

I benchmark faticano a tenere il passo con l'avanzamento delle capacità dei modelli di intelligenza artificiale e il progetto Humanity's Last Exam vuole il vostro aiuto per risolvere il problema.
Il progetto è frutto della collaborazione tra il Center for AI Safety (CAIS) e la società di dati AI Scale AI. Il progetto mira a misurare quanto siamo vicini al raggiungimento di sistemi di IA di livello esperto, qualcosa che parametri di riferimento esistenti non sono in grado di farlo.
OpenAI e CAIS hanno sviluppato il popolare benchmark MMLU (Massive Multitask Language Understanding) nel 2021. All'epoca, secondo il CAIS, "i sistemi di intelligenza artificiale non avevano prestazioni migliori di quelle casuali".
Le impressionanti prestazioni del modello o1 di OpenAI hanno "distrutto i più popolari benchmark di ragionamento", secondo Dan Hendrycks, direttore esecutivo del CAIS.
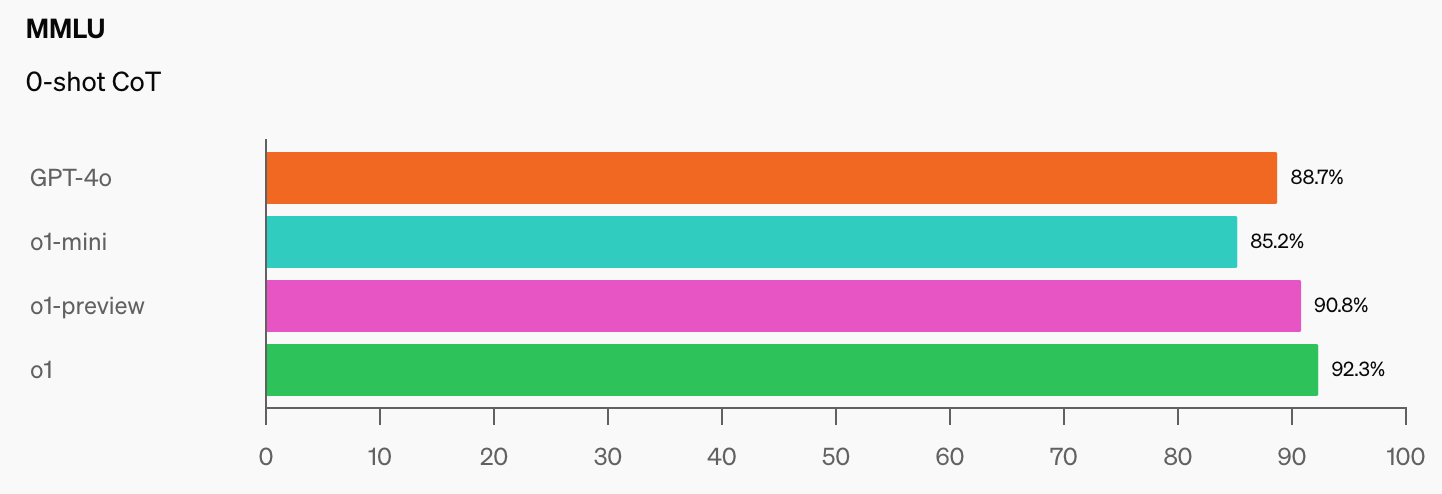
Una volta che i modelli di IA avranno raggiunto i 100% sul MMLU, come li misureremo? Il CAIS afferma: "I test esistenti sono diventati troppo facili e non siamo più in grado di monitorare bene gli sviluppi dell'IA o quanto siano lontani dal diventare esperti".
Quando si vede il salto nei punteggi di benchmark che o1 ha aggiunto alle cifre già impressionanti del GPT-4o, non ci vorrà molto prima che un modello AI superi l'MMLU.
Questo è oggettivamente vero. pic.twitter.com/gorahh86ee
- Ethan Mollick (@emollick) 17 settembre 2024
Humanity's Last Exam chiede alle persone di sottoporre domande che sarebbero davvero sorprendenti se un modello di intelligenza artificiale fornisse la risposta corretta. Vogliono domande da esame di dottorato, non quelle del tipo "quante R ci sono in Fragola" che mettono in crisi alcuni modelli.
Scale ha spiegato che "se i test esistenti diventano troppo facili, perdiamo la capacità di distinguere tra i sistemi di IA che possono superare gli esami di laurea e quelli che possono realmente contribuire alla ricerca di frontiera e alla risoluzione dei problemi".
Se avete una domanda originale che potrebbe mettere in difficoltà un modello avanzato di intelligenza artificiale, potreste aggiungere il vostro nome come coautore del documento del progetto e partecipare a un fondo di $500.000 che sarà assegnato alle domande migliori.
Per dare un'idea del livello a cui mira il progetto, Scale ha spiegato che "se un laureando scelto a caso può capire ciò che viene chiesto, è probabilmente troppo facile per i LLM di frontiera di oggi e di domani".
Ci sono alcune interessanti restrizioni sui tipi di domande che possono essere presentate. Non vogliono nulla che riguardi le armi chimiche, biologiche, radiologiche, nucleari o le armi informatiche utilizzate per attaccare le infrastrutture critiche.
Se pensate di avere una domanda che soddisfi i requisiti, potete inviarla qui.



