщается, он отменил встречу в Брюсселе, где законодатели разрабатывают закон ЕС об искусственном интеллекте.
Ранее он заявлял, что OpenAI будет бороться за соблюдение закона: "Если мы сможем его соблюсти, мы это сделаем, а если не сможем, то прекратим работу. Мы будем пытаться. Но есть технические ограничения на то, что возможно".
После некоторой реакции в социальных сетях Альтман, похоже, отказался от своих комментариев: "Мы рады продолжать работать здесь и, конечно, не планируем уходить".
Очень продуктивная неделя переговоров в Европе о том, как лучше регулировать ИИ! Мы рады, что продолжаем работать здесь, и, конечно, не планируем уезжать.
- Сэм Альтман (@sama) 26 мая 2023 года
Альтман ранее сказал Рейтер"Текущий проект закона ЕС об искусственном интеллекте был бы чрезмерно регулирующим, но мы слышали, что его собираются отменить".
Евросоюз отреагировал: депутат Европарламента от Нидерландов Ким ван Спаррентак заявил, что законодатели, разрабатывающие закон об искусственном интеллекте, "не должны позволять американским компаниям шантажировать себя".
Она продолжила: "Если OpenAI не может соответствовать основным требованиям по управлению данными, прозрачности, безопасности и защите, то их системы не подходят для европейского рынка".
Закон об искусственном интеллекте может перевести большие языковые модели (LLM) в категорию "высокого риска"
Закон ЕС об ИИ определяет различные категории ИИ, в том числе категорию "высокого риска", на которую распространяются строгие правила, регулирующие прозрачность и мониторинг. Похоже, именно это и является центром опасений Альтмана.
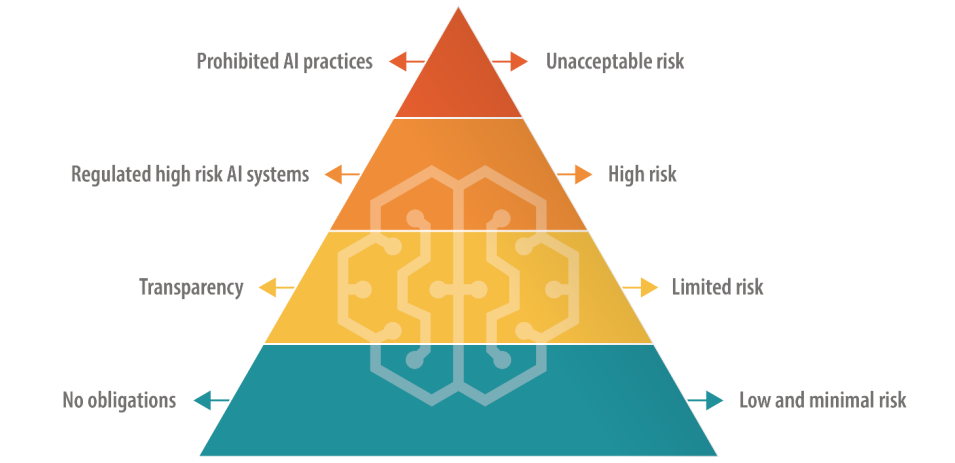
Согласно текущему проекту, компании, использующие ИИ с высоким уровнем риска, должны раскрывать любые материалы, защищенные авторским правом, включенные в обучающие данные и журнал событий, чтобы обеспечить воспроизводимость и отслеживаемость результатов. Это может оказаться дорогостоящим и обременительным для небольших компаний, занимающихся ИИ.
Материалы, защищенные авторским правом, остаются камнем преткновения
OpenAI далеко не всегда открыто заявляет о наличии в своих учебных данных материалов, защищенных авторским правом.
Было установлено, что искусственный интеллект повторять строки из несколько романов, в том числе "Гарри Поттер" и "Игра престолов". Исследователи предлагают Вероятно, это связано с тем, что отрывки из книг часто становятся общественным достоянием.
Существует множество судебные дела, связанные с авторским правом против OpenAI, Microsoft и создателей таких генераторов изображений, как Середина путешествия. Сейчас мы просто не знаем, в каких масштабах ИИ использует данные об авторских правах и каковы методы их получения.
ЕС хочет изменить эту ситуацию, введя правила прозрачности, которые могут изменить методы обучения ИИ, а значит, и его производительность.
Возможно, мы живем в нерегулируемом пузыре ИИ, который вот-вот лопнет.



