

Gli ingegneri di Apple hanno sviluppato un sistema di intelligenza artificiale che risolve i riferimenti complessi alle entità sullo schermo e alle conversazioni degli utenti. Il modello leggero potrebbe essere la soluzione ideale per gli assistenti virtuali su dispositivo.
Gli esseri umani sono bravi a risolvere i riferimenti nelle conversazioni con gli altri. Quando usiamo termini come "quello in basso" o "lui", capiamo a cosa si riferisce la persona in base al contesto della conversazione e alle cose che possiamo vedere.
È molto più difficile per un modello di intelligenza artificiale fare questo. I LLM multimodali come GPT-4 sono bravi a rispondere alle domande sulle immagini, ma sono costosi da addestrare e richiedono un notevole overhead di calcolo per elaborare ogni domanda su un'immagine.
Gli ingegneri di Apple hanno adottato un approccio diverso con il loro sistema, chiamato ReALM (Reference Resolution As Language Modeling). La carta vale la pena di leggere per avere maggiori dettagli sul loro processo di sviluppo e di test.
ReALM utilizza un LLM per elaborare le entità di conversazione, quelle sullo schermo e quelle di sottofondo (allarmi, musica di sottofondo) che compongono le interazioni di un utente con un agente AI virtuale.
Ecco un esempio del tipo di interazione che un utente potrebbe avere con un agente AI.
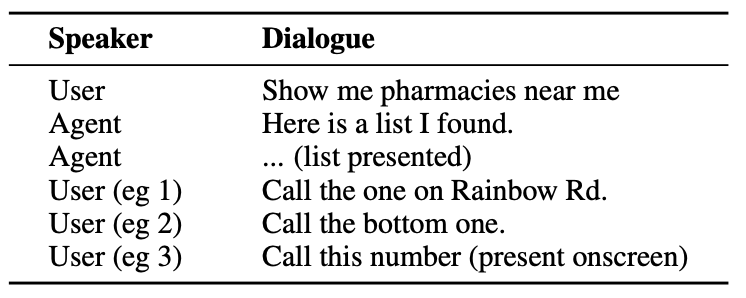
L'agente deve comprendere entità conversazionali come il fatto che quando l'utente dice "quello" si riferisce al numero di telefono della farmacia.
Deve anche comprendere il contesto visivo quando l'utente dice "quello in basso", e questo è l'aspetto in cui l'approccio di ReALM si differenzia da modelli come il GPT-4.
ReALM si basa su codificatori a monte per analizzare gli elementi sullo schermo e le loro posizioni. ReALM ricostruisce quindi lo schermo in rappresentazioni puramente testuali, da sinistra a destra e dall'alto in basso.
In parole povere, utilizza il linguaggio naturale per riassumere la schermata dell'utente.
Ora, quando un utente pone una domanda su qualcosa sullo schermo, il modello linguistico elabora la descrizione testuale della schermata, invece di dover utilizzare un modello di visione per elaborare l'immagine sullo schermo.
I ricercatori hanno creato set di dati sintetici di entità conversazionali, sullo schermo e sullo sfondo e hanno testato ReALM e altri modelli per verificare la loro efficacia nel risolvere i riferimenti nei sistemi conversazionali.
La versione più piccola di ReALM (80M parametri) si è comportata in modo comparabile con GPT-4 e la sua versione più grande (3B parametri) ha superato in modo sostanziale GPT-4.
ReALM è un modello di dimensioni ridotte rispetto al GPT-4. La sua risoluzione di riferimento superiore lo rende la scelta ideale per un assistente virtuale che può esistere sul dispositivo senza compromettere le prestazioni.
ReALM non funziona altrettanto bene con le immagini più complesse o con le richieste sfumate degli utenti, ma potrebbe funzionare bene come assistente virtuale in auto o sul dispositivo. Immaginate se Siri potesse "vedere" lo schermo del vostro iPhone e rispondere ai riferimenti agli elementi sullo schermo.
Apple è stata un po' lenta nell'uscire dai blocchi, ma i recenti sviluppi, come il loro Modello MM1 e ReALM dimostrano che molto sta accadendo a porte chiuse.



