

Google DeepMind ha rilasciato una suite di nuovi strumenti per aiutare i robot ad apprendere autonomamente in modo più rapido ed efficiente in ambienti nuovi.
Addestrare un robot a svolgere un compito specifico in un singolo ambiente è un compito ingegneristico relativamente semplice. Se i robot ci saranno veramente utili in futuro, dovranno essere in grado di eseguire una serie di compiti generali e imparare a svolgerli in ambienti che non hanno mai sperimentato prima.
L'anno scorso DeepMind ha rilasciato il suo Modello di controllo robotico RT-2 e RT-X. RT-2 traduce comandi vocali o di testo in azioni robotiche.
I nuovi strumenti annunciati da DeepMind si basano su RT-2 e ci avvicinano a robot autonomi che esplorano ambienti diversi e imparano nuove abilità.
Negli ultimi due anni, i modelli di fondazione di grandi dimensioni si sono dimostrati in grado di percepire e ragionare sul mondo che ci circonda, sbloccando una possibilità fondamentale per la robotica in scala.
Presentiamo AutoRT, un framework per l'orchestrazione di agenti robotici in natura utilizzando modelli di fondazione! pic.twitter.com/x3YdO10kqq
- Keerthana Gopalakrishnan (@keerthanpg) 4 gennaio 2024
AutoRT
AutoRT combina un modello linguistico di base (Large Language Model, LLM) con un modello linguistico visivo (Visual Language Model, VLM) e con un modello di controllo robotico come RT-2.
Il VLM consente al robot di valutare la scena di fronte a sé e di passare la descrizione al LLM. L'LLM valuta gli oggetti identificati e la scena e genera un elenco di compiti potenziali che il robot potrebbe eseguire.
I compiti vengono valutati in base alla loro sicurezza, alle capacità del robot e alla possibilità di aggiungere nuove competenze o diversità alla base di conoscenze di AutoRT.
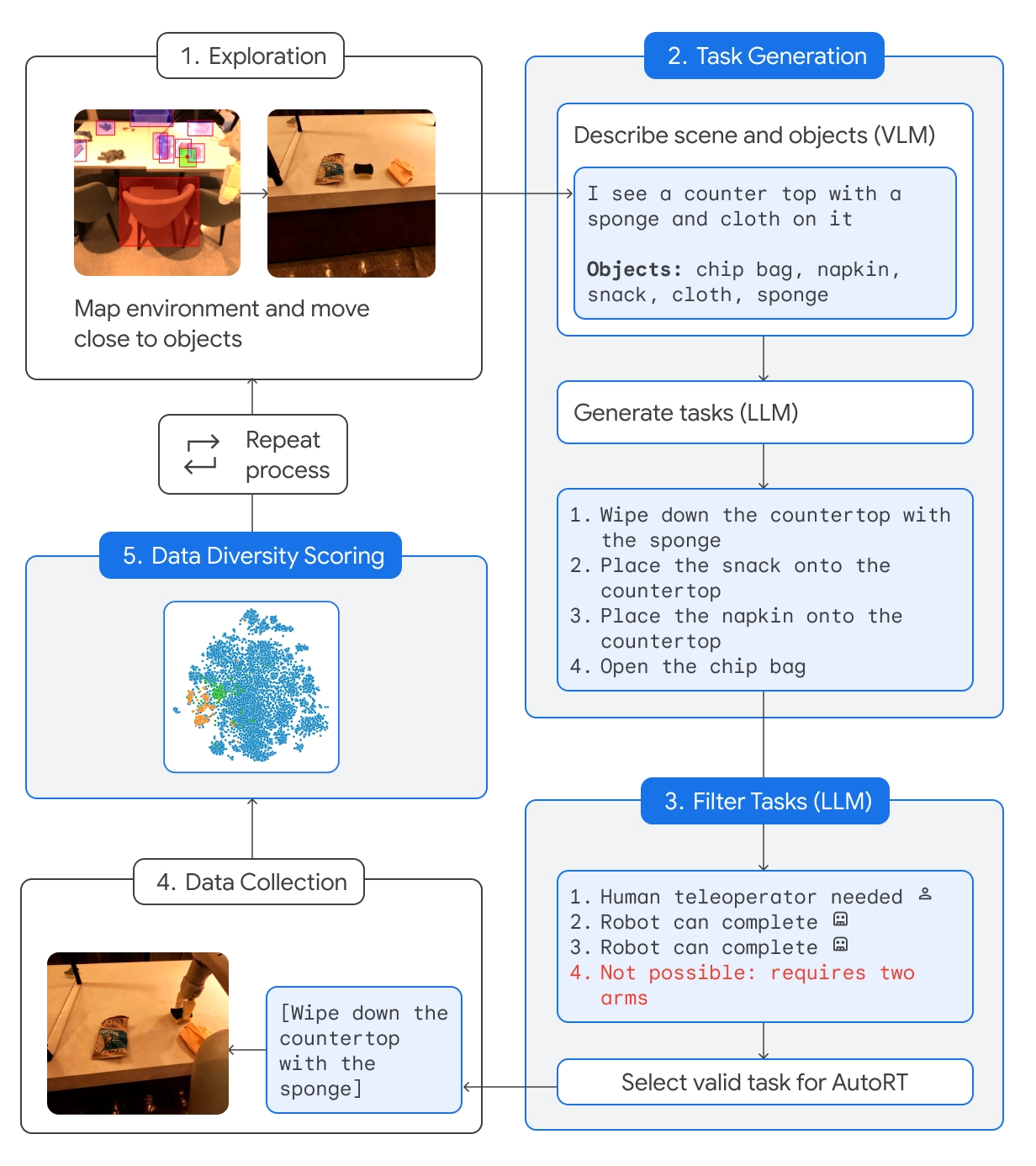
DeepMind afferma che con AutoRT ha "orchestrato in sicurezza fino a 20 robot simultaneamente, e fino a 52 robot unici in totale, in una varietà di edifici adibiti a uffici, raccogliendo un set di dati diversificato che comprende 77.000 prove robotiche su 6.650 compiti unici".
Costituzione robotica
Mandare un robot in ambienti nuovi significa che incontrerà situazioni potenzialmente pericolose che non possono essere pianificate in modo specifico. Utilizzando una costituzione robotica come guida, i robot hanno a disposizione un sistema di sicurezza generalizzato.
La costituzione robotica si ispira alle 3 leggi della robotica di Isaac Asimov:
- Un robot non può ferire un essere umano.
- Il robot non deve svolgere compiti che coinvolgano esseri umani, animali o esseri viventi. Questo robot non deve interagire con oggetti affilati, come ad esempio un coltello.
- Questo robot ha un solo braccio e quindi non può eseguire compiti che richiedono due braccia. Ad esempio, non può aprire una bottiglia.
Seguendo queste linee guida si evita che il robot selezioni un compito dall'elenco delle opzioni che potrebbe ferire qualcuno o danneggiare se stesso o qualcos'altro.
SARA-RT
Self-Adaptive Robust Attention for Robotics Transformers (SARA-RT) prende modelli come RT-2 e li rende più efficienti.
L'architettura della rete neurale di RT-2 si basa su moduli di attenzione di complessità quadratica. Ciò significa che se si raddoppia l'input, aggiungendo un nuovo sensore o aumentando la risoluzione della telecamera, sono necessarie quattro volte le risorse computazionali.
SARA-RT utilizza un modello di attenzione lineare per mettere a punto il modello robotico. Il risultato è stato un miglioramento della velocità di 14% e un aumento della precisione di 10%.
Traiettoria RT
Convertire un compito semplice come pulire un tavolo in istruzioni che un robot possa seguire è complicato. Il compito deve essere convertito dal linguaggio naturale in una sequenza codificata di movimenti e rotazioni del motore per azionare le parti mobili del robot.
RT-Trajectory aggiunge una sovrapposizione visiva 2D a un video di addestramento, in modo che il robot possa apprendere intuitivamente il tipo di movimento necessario per svolgere il compito.
Così, invece di limitarsi a istruire il robot a "pulire il tavolo", la dimostrazione e la sovrapposizione dei movimenti gli consentono di apprendere più rapidamente la nuova abilità.
DeepMind afferma che un braccio controllato da RT-Trajectory "ha raggiunto un tasso di successo nel compito di 63%, rispetto ai 29% di RT-2".
🔵 Può anche creare traiettorie guardando dimostrazioni umane, comprendendo schizzi e persino disegni generati da VLM.
Quando è stato testato su 41 compiti non visti nei dati di addestramento, un braccio controllato da RT-Trajectory ha ottenuto una percentuale di successo di 63%. https://t.co/rqOnzDDMDI pic.twitter.com/bdhi9W5TWi
- Google DeepMind (@GoogleDeepMind) 4 gennaio 2024
DeepMind sta mettendo questi modelli e set di dati a disposizione di altri sviluppatori: sarà interessante vedere come questi nuovi strumenti accelereranno l'integrazione dei robot dotati di intelligenza artificiale nella vita quotidiana.



