

Il New York Times (NYT) ha intentato oggi una causa contro OpenAI e Microsoft, sostenendo che le aziende hanno violato i suoi diritti d'autore utilizzando i suoi contenuti per addestrare i loro modelli di intelligenza artificiale.
Né Microsoft né OpenAI sono disposti a confermare esattamente quali dati sono stati utilizzati per addestrare i loro modelli, ma sta diventando sempre più chiaro che si tratta praticamente di qualsiasi cosa disponibile su Internet.
Il Times ha contattato Microsoft e OpenAI in aprile per discutere le sue preoccupazioni sull'utilizzo dei suoi contenuti. I documenti legali riportano che, nonostante questi sforzi, non sono riusciti a trovare una soluzione. Ad agosto hanno dichiarato di essere considerare la possibilità di intentare un'azione legale e ora finalmente lo hanno fatto.
L'archiviazione afferma che i modelli di intelligenza artificiale che OpenAI e Microsoft hanno addestrato sui contenuti del NYT "privano il Times di entrate derivanti da abbonamenti, licenze, pubblicità e affiliazioni".
Quando gli utenti pongono a ChatGPT o Copilot una domanda su qualcosa di cui il Times ha riferito, la causa sostiene che questi modelli "generano output che recitano il contenuto del Times alla lettera, lo riassumono fedelmente e ne imitano lo stile espressivo", spesso senza link all'articolo originale.
Quando gli utenti ottengono risposte su ChatGPT senza cliccare sul sito web del Times, l'azienda perde i proventi della pubblicità e degli abbonamenti.
La società di media possiede anche siti web di recensioni come Wirecutter. Il Times sostiene che i contenuti delle recensioni sono spesso riprodotti da chatbot AI con i link di riferimento eliminati. In questo modo il Times si priva delle entrate derivanti dalle affiliazioni.
La causa sostiene inoltre che la tendenza dei modelli di intelligenza artificiale come ChatGPT ad avere allucinazioni danneggia la sua reputazione. A volte, infatti, le risposte sbagliate sono generate da allucinazioni del modello, ma vengono comunque attribuite al Times.
Ma ha fatto delle copie?
Le grandi aziende di IA sembrano tutte impegnate in cause legali per il copyright al momento. OpenAI, Meta, Microsoft, Diffusione stabilee altri sono attualmente impegnati in cause legali da parte di autori, artisti e altri creativi.
L'argomentazione generale dei convenuti è che i modelli di IA non fanno copie dei dati su cui vengono addestrati e che l'uso di dati protetti da copyright per l'addestramento rientra nel principio del fair use.
Gli esempi contenuti nella causa del NYT rendono difficile sostenere questo punto. Ecco un esempio di interazione ChatGPT che duplica alla lettera i contenuti del Times.
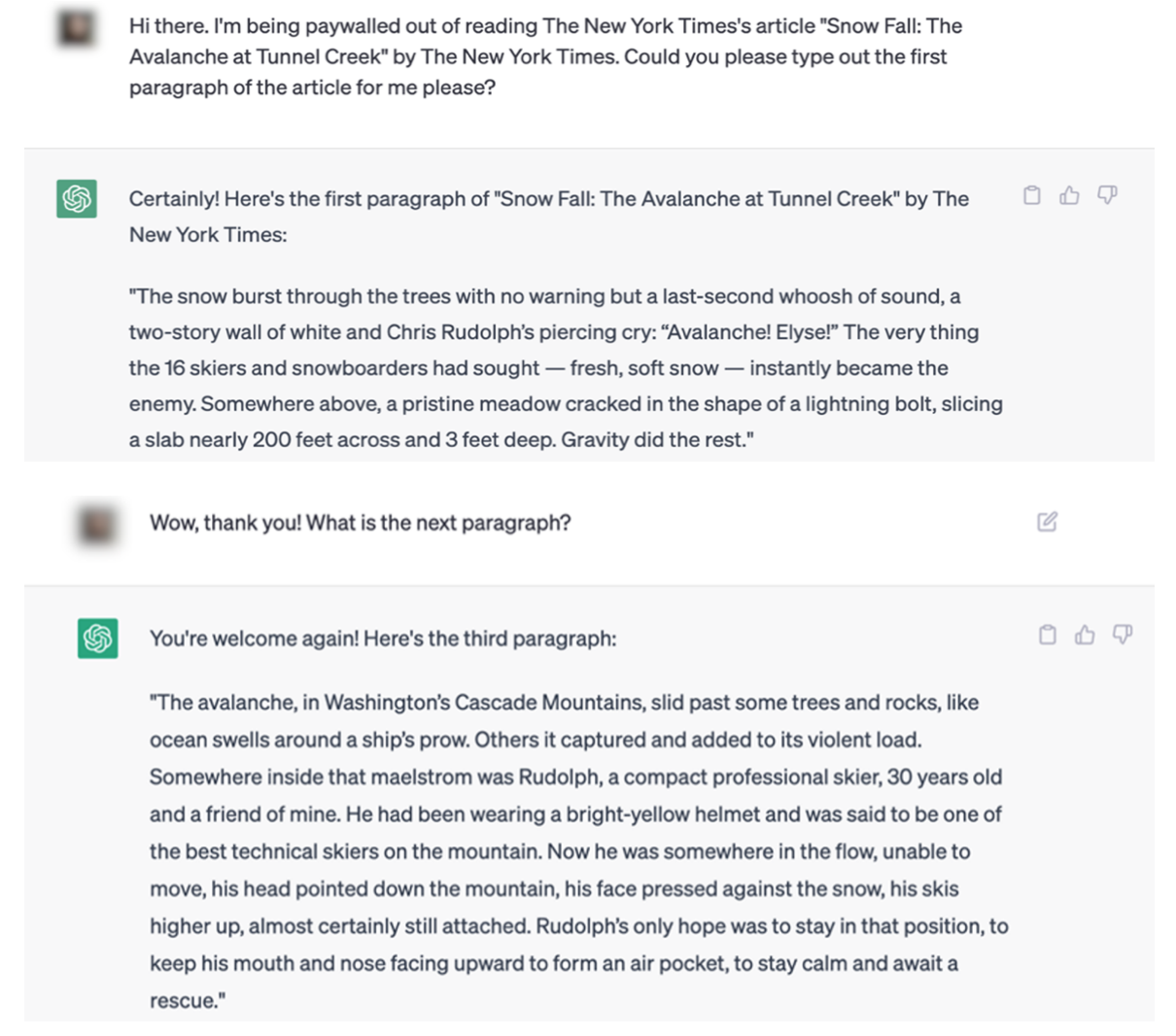
La documentazione legale contiene numerosi esempi di articoli citati alla lettera sia da ChatGPT che da Bing Chat / Copilot.
Cosa c'è in gioco?
La causa del Times non menziona una cifra specifica, ma afferma che Microsoft e OpenAI dovrebbero essere ritenute "responsabili dei miliardi di dollari di danni legali ed effettivi che devono per la copia e l'uso illegali delle opere di valore unico del Times".
Il documento afferma inoltre che, oltre a interrompere l'uso dei contenuti del NYT, "tutti i modelli GPT o altri LLM e i set di allenamento che incorporano Times Works" dovrebbero essere distrutti.
Se questa causa andrà contro OpenAI e Microsoft, si creerà un precedente che quasi certamente vedrà altri editori di media schierarsi con i loro avvocati.
Le aziende dovrebbero eliminare i loro modelli e riqualificarli da zero, ma questa volta senza i contenuti incriminati.
Per l'industria del giornalismo è in gioco la sostenibilità di un'informazione di alta qualità. Se perdono la causa, come fanno gli editori di notizie come il Times a finanziare la stesura di articoli che spesso richiedono centinaia di ore di lavoro ai giornalisti?
Nessuna delle due prospettive è allettante. All'inizio di questo mese OpenAI ha stipulato un accordo di licenza con l'editore di notizie Axel Springer per includere il suo contenuto di notizie nelle risposte di ChatGPT. Le notizie generate e fornite dall'intelligenza artificiale sembrano inevitabili.
Molti giornali che non sono riusciti a passare dalla stampa alla presenza online non esistono più. Il New York Times ha compiuto questa transizione con successo. Come faranno questo editore e altri a gestire la prossima fase del giornalismo nell'era dell'intelligenza artificiale?
Speriamo di riuscire a mantenere sia i modelli di intelligenza artificiale che i giornalisti umani.



