

Nonostante i rapidi progressi dei LLM, la nostra comprensione di come questi modelli affrontino input più lunghi rimane scarsa.
Mosh Levy, Alon Jacoby e Yoav Goldberg, dell'Università Bar-Ilan e dell'Allen Institute for AI, hanno studiato come le prestazioni dei modelli linguistici di grandi dimensioni (LLM) variano al variare della lunghezza del testo in ingresso che devono elaborare.
Hanno sviluppato un framework di ragionamento specifico per questo scopo, che ha permesso di analizzare l'influenza della lunghezza dell'input sul ragionamento LLM in un ambiente controllato.
Il quadro delle domande proponeva diverse versioni della stessa domanda, ognuna delle quali conteneva le informazioni necessarie per rispondere alla domanda stessa, infarcite di testo aggiuntivo irrilevante di varia lunghezza e tipologia.
Ciò consente di isolare la lunghezza dell'ingresso come variabile, garantendo che le variazioni delle prestazioni del modello possano essere attribuite direttamente alla lunghezza dell'ingresso.
Risultati principali
Levy, Jacoby e Goldberg hanno scoperto che gli LLM mostrano un notevole calo delle prestazioni di ragionamento a lunghezze di input molto inferiori a quelle che gli sviluppatori affermano di poter gestire. Hanno documentato le loro scoperte in questo studio.
Il declino è stato osservato in modo coerente in tutte le versioni del set di dati, indicando un problema sistemico nella gestione di input più lunghi piuttosto che un problema legato a campioni di dati o architetture di modelli specifici.
Come descrivono i ricercatori, "i nostri risultati mostrano un notevole degrado nelle prestazioni di ragionamento dei LLM a lunghezze di input molto inferiori al loro massimo tecnico. Dimostriamo che la tendenza al degrado appare in ogni versione del nostro set di dati, anche se con intensità diverse".

Inoltre, lo studio evidenzia come le metriche tradizionali come la perplessità, comunemente utilizzate per valutare i LLM, non siano correlate con le prestazioni dei modelli su compiti di ragionamento che prevedono input lunghi.
Ulteriori approfondimenti hanno evidenziato che il degrado delle prestazioni non dipendeva solo dalla presenza di informazioni irrilevanti (padding), ma si osservava anche quando tale padding consisteva in una duplicazione di informazioni rilevanti.
Se teniamo insieme le due campate principali e aggiungiamo del testo intorno ad esse, la precisione cala già. Introducendo paragrafi tra gli intervalli, i risultati calano molto di più. Il calo si verifica sia quando i testi aggiunti sono simili a quelli del compito, sia quando sono completamente diversi. 3/7 pic.twitter.com/c91l9uzyme
- Mosh Levy (@mosh_levy) 26 febbraio 2024
Ciò suggerisce che la sfida per i LLM consiste nel filtrare il rumore e nell'elaborazione intrinseca di sequenze di testo più lunghe.
Ignorare le istruzioni
Un'area critica della modalità di fallimento evidenziata nello studio è la tendenza degli LLM a ignorare le istruzioni incorporate nell'input quando la lunghezza dell'input aumenta.
I modelli a volte generavano anche risposte che indicavano incertezza o mancanza di informazioni sufficienti, come "Il testo non contiene informazioni sufficienti", nonostante tutte le informazioni necessarie.
Nel complesso, sembra che i LLM facciano sempre più fatica a dare priorità e a concentrarsi sulle informazioni chiave, comprese le istruzioni dirette, con l'aumentare della lunghezza degli input.
Mostrare pregiudizi nelle risposte
Un altro problema degno di nota è stato l'aumento delle distorsioni nelle risposte dei modelli quando gli input sono diventati più lunghi.
In particolare, i LLM erano orientati a rispondere "Falso" all'aumentare della lunghezza degli input. Questo errore indica una distorsione nella stima delle probabilità o nei processi decisionali all'interno del modello, forse come meccanismo difensivo in risposta all'aumento dell'incertezza dovuto alla lunghezza degli input.
L'inclinazione a favorire le risposte "Falso" potrebbe anche riflettere uno squilibrio di fondo nei dati di addestramento o un artefatto del processo di addestramento dei modelli, dove le risposte negative possono essere sovrarappresentate o associate a contesti di incertezza e ambiguità.
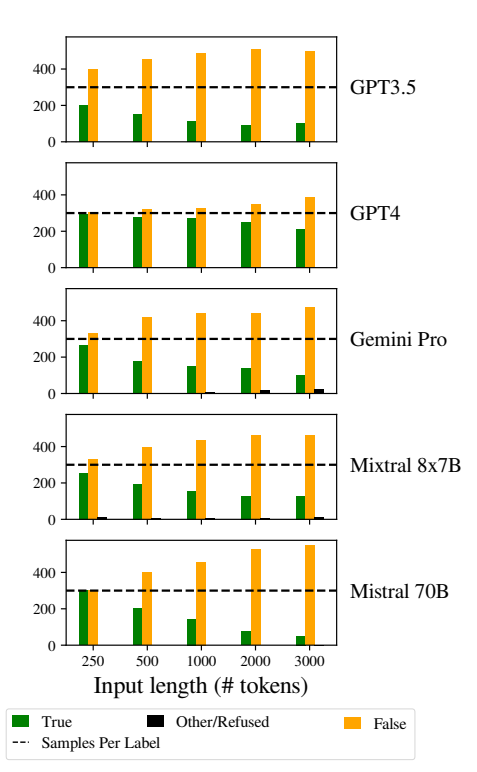
Questa distorsione influisce sull'accuratezza dei risultati dei modelli e solleva preoccupazioni circa l'affidabilità e l'equità dei LLM nelle applicazioni che richiedono una comprensione sfumata e l'imparzialità.
L'implementazione di robuste strategie di rilevamento e mitigazione dei bias durante le fasi di addestramento e messa a punto dei modelli è essenziale per ridurre i bias ingiustificati nelle risposte dei modelli.
EAssicurarsi che i dataset di addestramento siano diversi, equilibrati e rappresentativi di un'ampia gamma di scenari può aiutare a minimizzare le distorsioni e a migliorare la generalizzazione dei modelli.
Ciò contribuisce a altri studi recenti che evidenziano problemi fondamentali nel funzionamento degli LLM, portando così a una situazione in cui il "debito tecnico" potrebbe minacciare la funzionalità e l'integrità del modello nel tempo.



