

Genie di Google DeepMind è un modello generativo che traduce semplici immagini o richieste di testo in mondi dinamici e interattivi.
Genie è stato addestrato su un ampio set di dati di oltre 200.000 ore di filmati di gioco, tra cui gameplay di platform 2D e interazioni robotiche reali.
Questo vasto insieme di dati ha permesso a Genie di comprendere e generare la fisica, la dinamica e l'estetica di numerosi ambienti e oggetti.
Il modello definitivo, documentato in un carta di ricercacontiene 11 miliardi di parametri per generare mondi virtuali interattivi a partire da immagini in diversi formati o da richieste di testo.
Così, potete dare a Genie un'immagine del vostro salotto o del vostro giardino e trasformarla in un livello di piattaforma 2D giocabile.
Oppure scarabocchiare un ambiente 2D su un foglio di carta e convertirlo in un ambiente di gioco giocabile.
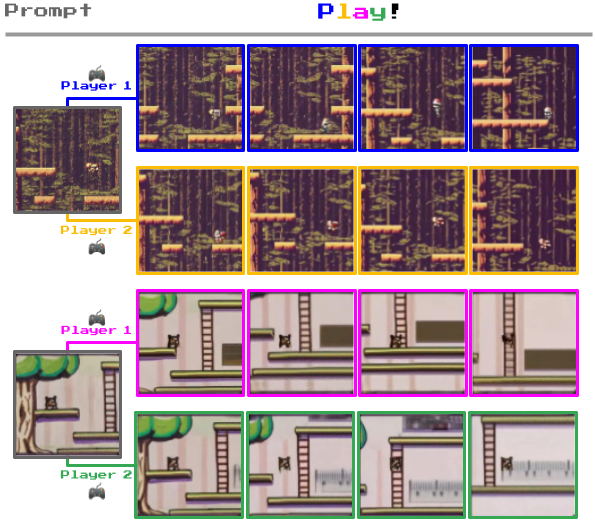
Ciò che distingue Genie da altri modelli di mondo è la sua capacità di consentire agli utenti di interagire con gli ambienti generati fotogramma per fotogramma.
Per esempio, qui sotto potete vedere come Genie prende fotografie di ambienti reali e le trasforma in livelli di gioco 2D.

Come funziona Genie
Genie è un "modello di fondazione del mondo" con tre componenti chiave: un tokenizer video spaziotemporale, un modello di dinamica autoregressiva e un modello di azione latente (LAM) semplice e scalabile.
Ecco come funziona:
- Trasformatori spaziotemporali: Il cuore di Genie è costituito dai trasformatori spaziotemporali (ST), che elaborano sequenze di fotogrammi video. A differenza dei trasformatori tradizionali che gestiscono testo o immagini statiche, i trasformatori ST sono progettati per comprendere la progressione dei dati visivi nel tempo, rendendoli ideali per la generazione di video e ambienti dinamici.
- Modello di azione latente (LAM): Genie comprende e predice le azioni all'interno dei suoi mondi generati attraverso il LAM. Questo infonde le azioni potenziali che potrebbero verificarsi tra i fotogrammi di un video, apprendendo un insieme di "azioni latenti" direttamente dai dati visivi. Ciò consente a Genie di controllare la progressione degli eventi negli ambienti interattivi, nonostante l'assenza di etichette di azione esplicite nei dati di addestramento.
- Modello di tokenizzazione e dinamica dei video: Per gestire i dati video, Genie impiega un tokenizer video che comprime i fotogrammi video grezzi in un formato più maneggevole di tokens discreti. Dopo la tokenizzazione, il modello dinamico predice la serie successiva di fotogrammi, generando i fotogrammi successivi nell'ambiente interattivo.
Il team di DeepMind ha spiegato che "Genie potrebbe consentire a un gran numero di persone di generare le proprie esperienze di gioco. Questo potrebbe essere positivo per coloro che desiderano esprimere la propria creatività in un modo nuovo, ad esempio i bambini che potrebbero progettare e calarsi nei loro mondi immaginari".
In un esperimento collaterale, quando sono stati presentati video di bracci robotici reali che si impegnavano con oggetti del mondo reale, Genie ha dimostrato una sorprendente capacità di decifrare le azioni che questi bracci potevano eseguire. Questo dimostra i potenziali impieghi nella ricerca robotica.
Tim Rocktäschel del team Genie ha descritto il potenziale aperto di Genie: "È difficile prevedere quali casi d'uso saranno abilitati. Speriamo che progetti come Genie finiscano per fornire alle persone nuovi strumenti per esprimere la propria creatività".
DeepMind era consapevole dei rischi che avrebbe comportato la pubblicazione di questo modello di base, tanto che nel documento si legge: "Abbiamo scelto di non rilasciare i checkpoint del modello addestrato, il dataset di addestramento del modello o gli esempi tratti da tali dati a corredo di questo documento o del sito web".
"Vorremmo avere l'opportunità di impegnarci ulteriormente con la comunità della ricerca (e dei videogiochi) e di garantire che ogni futura uscita di questo tipo sia rispettosa, sicura e responsabile".
Utilizzo di giochi per simulare applicazioni reali
DeepMind ha utilizzato i videogiochi per diversi progetti di apprendimento automatico.
Ad esempio, nel 2021, DeepMind ha costruito XLandUn parco giochi virtuale per testare approcci di apprendimento per rinforzo (RL) per agenti AI generalisti. Qui i modelli di IA hanno imparato a cooperare e a risolvere problemi eseguendo compiti come lo spostamento di ostacoli in ambienti di gioco aperti.
Poi, proprio il mese scorso, SIMA (Scalable, Instructable, Multiworld Agent) è stato progettato per comprendere ed eseguire istruzioni in linguaggio umano in diversi giochi e scenari.
SIMA è stato addestrato con nove videogiochi che richiedono diverse abilità, dalla navigazione di base al pilotaggio di veicoli.
Gli ambienti di gioco offrono una sandbox controllabile e scalabile per l'addestramento e il test dei modelli di intelligenza artificiale.
L'esperienza di DeepMind nel campo dei giochi risale al 2014-2015, quando ha sviluppato un algoritmo in grado di sconfiggere gli esseri umani in giochi come Pong e Space Invaders, per non parlare di AlphaGo, che ha sconfitto il giocatore professionista Fan Hui su un tabellone 19×19 di dimensioni reali.



