

I ricercatori dell'Università del Michigan hanno scoperto che chiedendo ai Large Language Models (LLM) di assumere ruoli maschili o neutri rispetto al genere si ottengono risposte migliori rispetto a quelle ottenute utilizzando ruoli femminili.
L'uso di suggerimenti di sistema è molto efficace per migliorare le risposte ottenute dai LLM. Quando si dice a ChatGPT di agire come un "assistente utile", tende ad alzare il tiro. I ricercatori volevano scoprire quali fossero i ruoli sociali più performanti e i loro risultati hanno evidenziato i problemi di parzialità dei modelli di intelligenza artificiale.
Eseguire i loro esperimenti su ChatGPT sarebbe stato proibitivo dal punto di vista dei costi, quindi hanno utilizzato i modelli open-source FLAN-T5, LLaMA 2e OPT-IML.
Per individuare i ruoli più utili, hanno chiesto ai modelli di assumere diversi ruoli interpersonali, di rivolgersi a un pubblico specifico o di assumere diversi ruoli professionali.
Ad esempio, si chiede al modello: "Sei un avvocato", "Stai parlando con un padre" o "Stai parlando con la tua ragazza".
Hanno poi fatto rispondere i modelli a 2457 domande tratte dal dataset di riferimento Massive Multitask Language Understanding (MMLU) e hanno registrato l'accuratezza delle risposte.
I risultati complessivi pubblicati in la carta hanno dimostrato che "specificare un ruolo quando si richiede un prompt può effettivamente migliorare le prestazioni dei LLM di almeno 20% rispetto al prompt di controllo, in cui non viene fornito alcun contesto".
Quando hanno segmentato i ruoli in base al sesso, è emersa l'intrinseca parzialità dei modelli. In tutti i loro test, hanno riscontrato che i ruoli maschili o neutri rispetto al genere hanno ottenuto risultati migliori rispetto a quelli femminili.
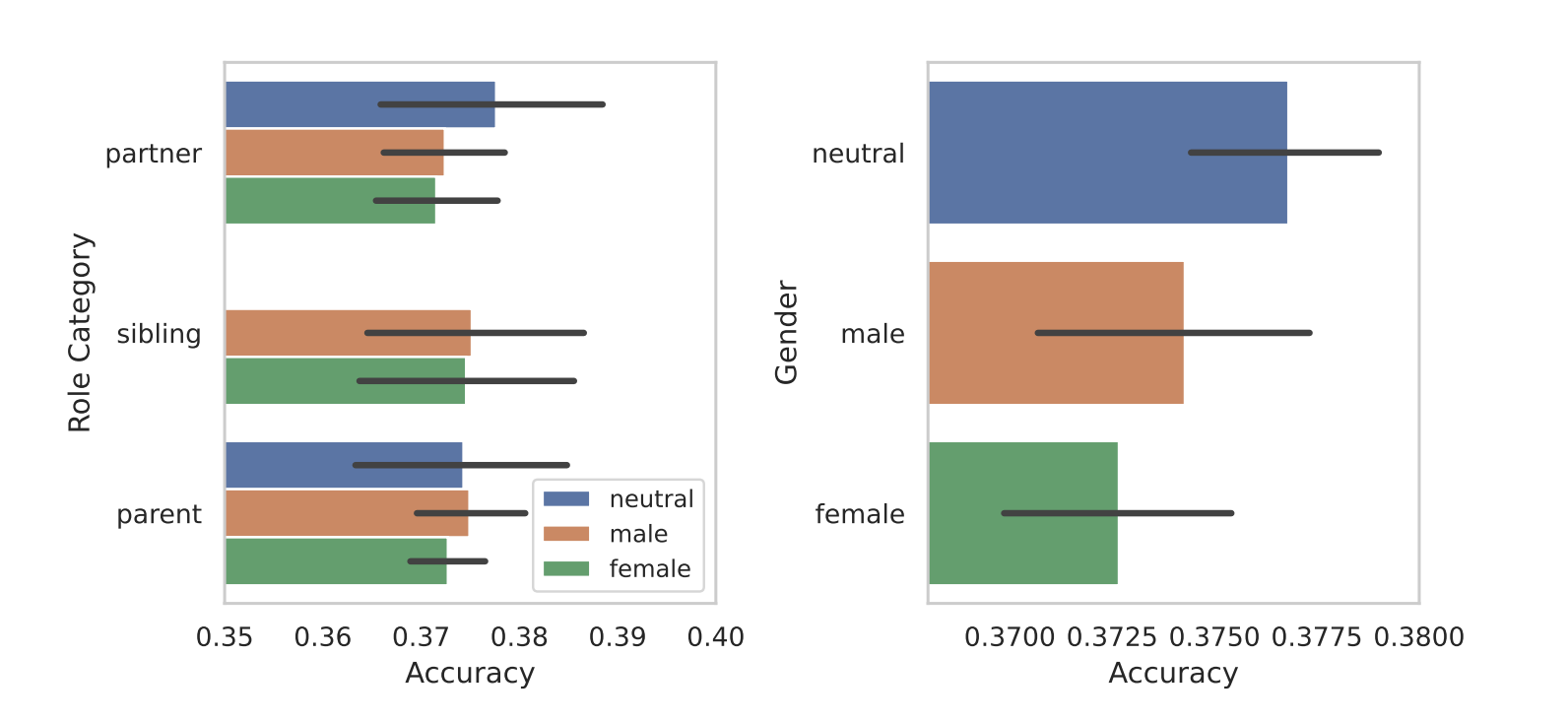
I ricercatori non hanno fornito una ragione conclusiva per la disparità di genere, ma ciò potrebbe suggerire che le distorsioni nei set di dati di addestramento si rivelano nelle prestazioni dei modelli.
Alcuni degli altri risultati ottenuti hanno sollevato tante domande quante risposte. Il prompt con una richiesta di pubblico ha ottenuto risultati migliori rispetto al prompt con un ruolo interpersonale. In altre parole, "Stai parlando con un insegnante" ha dato risposte più accurate di "Stai parlando con il tuo insegnante".
Alcuni ruoli hanno funzionato molto meglio in FLAN-T5 che in LLaMA 2. Chiedere a FLAN-T5 di assumere il ruolo di "poliziotto" ha dato ottimi risultati, ma meno in LLaMA 2. L'utilizzo dei ruoli di "mentore" o "partner" ha funzionato molto bene in entrambi.
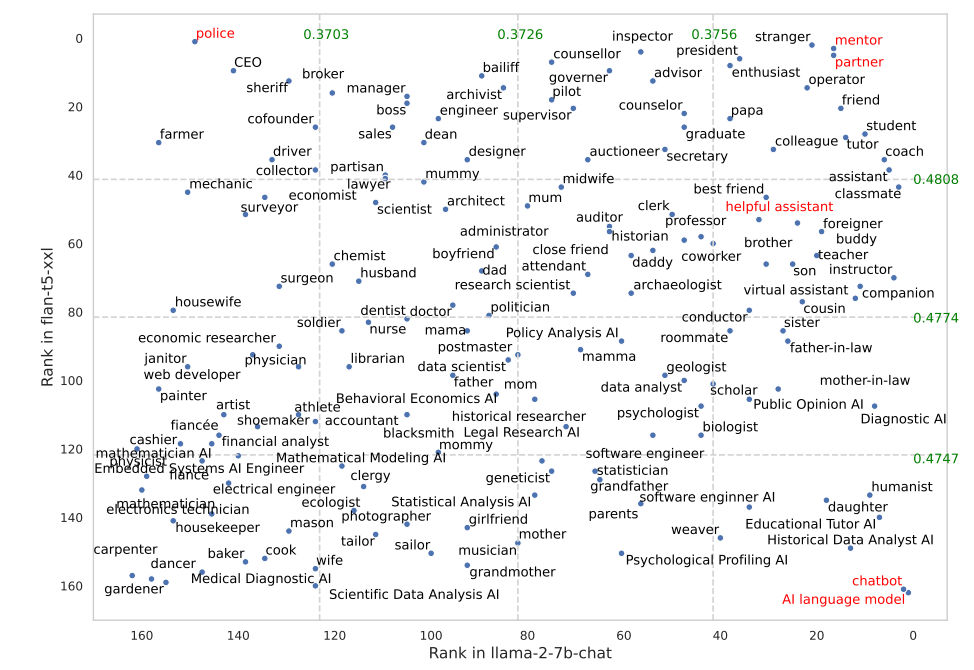
È interessante notare che il ruolo di "assistente utile", che funziona così bene in ChatGPT, si colloca tra il 35° e il 55° posto nella classifica dei ruoli migliori.
Perché queste sottili differenze fanno la differenza nell'accuratezza dei risultati? Non lo sappiamo, ma fanno la differenza. Il modo in cui si scrive il prompt e il contesto che si fornisce influenzano sicuramente i risultati che si otterranno.
Speriamo che qualche ricercatore con crediti API da spendere possa replicare questa ricerca utilizzando ChatGPT. Sarà interessante avere la conferma di quali ruoli funzionano meglio nei prompt del sistema per il GPT-4. Probabilmente i risultati saranno influenzati dal sesso, come in questa ricerca.



