

Apple non ha ancora rilasciato ufficialmente un modello di intelligenza artificiale, ma un nuovo documento di ricerca fornisce un'idea dei progressi dell'azienda nello sviluppo di modelli con capacità multimodali all'avanguardia.
La cartaintitolato "MM1: Methods, Analysis & Insights from Multimodal LLM Pre-training", presenta la famiglia di MLLM di Apple chiamata MM1.
MM1 mostra capacità impressionanti nella didascalia delle immagini, nella risposta alle domande visive (VQA) e nell'inferenza del linguaggio naturale. I ricercatori spiegano che la scelta accurata delle coppie immagine-didascalia ha permesso di ottenere risultati superiori, soprattutto in scenari di apprendimento con pochi scatti.
Ciò che distingue l'MM1 dagli altri MLLM è la sua superiore capacità di seguire istruzioni su più immagini e di ragionare sulle scene complesse che gli vengono presentate.
I modelli MM1 contengono fino a 30B parametri, il triplo di quelli del GPT-4V, il componente che conferisce al GPT-4 di OpenAI le sue capacità di visione.
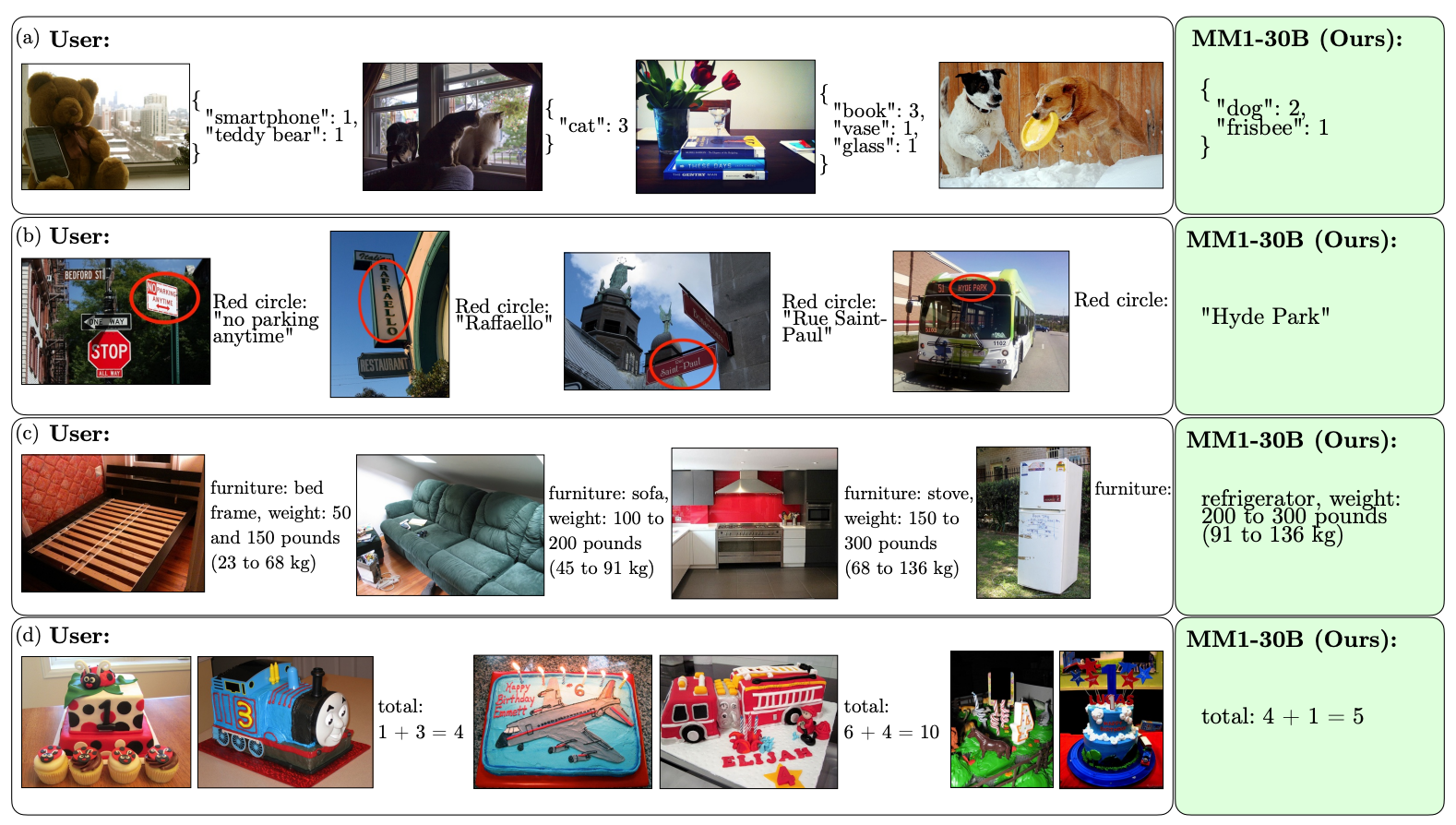
Ecco alcuni esempi delle capacità VQA di MM1.

MM1 è stato sottoposto a un preaddestramento multimodale su larga scala su "un dataset di 500 milioni di documenti interlacciati immagine-testo, contenenti 1B immagini e 500B token di testo".
L'ampiezza e la diversità del suo preallenamento consentono a MM1 di eseguire predizioni impressionanti nel contesto e di seguire la formattazione personalizzata con un numero ridotto di esempi di pochi scatti. Ecco alcuni esempi di come MM1 apprende l'output e il formato desiderato da soli 3 esempi.
Per creare modelli di intelligenza artificiale in grado di "vedere" e ragionare è necessario un connettore visione-linguaggio che traduca le immagini e il linguaggio in una rappresentazione unificata che il modello possa utilizzare per ulteriori elaborazioni.
I ricercatori hanno scoperto che il design del connettore visione-linguaggio è stato meno determinante per le prestazioni di MM1. È interessante notare che sono stati la risoluzione dell'immagine e il numero di token dell'immagine ad avere il maggiore impatto.
È interessante vedere quanto Apple sia stata aperta nel condividere la sua ricerca con la più ampia comunità dell'intelligenza artificiale. I ricercatori affermano che "in questo articolo documentiamo il processo di costruzione di MLLM e cerchiamo di formulare lezioni di progettazione che speriamo possano essere utili alla comunità".
I risultati pubblicati probabilmente influenzeranno la direzione presa da altri sviluppatori di MMLM per quanto riguarda l'architettura e le scelte dei dati di pre-training.
Resta da vedere come i modelli MM1 saranno implementati nei prodotti Apple. Gli esempi pubblicati delle capacità dell'MM1 lasciano intendere che Siri diventerà molto più intelligente quando imparerà a vedere.



