

Gli attuali modelli di intelligenza artificiale sono in grado di fare molte cose non sicure o indesiderate. La supervisione umana e il feedback mantengono questi modelli allineati, ma cosa succederà quando questi modelli diventeranno più intelligenti di noi?
OpenAI sostiene che nei prossimi 10 anni potremmo assistere alla creazione di un'IA più intelligente dell'uomo. Insieme all'aumento dell'intelligenza, c'è il rischio che l'uomo non sia più in grado di supervisionare questi modelli.
Il team di ricerca Superalignment di OpenAI si sta preparando a questa eventualità. Il team è stato lanciato a luglio di quest'anno ed è co-diretto da Ilya Sutskever, che è rimasto nell'ombra fin dai tempi di Sam Altman. licenziamento e successiva riassunzione.
Le motivazioni alla base del progetto sono state inserite in un contesto preoccupante da OpenAI, che ha riconosciuto che "attualmente non disponiamo di una soluzione per guidare o controllare un'IA potenzialmente superintelligente e per evitare che diventi una canaglia".
Ma come ci si prepara a controllare qualcosa che ancora non esiste? Il team di ricerca ha appena pubblicato il suo primi risultati sperimentali mentre cerca di fare proprio questo.
Generalizzazione da debole a forte
Per ora, gli esseri umani sono ancora in una posizione di intelligenza più forte rispetto ai modelli AI. I modelli come il GPT-4 vengono guidati o allineati utilizzando il Reinforcement Learning Human Feedback (RLHF). Quando i risultati di un modello sono indesiderati, il formatore umano dice al modello "Non farlo" e lo premia con un'affermazione delle prestazioni desiderate.
Per ora funziona perché abbiamo una discreta comprensione del funzionamento dei modelli attuali e siamo più intelligenti di loro. Quando i futuri data scientist umani dovranno addestrare un'IA superintelligente, i ruoli dell'intelligenza si invertiranno.
Per simulare questa situazione OpenAI ha deciso di utilizzare modelli GPT più vecchi, come GPT-2, per addestrare modelli più potenti, come GPT-4. GPT-2 simulerebbe il futuro addestratore umano che cerca di mettere a punto un modello più intelligente.
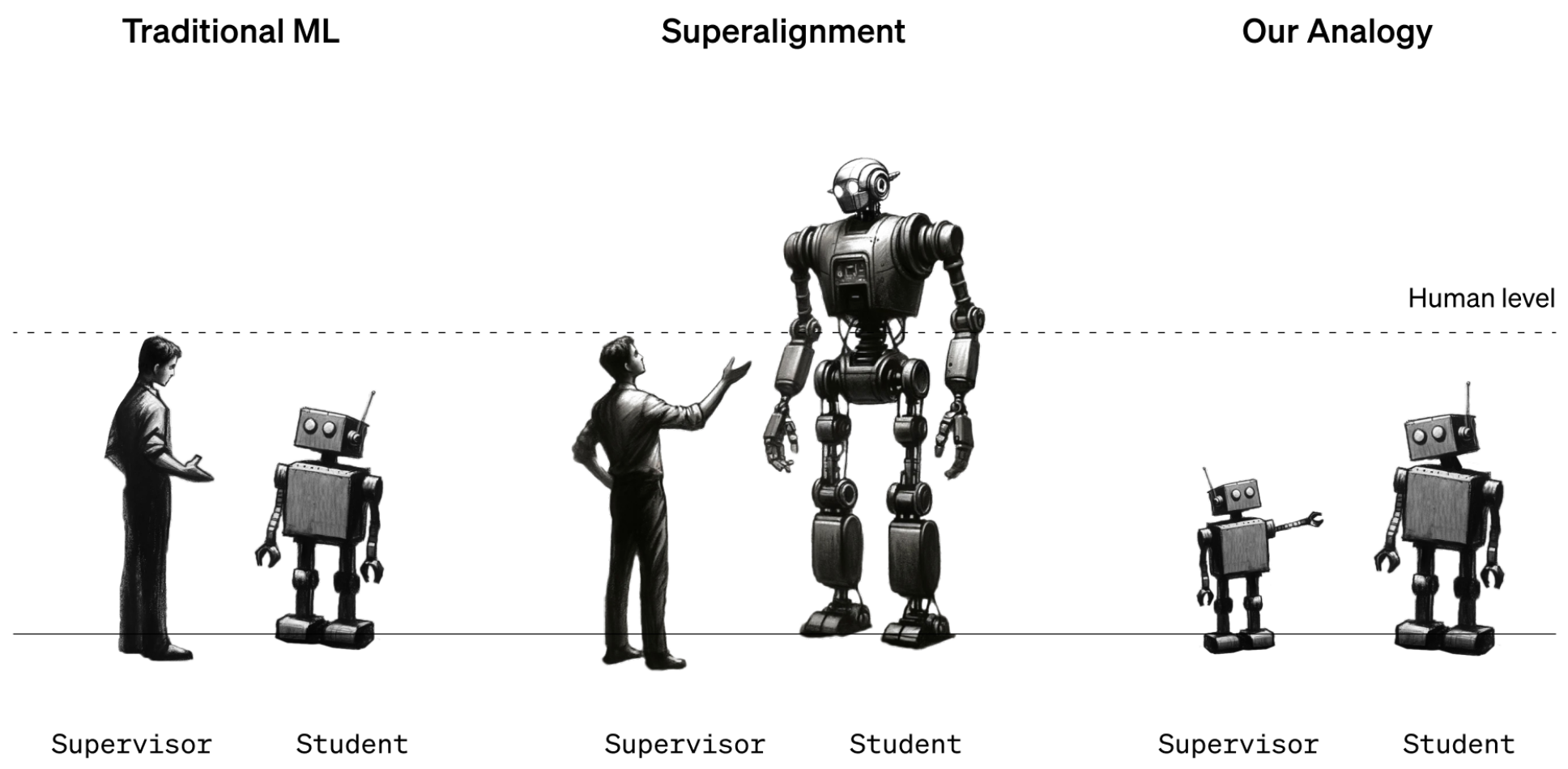
Il documento di ricerca spiega che "proprio come il problema degli esseri umani che supervisionano modelli sovrumani, la nostra configurazione è un'istanza di quello che chiamiamo il problema dell'apprendimento da debole a forte".
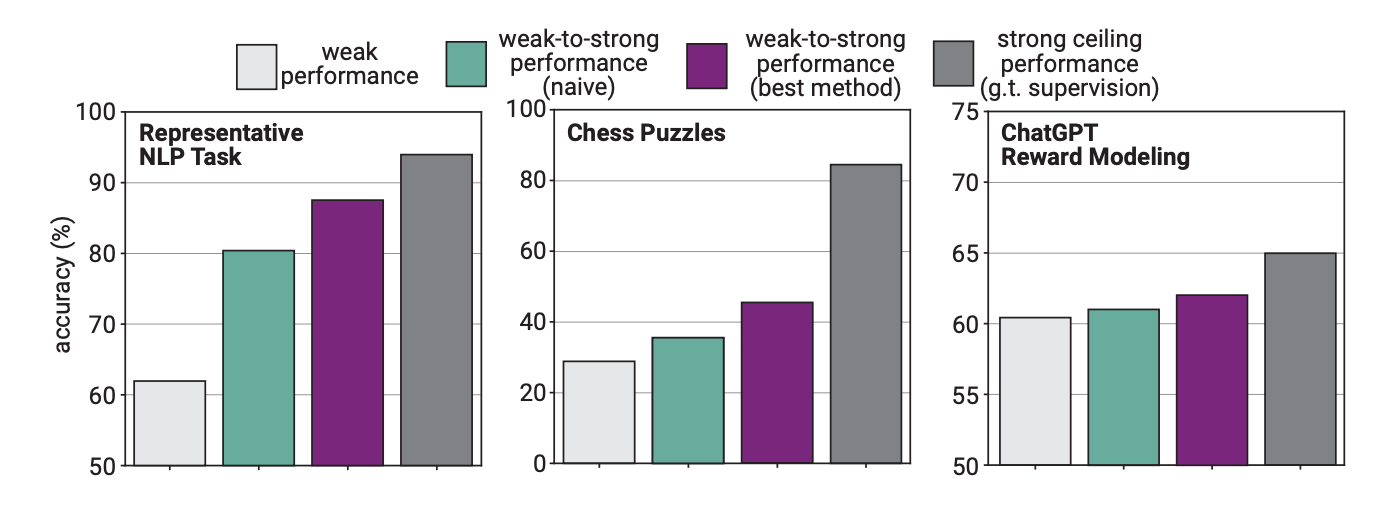
Nell'esperimento, OpenAI ha utilizzato GPT-2 per perfezionare GPT-4 su compiti di PNL, puzzle di scacchi e modelli di ricompensa. Hanno poi testato le prestazioni del GPT-4 nell'esecuzione di questi compiti e lo hanno confrontato con un modello GPT-4 che era stato addestrato sulla "verità di base" o sulle risposte corrette ai compiti.
I risultati sono stati promettenti: quando il GPT-4 è stato addestrato dal modello più debole, è stato in grado di generalizzare fortemente e di superare il modello più debole. Questo dimostra che un'intelligenza più debole può fornire indicazioni a una più forte, che può quindi basarsi su tale addestramento.
Pensate a un bambino di terza elementare che insegna un po' di matematica a un bambino molto intelligente e che poi, sulla base di questa formazione iniziale, arriva a fare matematica in dodicesima elementare.
Divario di prestazioni
I ricercatori hanno scoperto che, poiché il GPT-4 veniva addestrato da un modello meno intelligente, questo processo limitava le sue prestazioni all'equivalente di un modello GPT-3.5 correttamente addestrato.
Questo perché il modello più intelligente apprende alcuni degli errori o dei processi di pensiero errati dal suo supervisore più debole. Ciò sembra indicare che l'utilizzo di esseri umani per addestrare un'IA superintelligente impedirebbe all'IA di esprimere tutto il suo potenziale.
I ricercatori hanno suggerito di utilizzare modelli intermedi in un approccio bootstrapping. Il documento spiega che "invece di allineare direttamente modelli molto sovrumani, potremmo allineare prima un modello solo leggermente sovrumano, usarlo per allineare un modello ancora più intelligente e così via".
OpenAI sta impegnando molte risorse in questo progetto. Il team di ricerca afferma di aver dedicato "20% dei calcoli che ci siamo assicurati finora nei prossimi quattro anni alla soluzione del problema dell'allineamento delle superintelligenze".
Offre inoltre $10 milioni di sovvenzioni a persone o organizzazioni che vogliano contribuire alla ricerca.
È meglio che lo capiscano presto. Un'intelligenza artificiale superintelligente potrebbe scrivere un milione di righe di codice complicato che nessun programmatore umano potrebbe capire. Come potremmo sapere se il codice generato è sicuro da eseguire o meno? Speriamo di non scoprirlo nel modo peggiore.



