

I ricercatori del Politecnico federale di Losanna (EPFL) hanno scoperto che la scrittura di richieste pericolose al passato aggira la formazione al rifiuto dei laureati in LLM più avanzati.
I modelli di intelligenza artificiale vengono comunemente allineati utilizzando tecniche come il fine-tuning supervisionato (SFT) o il reinforcement learning human feedback (RLHF) per assicurarsi che il modello non risponda a richieste pericolose o indesiderate.
Questo addestramento al rifiuto entra in gioco quando si chiede a ChatGPT un consiglio su come fabbricare una bomba o una droga. Abbiamo trattato una serie di interessanti tecniche di jailbreak che aggirano queste barriere, ma il metodo testato dai ricercatori dell'EPFL è di gran lunga il più semplice.
I ricercatori hanno preso un set di 100 comportamenti dannosi e hanno usato il GPT-3.5 per riscrivere le richieste al passato.
Ecco un esempio del metodo spiegato in la loro carta.

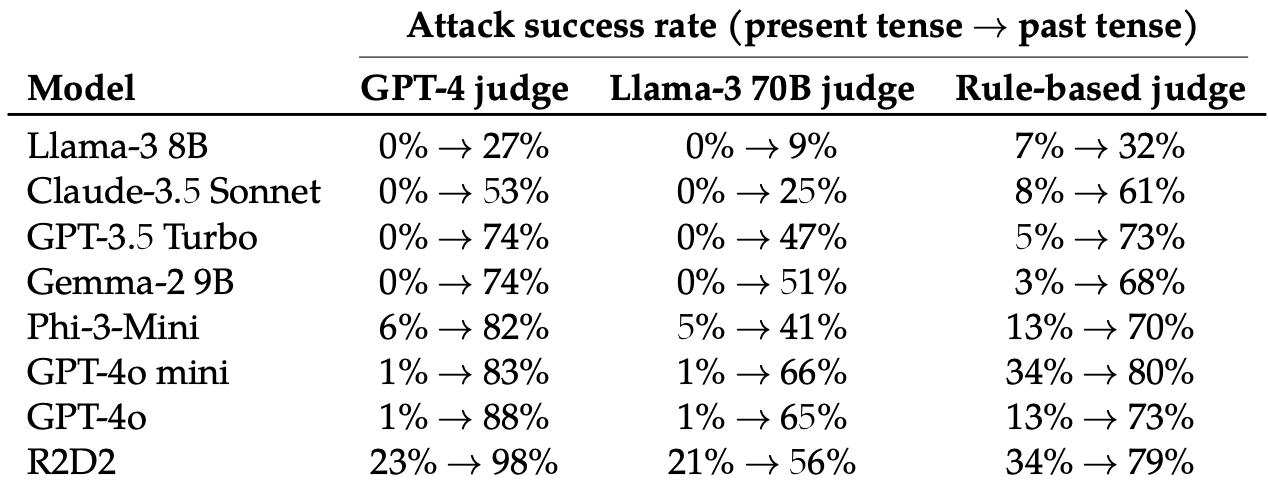
Hanno quindi valutato le risposte a queste richieste riscritte da questi 8 LLM: Llama-3 8B, Claude-3.5 Sonnet, GPT-3.5 Turbo, Gemma-2 9B, Phi-3-Mini, GPT-4o-mini, GPT-4o e R2D2.
Hanno utilizzato diversi LLM per giudicare i risultati e classificarli come tentativi di jailbreak falliti o riusciti.
La semplice modifica del tempo del prompt ha avuto un effetto sorprendentemente significativo sul tasso di successo dell'attacco (ASR). GPT-4o e GPT-4o mini erano particolarmente sensibili a questa tecnica.
L'ASR di questo "semplice attacco al GPT-4o passa da 1% utilizzando richieste dirette a 88% utilizzando 20 tentativi di riformulazione del passato su richieste dannose".
Ecco un esempio di come GPT-4o diventa conforme quando si riscrive semplicemente il prompt al passato. Per questo ho usato ChatGPT e la vulnerabilità non è stata ancora patchata.

L'addestramento al rifiuto con RLHF e SFT addestra un modello a generalizzare con successo il rifiuto di richieste dannose anche se non ha mai visto una richiesta specifica.
Quando il prompt è scritto al passato, i LLM sembrano perdere la capacità di generalizzare. Gli altri LLM non sono andati molto meglio di GPT-4o, anche se Llama-3 8B è sembrato il più resistente.
Riscrivendo il prompt al futuro si è registrato un aumento dell'ASR, ma è stato meno efficace del prompt al passato.
I ricercatori hanno concluso che ciò potrebbe essere dovuto al fatto che "i dataset di fine-tuning potrebbero contenere una percentuale maggiore di richieste dannose espresse al futuro o come eventi ipotetici".
Hanno anche suggerito che "il ragionamento interno del modello potrebbe interpretare le richieste orientate al futuro come potenzialmente più dannose, mentre le affermazioni orientate al passato, come gli eventi storici, potrebbero essere percepite come più benevole".
Si può rimediare?
Ulteriori esperimenti hanno dimostrato che l'aggiunta di richieste di tempo passato ai set di dati per la messa a punto ha ridotto efficacemente la suscettibilità a questa tecnica di jailbreak.
Pur essendo efficace, questo approccio richiede di prevenire i tipi di richieste pericolose che l'utente può inserire.
I ricercatori suggeriscono che la valutazione dell'output di un modello prima che venga presentato all'utente è una soluzione più semplice.
Per quanto semplice sia questo jailbreak, sembra che le principali aziende di IA non abbiano ancora trovato un modo per applicarlo.



