

I ricercatori di DeepMind e dell'Università di Stanford hanno sviluppato un agente di IA che controlla i LLM e consente di effettuare un benchmarking della fattualità dei modelli di IA.
Anche i migliori modelli di intelligenza artificiale tendono a allucinare a volte. Se chiedete a ChatGPT di fornirvi i fatti su un argomento, più lunga è la sua risposta e più è probabile che includa alcuni fatti non veri.
Quali modelli sono più accurati di altri nel generare risposte lunghe? È difficile dirlo, perché finora non avevamo un parametro di riferimento che misurasse la fattualità delle risposte lunghe dei LLM.
DeepMind ha utilizzato il GPT-4 per creare LongFact, un insieme di 2.280 prompt sotto forma di domande relative a 38 argomenti. Questi prompt sollecitano risposte di tipo lungo da parte del LLM sottoposto al test.
Hanno quindi creato un agente AI che utilizza GPT-3.5-turbo per utilizzare Google e verificare la veridicità delle risposte generate dall'LLM. Il metodo è stato chiamato Search-Augmented Factuality Evaluator (SAFE).
SAFE innanzitutto suddivide la risposta in forma lunga del LLM in singoli fatti. Quindi invia richieste di ricerca a Google Search e valuta la veridicità del fatto in base alle informazioni contenute nei risultati della ricerca.
Ecco un esempio dal sito carta di ricerca.
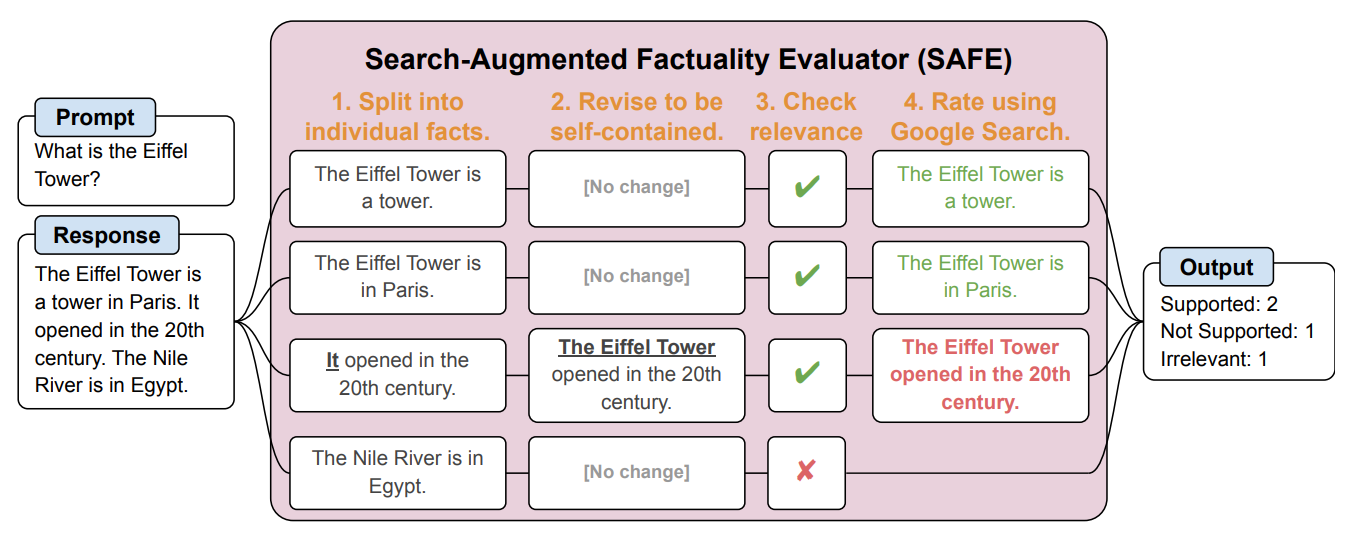
I ricercatori affermano che SAFE raggiunge "prestazioni sovrumane" rispetto agli annotatori umani che effettuano il fact-checking.
SAFE si è trovato d'accordo con il 72% delle annotazioni umane e, nei casi in cui si è discostato dagli umani, ha avuto ragione il 76% delle volte. Inoltre, è risultato 20 volte più economico degli annotatori umani in crowdsourcing. Quindi, i LLM sono verificatori di fatti migliori e più economici degli esseri umani.
La qualità della risposta dei LLM testati è stata misurata in base al numero di fatti nella risposta e al grado di veridicità dei singoli fatti.
La metrica utilizzata (F1@K) stima il numero "ideale" di fatti preferito dall'uomo in una risposta. I test di riferimento hanno utilizzato 64 come mediana per K e 178 come massimo.
In parole povere, F1@K è una misura di "La risposta mi ha fornito tutti i fatti che volevo?" combinata con "Quanti di questi fatti erano veri?".
Qual è l'LLM più efficace?
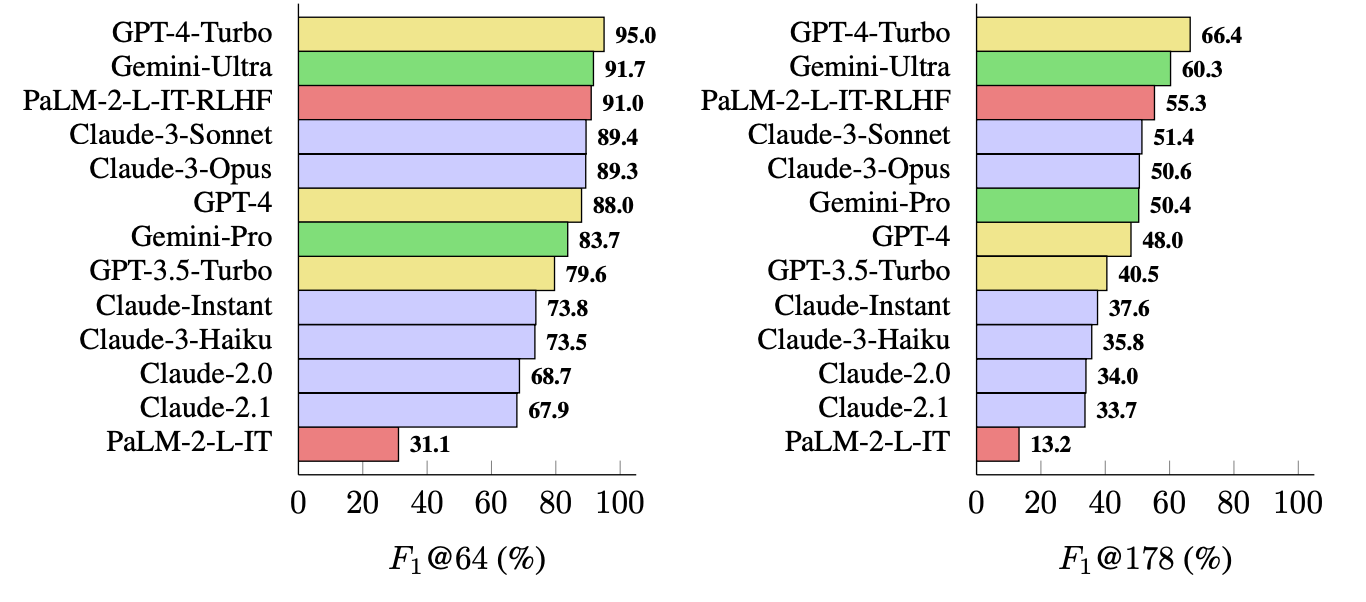
I ricercatori hanno utilizzato LongFact per sollecitare 13 LLM delle famiglie Gemini, GPT, Claude e PaLM-2. Hanno poi utilizzato SAFE per valutare la fattualità delle loro risposte.
Il GPT-4-Turbo è in cima alla lista dei modelli più concreti nella generazione di risposte lunghe. È seguito da vicino da Gemini-Ultra e PaLM-2-L-IT-RLHF. I risultati hanno mostrato che gli LLM più grandi sono più fattuali di quelli più piccoli.
Il calcolo di F1@K probabilmente entusiasmerebbe gli scienziati dei dati, ma, per semplicità, questi risultati di benchmark mostrano quanto ogni modello sia efficace quando restituisce risposte di lunghezza media e più lunghe alle domande.
SAFE è un modo economico ed efficace per quantificare la fattualità dei long-form LLM. È più veloce ed economico degli esseri umani nel fact-checking, ma dipende ancora dalla veridicità delle informazioni che Google restituisce nei risultati della ricerca.
DeepMind ha rilasciato SAFE per l'uso pubblico e ha suggerito che potrebbe aiutare a migliorare la fattualità dei LLM attraverso un migliore preaddestramento e una messa a punto. Potrebbe anche consentire a un LLM di verificare i fatti prima di presentare l'output a un utente.
OpenAI sarà felice di vedere che una ricerca di Google mostra che GPT-4 batte Gemini in un altro benchmark.



