

OpenAI non ha rilasciato nuovi modelli durante l'evento Dev Day, ma le nuove funzionalità dell'API entusiasmeranno gli sviluppatori che desiderano utilizzare i loro modelli per creare applicazioni potenti.
OpenAI ha avuto settimane difficili: il suo CTO, Mira Murati, e altri ricercatori si sono aggiunti alla lista sempre più lunga degli ex dipendenti. L'azienda è sottoposta a una crescente pressione da parte di altri modelli di punta, compresi quelli open-source che offrono agli sviluppatori opzioni più economiche e altamente capaci.
Le novità presentate da OpenAI sono state l'API Realtime (in versione beta), la messa a punto della visione e strumenti per aumentare l'efficienza come il prompt caching e la distillazione dei modelli.
API in tempo reale
L'API Realtime è la novità più interessante, anche se in versione beta. Consente agli sviluppatori di creare esperienze speech-to-speech a bassa latenza nelle loro applicazioni senza utilizzare modelli separati per il riconoscimento vocale e la conversione text-to-speech.
Grazie a questa API, gli sviluppatori possono creare applicazioni che consentono conversazioni in tempo reale con l'intelligenza artificiale, come gli assistenti vocali o gli strumenti di apprendimento linguistico, il tutto attraverso un'unica chiamata API. Non si tratta di un'esperienza perfetta come quella offerta dalla modalità vocale avanzata di GPT-4o, ma ci si avvicina.
Tuttavia, non è economico: costa circa $0,06 al minuto di ingresso audio e $0,24 al minuto di uscita audio.
La nuova API in tempo reale di OpenAI è incredibile...
Guardate come ordina 400 fragole chiamando il negozio con twillio. Il tutto a voce. 🍓🎤 pic.twitter.com/J2BBoL9yFv
- Ty (@FieroTy) 1 ottobre 2024
Messa a punto della visione
La messa a punto della visione all'interno dell'API consente agli sviluppatori di migliorare la capacità dei loro modelli di comprendere e interagire con le immagini. Grazie alla messa a punto di GPT-4o utilizzando le immagini, gli sviluppatori possono creare applicazioni che eccellono in attività come la ricerca visiva o il rilevamento di oggetti.
Questa funzione è già stata sfruttata da aziende come Grab, che ha migliorato l'accuratezza del suo servizio di mappatura perfezionando il modello per riconoscere i segnali stradali dalle immagini a livello stradale.
OpenAI ha anche fornito un esempio di come GPT-4o possa generare contenuti aggiuntivi per un sito web dopo essere stato messo a punto per adattarsi stilisticamente ai contenuti esistenti del sito.
Caching del prompt
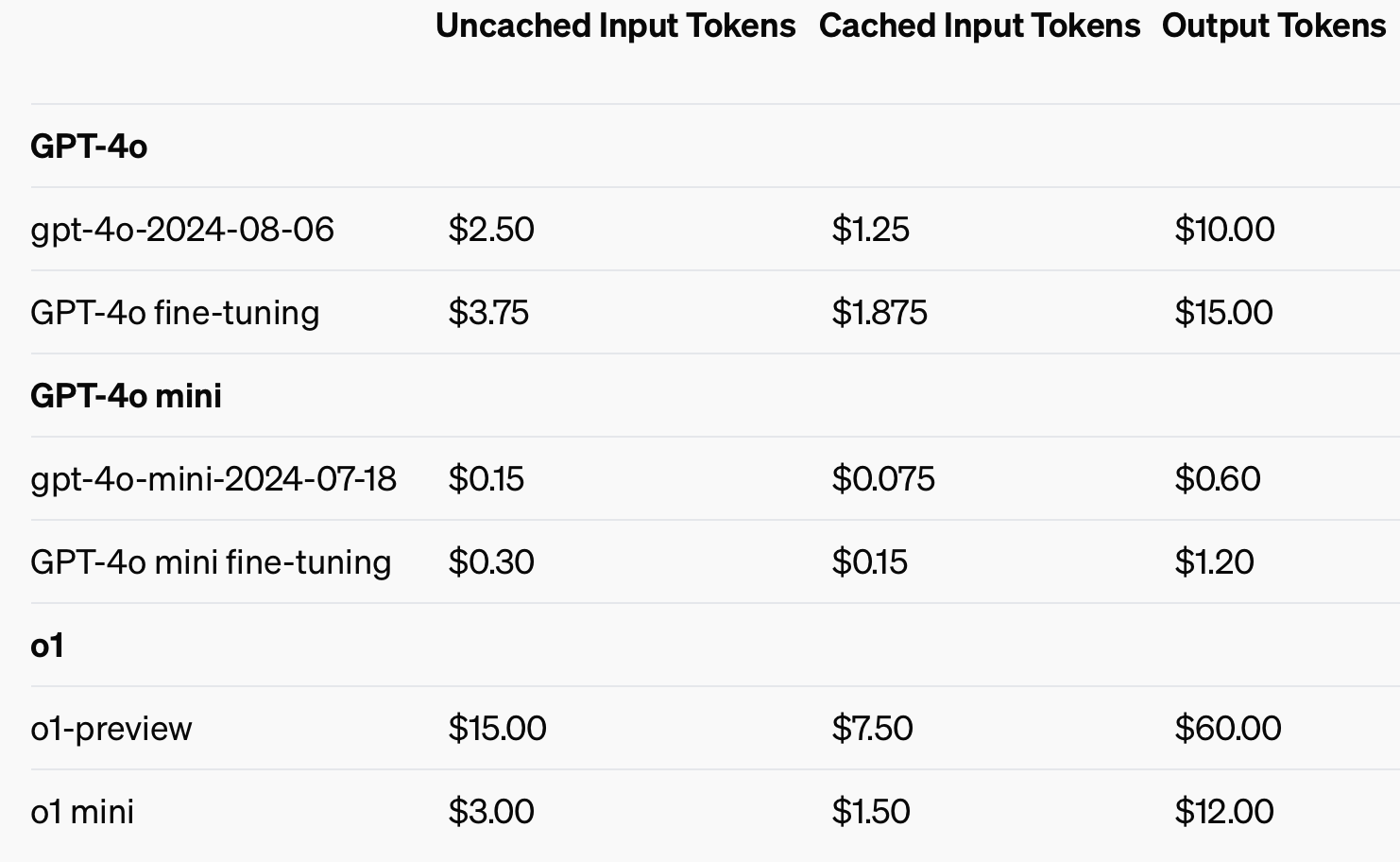
Per migliorare l'efficienza dei costi, OpenAI ha introdotto il prompt caching, uno strumento che riduce i costi e la latenza delle chiamate API utilizzate di frequente. Riutilizzando gli input elaborati di recente, gli sviluppatori possono tagliare i costi di 50% e ridurre i tempi di risposta. Questa funzione è particolarmente utile per le applicazioni che richiedono lunghe conversazioni o contesti ripetuti, come i chatbot e gli strumenti di assistenza clienti.
L'utilizzo di input memorizzati nella cache potrebbe far risparmiare fino a 50% sui costi dei token di input.
Modello di distillazione
La distillazione dei modelli consente agli sviluppatori di mettere a punto modelli più piccoli e più efficienti dal punto di vista dei costi, utilizzando i risultati di modelli più grandi e più capaci. Si tratta di una novità assoluta, perché in precedenza la distillazione richiedeva più fasi e strumenti scollegati, rendendo il processo lungo e soggetto a errori.
Prima della funzione integrata Model Distillation di OpenAI, gli sviluppatori dovevano orchestrare manualmente diverse parti del processo, come la generazione di dati da modelli più grandi, la preparazione di set di dati per la messa a punto e la misurazione delle prestazioni con vari strumenti.
Gli sviluppatori possono ora memorizzare automaticamente le coppie di risultati di modelli più grandi, come GPT-4o, e utilizzarle per mettere a punto modelli più piccoli, come GPT-4o-mini. L'intero processo di creazione del set di dati, messa a punto e valutazione può essere eseguito in modo più strutturato, automatizzato ed efficiente.
La semplificazione del processo di sviluppo, la minore latenza e i costi ridotti renderanno il modello GPT-4o di OpenAI una prospettiva interessante per gli sviluppatori che desiderano distribuire rapidamente applicazioni potenti. Sarà interessante vedere quali applicazioni saranno possibili grazie alle funzionalità multimodali.



