

I ricercatori della UC San Diego e della New York University hanno sviluppato V*, un algoritmo di ricerca guidata LLM che è molto migliore di GPT-4V per quanto riguarda la comprensione del contesto e la precisa individuazione di specifici elementi visivi nelle immagini.
I modelli linguistici multimodali di grandi dimensioni (MLLM) come GPT-4V di OpenAI ci hanno stupito l'anno scorso per la loro capacità di rispondere a domande sulle immagini. Per quanto impressionante sia GPT-4V, a volte fatica quando le immagini sono molto complesse e spesso non riesce a cogliere piccoli dettagli.
L'algoritmo V* utilizza un LLM di Visual Question Answering (VQA) per individuare l'area dell'immagine su cui concentrarsi per rispondere a una domanda visiva. I ricercatori chiamano questa combinazione Show, sEArch, and telL (SEAL).
Se qualcuno vi fornisse un'immagine ad alta risoluzione e vi facesse una domanda al riguardo, la vostra logica vi guiderebbe a zoomare su un'area in cui è più probabile trovare l'oggetto in questione. SEAL utilizza V* per analizzare le immagini in modo simile.
Un modello di ricerca visiva potrebbe semplicemente dividere un'immagine in blocchi, zoomare su ciascun blocco ed elaborarlo per trovare l'oggetto in questione, ma questo è computazionalmente molto inefficiente.
Quando viene richiesta una domanda testuale su un'immagine, V* cerca innanzitutto di individuare direttamente il target dell'immagine. Se non è in grado di farlo, chiede all'MLLM di utilizzare un approccio di buon senso per identificare l'area dell'immagine in cui è più probabile che si trovi l'obiettivo.
In questo modo la ricerca si concentra solo su quell'area, anziché tentare una ricerca "zoomata" dell'intera immagine.

Quando al GPT-4V viene richiesto di rispondere a domande su un'immagine che richiede un'elaborazione visiva estesa di immagini ad alta risoluzione, fa fatica. SEAL con V* si comporta molto meglio.

Alla domanda "Che tipo di bevanda possiamo comprare da quel distributore automatico?". SEAL ha risposto "Coca-Cola", mentre GPT-4V ha indovinato "Pepsi".
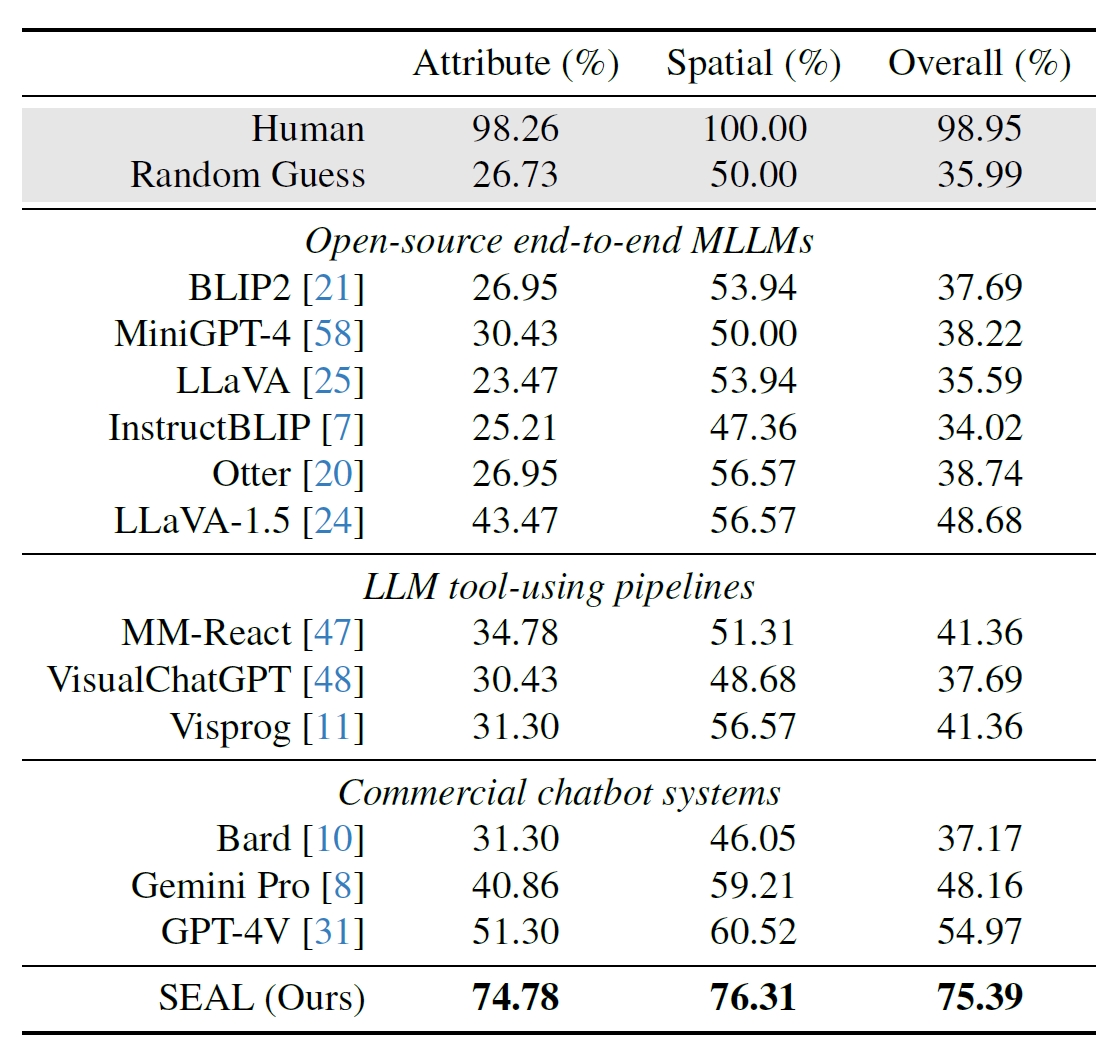
I ricercatori hanno utilizzato 191 immagini ad alta risoluzione tratte dal set di dati Segment Anything (SAM) di Meta e hanno creato un benchmark per verificare le prestazioni di SEAL rispetto ad altri modelli. Il benchmark V*Bench testa due compiti: il riconoscimento degli attributi e il ragionamento delle relazioni spaziali.
Le figure seguenti mostrano le prestazioni umane rispetto ai modelli open-source, a quelli commerciali come GPT-4V e a SEAL. L'aumento delle prestazioni di SEAL da parte di V* è particolarmente impressionante perché l'MLLM sottostante che utilizza è LLaVa-7b, che è molto più piccolo di GPT-4V.
Questo approccio intuitivo all'analisi delle immagini sembra funzionare davvero bene, con una serie di esempi impressionanti sul sito sintesi del documento su GitHub.
Sarà interessante vedere se altri MLLM, come quelli di OpenAI o di Google, adotteranno un approccio simile.
Alla domanda su quale bevanda fosse venduta dal distributore automatico nell'immagine qui sopra, il bardo di Google ha risposto: "Non c'è nessun distributore automatico in primo piano". Forse Gemini Ultra farà un lavoro migliore.
Per il momento, sembra che SEAL e il suo nuovo algoritmo V* siano in vantaggio rispetto ad alcuni dei più grandi modelli multimodali per quanto riguarda le domande visive.



