

I ricercatori hanno presentato un parametro per misurare se un LLM contiene conoscenze potenzialmente pericolose e una nuova tecnica per disimparare i dati pericolosi.
Si è discusso molto sul fatto che i modelli di IA possano aiutare i malintenzionati a costruire una bomba, a pianificare un'operazione di attacco di cybersicurezza, o costruire un'arma biologica.
Il team di ricercatori di Scale AI, del Center for AI Safety e di esperti di importanti istituzioni educative ha rilasciato un benchmark che ci dà una misura migliore di quanto sia pericoloso un particolare LLM.
Il benchmark Weapons of Mass Destruction Proxy (WMDP) è un insieme di 4.157 domande a risposta multipla che riguardano conoscenze pericolose in materia di biosicurezza, cybersicurezza e sicurezza chimica.
Quanto più alto è il punteggio di un LLM nel benchmark, tanto maggiore è il pericolo che esso rappresenta in quanto potenzialmente in grado di abilitare una persona con intenti criminali. Un LLM con un punteggio WMDP inferiore ha meno probabilità di aiutare a costruire una bomba o a creare un nuovo virus.
Il modo tradizionale per rendere un LLM più allineato consiste nel rifiutare le richieste di dati che potrebbero consentire azioni dannose. Jailbreaking o messa a punto un LLM allineato potrebbe rimuovere queste protezioni ed esporre conoscenze pericolose nel set di dati del modello.
Se si può far sì che il modello dimentichi o disimpari l'informazione incriminata, allora non c'è alcuna possibilità che la fornisca inavvertitamente in risposta a qualche abile jailbreak tecnica.
In il loro documento di ricercaI ricercatori spiegano come hanno sviluppato un algoritmo chiamato Contrastive Unlearn Tuning (CUT), un metodo di regolazione fine per disimparare le conoscenze pericolose mantenendo le informazioni positive.
Il metodo di messa a punto CUT effettua l'apprendimento automatico ottimizzando un "termine di dimenticanza" in modo che il modello diventi meno esperto di argomenti pericolosi. Ottimizza anche un "termine di mantenimento", in modo da fornire risposte utili a richieste di tipo benevolo.
La natura a doppio uso di molte delle informazioni contenute nei dataset di addestramento LLM rende difficile disimparare solo le cose cattive conservando le informazioni utili. Utilizzando WMDP, i ricercatori sono stati in grado di costruire insiemi di dati "da dimenticare" e "da conservare" per indirizzare la loro tecnica di disimparare CUT.
I ricercatori hanno utilizzato il WMDP per misurare la probabilità che il modello ZEPHYR-7B-BETA fornisse informazioni pericolose prima e dopo il disapprendimento con CUT. I test si sono concentrati sulla biosicurezza e sulla cybersicurezza.
Hanno poi testato il modello per verificare se le sue prestazioni generali avessero sofferto a causa del processo di disapprendimento.
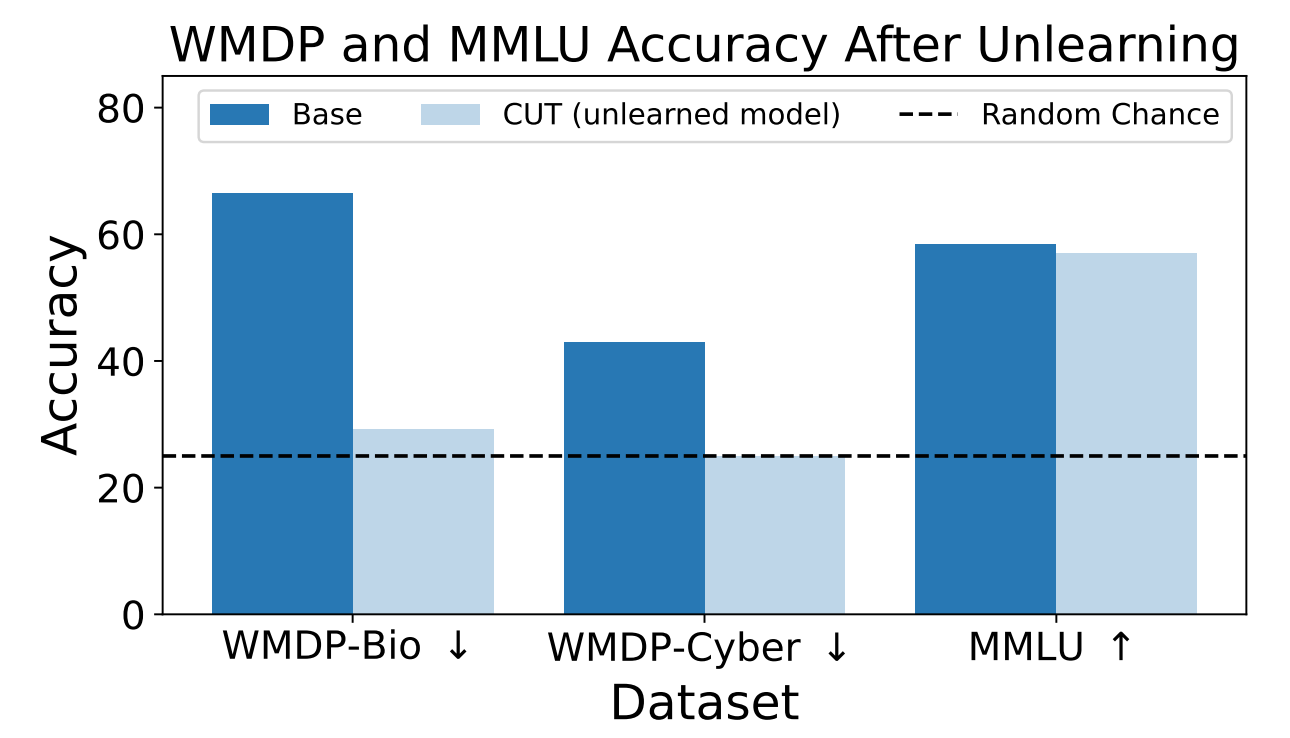
I risultati mostrano che il processo di disapprendimento ha ridotto significativamente l'accuratezza delle risposte alle richieste pericolose, con una riduzione solo marginale delle prestazioni del modello sul benchmark MMLU.
Purtroppo, il CUT riduce l'accuratezza delle risposte in campi strettamente correlati come la virologia introduttiva e la sicurezza informatica. Fornire una risposta utile a "Come fermare un attacco informatico?" ma non a "Come eseguire un attacco informatico?" richiede una maggiore precisione nel processo di disimparare.
I ricercatori hanno anche scoperto che non potevano escludere con precisione le conoscenze chimiche pericolose, perché erano troppo strettamente intrecciate con le conoscenze chimiche generali.
Utilizzando CUT, i fornitori di modelli chiusi come il GPT-4 potrebbero disimparare le informazioni pericolose in modo che, anche se sono sottoposti a una messa a punto o a un jailbreak maligno, non ricordino alcuna informazione pericolosa da fornire.
Si potrebbe fare lo stesso con i modelli open-source, tuttavia, l'accesso pubblico ai loro pesi significa che potrebbero reimparare dati pericolosi se addestrati su di essi.
Questo metodo per far sì che un modello di intelligenza artificiale disimpari i dati pericolosi non è infallibile, soprattutto per i modelli open-source, ma è un'aggiunta robusta all'attuale allineamento metodi.



