

L'Università di Stanford ha pubblicato l'AI Index Report 2024, in cui si osserva che il rapido progresso dell'IA rende sempre meno pertinenti i confronti con gli esseri umani.
Il rapporto annuale fornisce una visione completa delle tendenze e dello stato degli sviluppi dell'IA. Il rapporto afferma che i modelli di IA stanno migliorando così rapidamente che i parametri di riferimento utilizzati per misurarli stanno diventando sempre più irrilevanti.
Molti benchmark di settore mettono a confronto i modelli di intelligenza artificiale con la capacità degli esseri umani di eseguire compiti. Il benchmark Massive Multitask Language Understanding (MMLU) ne è un buon esempio.
Utilizza domande a scelta multipla per valutare gli LLM in 57 materie, tra cui matematica, storia, diritto ed etica. L'MMLU è il punto di riferimento per l'AI dal 2019.
Il punteggio di base umano sull'MMLU è di 89,8% e nel 2019 il modello AI medio ha ottenuto un punteggio di poco superiore a 30%. Solo 5 anni dopo, Gemini Ultra è diventato il primo modello a battere la soglia di riferimento umana con un punteggio di 90,04%.
Il rapporto rileva che "gli attuali sistemi di IA superano abitualmente le prestazioni umane su benchmark standard". Le tendenze del grafico sottostante sembrano indicare che il MMLU e altri parametri di riferimento devono essere sostituiti.
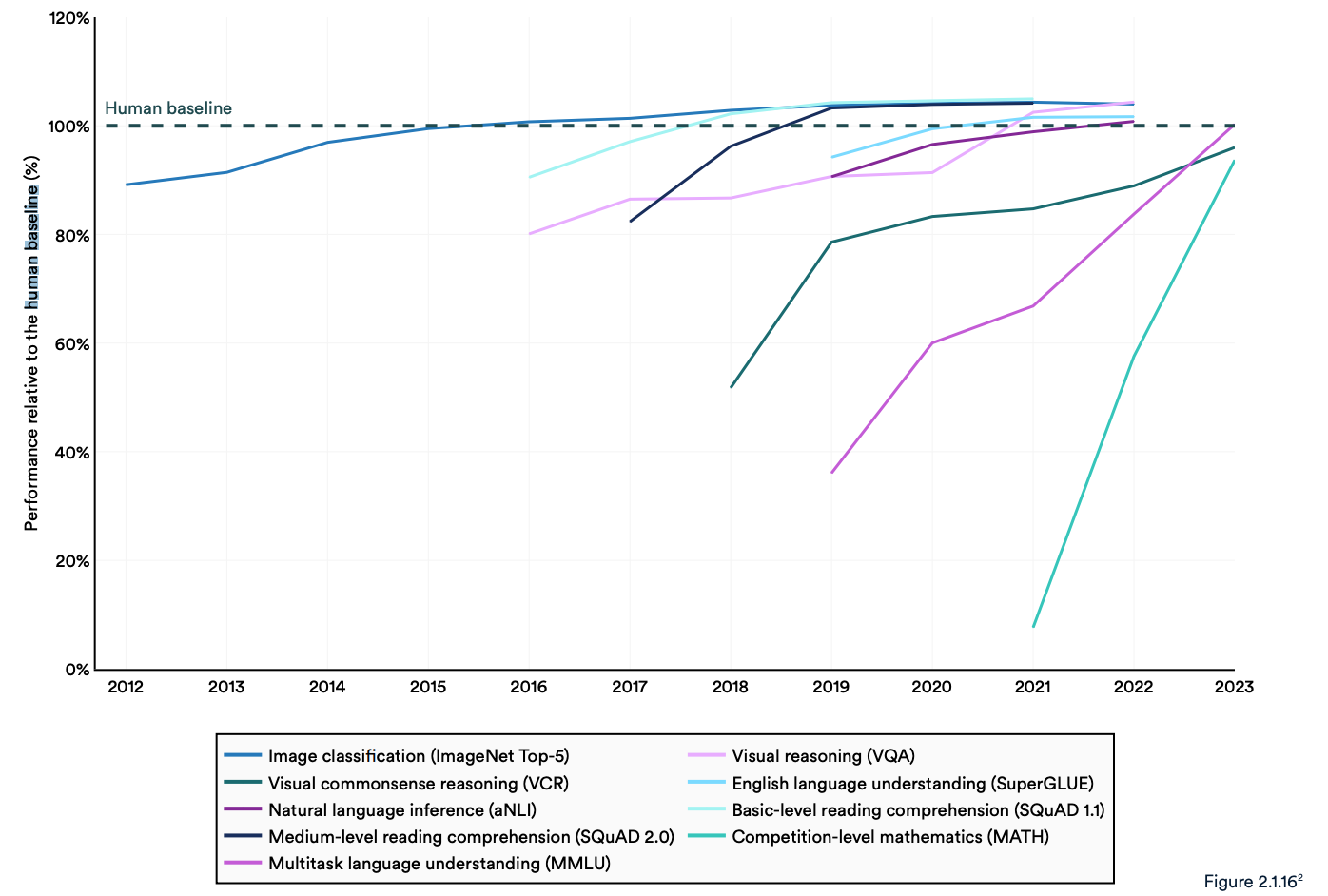
I modelli di intelligenza artificiale hanno raggiunto la saturazione delle prestazioni su benchmark consolidati come ImageNet, SQuAD e SuperGLUE, per cui i ricercatori stanno sviluppando test più impegnativi.
Un esempio è il Graduate-Level Google-Proof Q&A Benchmark (GPQA), che consente di confrontare i modelli di IA con persone veramente intelligenti, piuttosto che con l'intelligenza umana media.
Il test GPQA consiste in 400 domande a scelta multipla di livello universitario. Gli esperti che hanno conseguito o stanno conseguendo il dottorato di ricerca rispondono correttamente alle domande nel 65% dei casi.
Il documento del GPQA afferma che quando vengono poste domande al di fuori del loro campo, "i validatori non esperti altamente qualificati raggiungono solo un'accuratezza di 34%, nonostante abbiano trascorso in media oltre 30 minuti con accesso illimitato al web".
Il mese scorso Anthropic ha annunciato che Claude 3 ha ottenuto un punteggio di poco inferiore a 60% con 5 colpi di sollecitazione CoT. Avremo bisogno di un benchmark più grande.
Claude 3 ottiene un'accuratezza di ~60% su GPQA. È difficile per me sottovalutare quanto siano difficili queste domande: i dottori di ricerca letterali (in ambiti diversi da quelli delle domande) con accesso a Internet ottengono 34%.
I dottori di ricerca *nello stesso ambito* (anche con accesso a Internet!) ottengono una precisione di 65% - 75%. https://t.co/ARAiCNXgU9 pic.twitter.com/PH8J13zIef
- david rein (@idavidrein) 4 marzo 2024
Valutazioni umane e sicurezza
Il rapporto rileva che l'IA deve ancora affrontare problemi significativi: "Non è in grado di trattare in modo affidabile i fatti, di eseguire ragionamenti complessi o di spiegare le proprie conclusioni".
Queste limitazioni contribuiscono a un'altra caratteristica del sistema di IA che, secondo il rapporto, è scarsamente misurata; Sicurezza dell'intelligenza artificiale. Non abbiamo parametri di riferimento efficaci che ci permettano di dire: "Questo modello è più sicuro di quell'altro".
In parte perché è difficile da misurare e in parte perché "gli sviluppatori di IA mancano di trasparenza, soprattutto per quanto riguarda la divulgazione dei dati e delle metodologie di addestramento".
Il rapporto ha rilevato che una tendenza interessante nel settore è quella di affidare a un pubblico le valutazioni umane delle prestazioni dell'IA, piuttosto che ai test di benchmark.
È difficile classificare l'estetica o la prosa di un modello con un test. Di conseguenza, il rapporto afferma che "il benchmarking ha iniziato lentamente a spostarsi verso l'incorporazione di valutazioni umane come la Chatbot Arena Leaderboard piuttosto che di classifiche computerizzate come ImageNet o SQuAD".
Mentre i modelli di intelligenza artificiale vedono scomparire la linea di base umana nello specchietto retrovisore, il sentiment potrebbe determinare il modello che sceglieremo di utilizzare.
Le tendenze indicano che i modelli di IA finiranno per essere più intelligenti di noi e più difficili da misurare. Potremmo presto ritrovarci a dire: "Non so perché, ma questo mi piace di più".



